
Из этой статьи вы получите полное представление о логировании в службах приложений. Она предназначена в первую очередь для начинающих разработчиков ПО и выпускников вузов.
Логирование играет важную роль в получении информации о поведении системы, помощи в отладке и эффективном решении проблем.
Метрики и логи
Метрики и логи обеспечивают наглядность состояния системы.
Метрики предоставляют агрегированные числовые данные, которые могут быть использованы для статистического анализа, анализа тенденций и мониторинга производительности. Они предлагают обзор более высокого уровня и могут быть полезны для создания визуализаций, дашбордов и автоматизированных отчетов.
Некоторые из распространенных примеров типов метрик, которые могут быть собраны, — это время отклика и количество ошибок.
Однако в некоторых сценариях одними метриками не обойтись.
Метрики помогают обнаружить неполадки в системе. Но, используя только их, трудно (хотя и не невозможно, если метрики достаточно точны) выяснить, что именно произошло.
В каких случаях одни метрики не помогут?
- Используя только метрики, нельзя отследить, что именно произошло с каждым отдельным запросом.
- Если возникает лишь незначительная аномалия (только для нескольких запросов), нам, как и системе мониторинга, будет сложно обнаружить ее.
Именно здесь на помощь приходят логи.
Логи обеспечивают прямой подход к пониманию поведения системы. Они позволяют эффективно отлаживать, отслеживать и воспроизводить проблемы.
Что логировать?
Чтобы логи были полезными для отладки, важно уделять особое внимание их содержанию. Логи должны давать четкое представление о том, что происходит внутри приложения или системы. Ниже приведены некоторые рекомендации по эффективному ведению логов.
- Избегайте как чрезмерного, так и недостаточного логирования. И то, и другое может обернуться проблемами. Избыточное логирование приводит к превышению расходов на производительность, увеличению затрат на сериализацию и требований к инфраструктуре. А недостаточное логирование может предоставить мало информации для эффективной диагностики проблем.
- Связывайте логи с идентификаторами запросов. Каждая запись лога должна быть связана с уникальным идентификатором запроса, таким как идентификатор транзакции, идентификатор заказа, идентификатор счета, идентификатор устройства или идентификатор трассировки (UUID). Такая взаимосвязь позволяет проследить путь конкретного запроса через систему.
- Придерживайтесь согласованного формата лога. Это особенно важно при наличии в организации различных приложений или служб. Такая согласованность облегчает анализ и корреляцию логов между различными компонентами.
- Стремитесь к ясности содержания лога. Записи должны быть понятны как вам, так и потребителям вашего лога. Он должен содержать информацию, которая поможет выявить и решить проблемы. Избегайте записи любой чувствительной информации, чтобы обеспечить конфиденциальность и безопасность данных.
Примеры плохих логов:
log.info("fetching from db");
log.error("error getting from db");
s.SharedHolder.Logger.Debugf("Processing search request");
Обратите особое внимание на вышеуказанные пункты, поскольку с логированием связано множество затрат:
- стоимость ввода-вывода;
- стоимость сериализации;
- стоимость Infra для обработки и сохранения лога (сохранение, а также запрос).
Стоимость ввода-вывода: накладные расходы на производительность, связанные с чтением с внешних устройств хранения, таких как жесткие диски и твердотельные накопители (SSD), и записью на них.
Каждая запись лога требует отдельной операции записи на устройство хранения. Частые операции ввода-вывода на диск могут привести к узким местам в производительности, особенно при работе с логами большого объема.
Для снижения затрат на ввод-вывод используются различные стратегии. Вот несколько примеров.
- Буферизация: накопление записей лога в памяти и запись их на диске партиями с сокращением количества отдельных операций ввода-вывода.
- Сжатие: перед записью на диск данные лога сжимаются, чтобы уменьшить объем данных, подлежащих логированию.
- Асинхронная запись: произведение операций логирования асинхронно позволяет приложению продолжать выполнение, не дожидаясь завершения операций логирования.
Стоимость сериализации — это накладные расходы, связанные с преобразованием структур данных в формат, пригодный для хранения и передачи. При логировании сериализация обычно требуется для преобразования сложных типов данных (таких как объекты и структуры) в формат, пригодный для логирования, например текстовый или двоичный.
Стоимость сериализации может зависеть от таких факторов, как сложность структуры данных и выбранный механизм сериализации.
Некоторые широко используемые форматы сериализации включают JSON, XML и Protocol Buffers. Каждый формат сериализации имеет свои компромиссы с точки зрения удобочитаемости, размера и накладных расходов на обработку.
Чтобы минимизировать затраты на сериализацию, воспользуйтесь следующими советами.
- Оптимизируйте структуры данных. Разрабатывайте структуры данных для эффективной сериализации. Избегайте ненужной вложенности и сложных иерархий объектов, которые требуют длительной обработки при сериализации.
- Выбирайте эффективные библиотеки сериализации. Различные библиотеки сериализации могут иметь разный уровень производительности. Используйте библиотеки и фреймворки, которые обеспечивают быструю и эффективную сериализацию.
- Используйте бинарные форматы. Бинарные форматы сериализации часто приводят к меньшему объему полезной нагрузки и более быстрой сериализации/десериализации по сравнению с текстовыми форматами, такими как JSON и XML.
Уровни логов
Уровни логов помогают добавить контекст ко всем логам и предоставляют возможность классифицировать и определять приоритеты сообщений лога на основе их серьезности или важности.
- Гранулированный контроль.
- Производственный мониторинг.
ERROR (ОШИБКА): указывает на критическую ошибку, которая нарушает работу системы и требует ручного вмешательства. Подобные ошибки чреваты неожиданными ситуациями, с которыми нельзя справиться.
WARN (ПРЕДУПРЕЖДЕНИЕ): указывает на состояние, которое может подлежать автокоррекции или требует внимания, но не является критическим. Означает неожиданные сценарии, предполагающие тщательную обработку.
INFO (ИНФОРМИРОВАНИЕ): предоставляет информацию о потоке системы. Как правило, не включается в процесс разработки, если того не требуют цели аудита.
DEBUG (ОТЛАДКА): включает подробные логи, необходимые для отладки проблем в производственной среде. Предполагает выборочную работу по устранению неполадок.
Если вы сомневаетесь в выборе уровня лога, выбирайте уровень с более высоким приоритетом.

Уровни логов: контрольные вопросы
Каждый вопрос имеет 4 возможных ответа: DEBUG, INFO, WARN и ERROR.
- Приложение запускается и инициализирует компоненты. Какой уровень лога вы бы использовали для индикации успешной инициализации каждого компонента?
- Во время выполнения функции возникло неожиданное, но устранимое состояние. Какой уровень лога следует использовать для получения информации об этом состоянии?
- Возникла ошибка, которая не позволяет приложению работать правильно. Какой уровень лога вы бы использовали, чтобы указать на эту критическую ошибку?
- Возникла исключительная ситуация, требующая немедленного внимания. Какой уровень лога вы бы использовали для указания этой серьезной ошибки?
- Приложение столкнулось с неожиданным вводом, но смогло восстановиться без какого-либо ущерба для функциональности. Какой уровень лога вы бы использовали для предоставления информации об этом инциденте?
- Был получен запрос на аутентификацию с неверными учетными данными. Какой уровень лога вы бы использовали, чтобы указать на этот сбой аутентификации?
- Не удалось установить соединение с базой данных. Какой уровень лога следует использовать, чтобы указать на этот сбой подключения?
- Пользователь выполнил действие, которое не рекомендуется, но не обязательно приводит к ошибке. Какой уровень лога следует использовать, чтобы предоставить информацию об этом действии?
- Во время выполнения критической функции было поймано неожиданное исключение. Какой уровень лога следует использовать для указания этого исключительного условия?
- Запланированное задание или работа успешно завершена. Какой уровень лога вы бы использовали для указания успешного завершения?
Ответы в конце статьи.
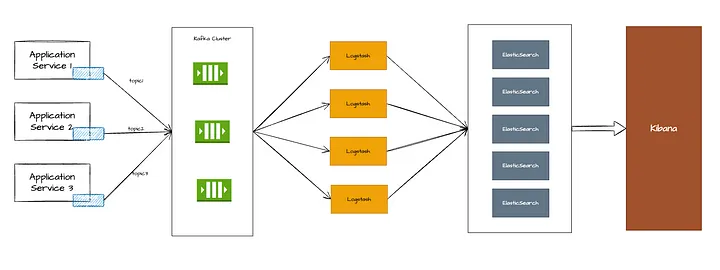
ELK-стек
ELK-стек (ELK — Elasticsearch, Logstash, Kibana — применение, установка, настройка) — это популярное решение для ведения логов и их анализа.
Filebeat
Filebeat — это легкий отправитель логов с открытым исходным кодом. Устанавливаемый на каждом сервисе агент filebeat следит за изменениями файлов в папке. В случае какого-либо изменения файла он отправляет сообщение в Kafka.
Необходимо настроить вводы filebeat для мониторинга нужной папки (папок) лога, а также тему, в которую нужно отправлять лог.
Рекомендуется использовать разные темы Kafka для каждого сервиса, чтобы справиться с разной скоростью генерации логов и предотвратить недостаток загрузки.
- Скорость генерации логов различна для каждого сервиса. Поэтому с помощью гранулирования по темам можно определить количество разделов, коэффициент репликации и т.д.
- Если по какой-либо причине один сервис начнет генерировать огромное количество логов, другие сервисы могут испытывать дефицит загрузки.
Пример конфигурации Filebeat:
filebeat.inputs:
- type: log
enabled: true
paths:
- /home/ubuntu/projects/**/logs/*.log
fields_under_root: false
tail_files: true
exclude_files: ['^*newrelic']
multiline.type: pattern
multiline.pattern: '(?i)^[[:space:]]+(at|\.{3})[[:space:]]+\b|^Caused by:|^com\.|^net\.|^org\.|^io\.|^id\.'
multiline.negate: false
multiline.match: after
output.kafka:
hosts: [""]
topic: "logs-%{[fields.servicename]}"
processors:
- script:
lang: javascript
source: >
function process(ev) {
var field;
field = ev.Get("log.file.path");
var serviceName = (field.split("/")[4] + "").toLowerCase();
ev.Put("fields.servicename", serviceName);
return ev;
};
Kafka
Kafka — это распределенная потоковая платформа, которая выступает в качестве брокера сообщений между Filebeat и Logstash.
Logstash
Logstash отвечает за прием, обработку и обогащение логов.
Logstash снабжен различными плагинами, которые позволяют ему передавать обработанные логи. Обычно в качестве части ELK выходной информацией является поисковой индекс Elastic, откуда ее может прочитать Kibana.
У нас есть несколько logstash-экземпляров, которые входят в одну группу потребителей, и каждый logstash-экземпляр прослушивает все темы Kafka. Это делается для того, чтобы все сообщения равномерно распределялись между потребителями и ни один logstash не оставался без дела.
- Все логи парсятся в logstash, чтобы узнать, можно ли получить какие-либо полезные поля, такие как уровень лога, threadId, traceId, className и т. д.
- Logstash использует фильтр Grok, чтобы определить, соответствует ли лог шаблону, и отфильтровать поля.
У Logstash есть 3 фазы.
- Ввод. Здесь настраиваем вводы для logstash. В нашем случае вводом является Kafka, поэтому нам нужно указать серверы загрузки Kafka и темы.
- Фильтр. На этом этапе выполняем операцию grok match (использование фильтра для определения, соответствует ли лог шаблону), добавляем/удаляем поля.
- Вывод. Здесь настраиваем вывод logstash, которым в нашем случае является Elasticsearch.
input {
kafka{
codec => json
bootstrap_servers => ""
topics_pattern => ".*"
decorate_events => true
consumer_threads => 128
}
}
filter {
grok {
match => [ "message", "\[%{LOGLEVEL:level}\] %{TIMESTAMP_ISO8601:logTime} \[%{DATA:threadId}\] %{JAVACLASS:className} "]
}
mutate {
add_field => {
"topic" => "%{[@metadata][kafka][topic]}"
}
add_field => {
"logpath" => "%{[log][file][path]}"
}
remove_field => ["input", "agent", "ecs", "log", "event", "uuid","tags"]
}
uuid {
target => "uuid"
}
}
output {
elasticsearch {
hosts => []
index => "%{[topic]}-%{+YYYY.MM.dd}"
pool_max_per_route => 100
}
}
Имя индекса для Elasticsearch: topicName — YYYY.MM.dd.
Elasticsearch
Elasticsearch — это распределенный поисковый и аналитический механизм, который хранит и индексирует логи.
Kibana
Kibana — это пользовательский веб-интерфейс для визуализации и изучения логов. Рекомендации по конфигурации Kibana:
- Подключите Kibana к Elasticsearch, чтобы обеспечить визуализацию логов и выполнение запросов.
- Создавайте пользовательские дашборды и визуализации, чтобы получить представление о поведении системы.
- Настройте шаблоны индексов, чтобы определить, как Kibana интерпретирует поля данных лога.
Заключение
Ведение логов является неотъемлемой частью служб приложений и позволяет получить ценные сведения о поведении системы. Метрики и логи дополняют друг друга, а хорошо продуманная стратегия ведения логов обеспечивает эффективную отладку, решение проблем и мониторинг системы.
Следуя лучшим практикам и используя инструменты анализа логов, такие как ELK Stack, разработчики и операторы могут получить глубокое представление о своих системах и создать более надежные и производительные приложения.
Ответы на контрольные вопросы
INFO, WARNING, ERROR, ERROR, WARNING, WARNING, ERROR, WARNING, ERROR, INFO.
Читайте также:
- Профессиональный подход к ведению логов
- Всё, что вы хотели знать об отладке в IntelliJ IDEA
- Автоматизированные тесты - качественно и непременно эффективно!
Читайте нас в Telegram, VK и Дзен
Перевод статьи Aman Arora: Logging: The ‘Root’ of All Debugging Adventures





