
В последние месяцы, благодаря выпуску Mixtral, стала популярной архитектура MoE (Mixture of Experts — коллектив экспертов). Эта архитектура предлагает интересный компромисс: более высокую производительность за счет повышенного использования VRAM. В то время как Mixtral и другие архитектуры MoE предварительно обучаются с нуля, недавно появился другой метод создания MoE. Благодаря библиотеке MergeKit — детищу платформы Arcee — появился новый способ создания MoE путем объединения нескольких предварительно обученных моделей. Такие модели часто называют frankenMoE (или MoErge), чтобы отличать их от предварительно обученных MoE.
В этой статье будет подробно рассказано о том, как устроена архитектура MoE и как она работает. Вы также узнаете, как создать собственную модель frankenMoE с помощью MergeKit и сможете оценить ее по нескольким бенчмаркам. Код проекта доступен на Google Colab в обертке под названием LazyMergeKit.
MoE: общие сведения
Mixture of Experts — это архитектура, разработанная для повышения эффективности и производительности. Она использует несколько специализированных подсетей, известных как “эксперты”. В отличие от плотных моделей, в которых задействована вся сеть, в MoE активируются только эксперты, работающие с определенными входными данными. Это позволяет ускорить обучение и повысить эффективность выводов.
В основе модели MoE лежат два компонента:
- Разреженные слои MoE (Sparse MoE Layers). Являются заменой плотных слоев сетей прямого распространения (feed-forward network, FFN) в архитектуре трансформера. Каждый слой MoE содержит несколько экспертов, и только подмножество этих экспертов задействуется для заданного входного сигнала.
- Сетевой шлюз, или маршрутизатор (Gate Network, или Router). Этот компонент определяет, какие токены обрабатываются теми или иными экспертами. Таким образом обеспечивается обработка каждой части входных данных наиболее подходящим экспертом (экспертами).
В следующем примере показано, как блок Mistral-7B трансформируется в блок MoE с разреженным слоем MoE (сети прямого распространения FFN 1, FFN 2 и FFN 3) и маршрутизатором. Этот пример представляет MoE с тремя экспертами, два из которых задействованы в настоящее время (FFN 1 и FFN 3).
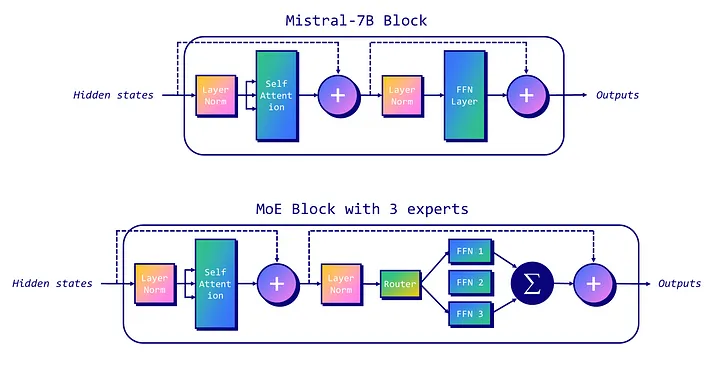
Модели MoE имеют свои сложности, особенно в плане тонкой настройки и требований к памяти. Процесс тонкой настройки может быть затруднен из-за сложности модели, при этом необходимо сбалансировать использование экспертов в процессе обучения, чтобы правильно обучить gating-веса и выбрать наиболее релевантные из них. Что касается памяти, несмотря на то что в процессе вывода используется лишь часть всех параметров, вся модель, включая всех экспертов, должна быть загружена в память, что требует большой емкости VRAM.
Если говорить более конкретно, работу MoE определяют два основных параметра:
- Количество экспертов (
num_local_experts) — общее количество экспертов в архитектуре (например, 8 для Mixtral). Чем больше экспертов, тем выше потребление VRAM. - Количество экспертов на токен (
num_experts_per_tok) — количество экспертов, задействованных для каждого токена и каждого слоя (например, 2 для Mixtral). Существует компромисс между большим числом экспертов на токен для точности (но с уменьшающейся отдачей) и малым числом для быстрого обучения и вывода.
Исторически сложилось так, что MoE не дотягивают до эффективности плотных моделей. Однако выпуск Mixtral-8x7B в декабре 2023 года изменил ситуацию: новая модель показала впечатляющую для своего размера производительность. Кроме того, по слухам, GPT-4 также является MoE, что вполне логично, поскольку запуск и обучение этой модели для OpenAI обошлись гораздо дешевле, чем обычно обходятся запуск и обучение плотной модели. В дополнение к этим недавно вышедшим превосходным MoE, появился новый способ создания MoE с помощью MergeKit. В результате была получена модель frankenMoE, также называемая MoErge.
Сравнение типичной модели MoE и frankenMoE
Основное различие между типичной моделью MoE и frankenMoE заключается в способе обучения. В случае типичной MoE эксперты и маршрутизатор обучаются совместно. В случае frankenMoE совершенствуются существующие модели, после чего инициализируется маршрутизатор.
Другими словами, при обучении frankenMoE копируются веса слоев нормы и самовнимания из базовой модели, а затем копируются веса слоев FFN, найденных в каждом эксперте. Следовательно, кроме FFN, все остальные параметры являются общими. Это объясняет, почему Mixtral-8x7B с восемью экспертами имеет не 8*7 = 56 млрд параметров, а около 45 млрд. Именно поэтому использование двух экспертов на токен дает скорость вывода (FLOPs) плотной модели 12 млрд, а не 14 млрд.
FrankenMoE позволяет выбрать наиболее подходящих экспертов и провести их адекватную инициализацию. В настоящее время MergeKit реализует три метода инициализации маршрутизаторов:
- Случайный (Random). Случайные веса. Требует осторожного подхода, так как каждый раз могут выбираться одни и те же эксперты (необходима дополнительная тонкая настройка или
num_local_experts = num_experts_per_tok, а это означает, что вам не нужна маршрутизация). - Экономичный эмбеддинг (Cheap embed). Использует необработанные эмбеддинги входных токенов напрямую и предполагает одну и ту же трансформацию на всех слоях. Этот метод не требует больших вычислительных затрат и подходит для выполнения на менее мощном оборудовании.
- Скрытый (Hidden). Создает скрытые представления списка положительных и отрицательных промптов, извлекая их из последнего слоя LLM. Они усредняются и нормализуются для инициализации маршрутизации.
Как можно догадаться, “скрытая” инициализация является наиболее эффективной для правильной маршрутизации токенов к наиболее релевантным экспертам. В следующем разделе вы узнаете, как создать собственную модель frankenMoE, используя этот метод.
Создание frankenMoE
Чтобы создать frankenMoE, нужно выбрать n экспертов. В данном случае будем ориентироваться на Mistral-7B, учитывая популярность этой модели и относительно небольшой размер. Однако 8 экспертов, как в Mixtral, — это довольно много, поскольку нужно уместить их всех в памяти. Для эффективности в этом примере будем использовать только 4 эксперта, причем двое из них будут задействованы для каждого токена и каждого слоя. В этом случае получим модель с количеством параметров 24,2 млрд (вместо 4*7 = 28 млрд параметров).
Наша цель — создать универсальную модель, которая может делать практически все: писать рассказы, объяснять статьи, писать код на Python и т. д. Разобьем это требование на четыре задачи и выберем лучшего эксперта для каждой из них. Вот как можно это сделать:
- Модель для чата (Chat model). Модель общего назначения, применяемая в большинстве взаимодействий. Будем использовать mlabonne/AlphaMonarch-7B, которая идеально удовлетворяет нашим требованиям.
- Модель для написания кода (Code model). Модель, способная генерировать качественный код. Выберем beowolx/CodeNinja-1.0-OpenChat-7B, которая наиболее эффективна по сравнению с другими.
- Математическая модель (Math model). Математика сложна для LLM, поэтому нам нужна модель, специализирующаяся на математических вычислениях. Благодаря высоким показателям MMLU и GMS8K, mlabonne/NeuralDaredevil-7B отлично подойдет для этой цели.
- Ролевая модель (Role-play model). Цель этой модели — писать качественные рассказы и беседы. Выберем модель SanjiWatsuki/Kunoichi-DPO-v2–7B из-за ее хорошей репутации и высокой оценки MT-Bench (8,51 против 8,30 у Mixtral).
Теперь, определив необходимых экспертов, разработаем конфигурацию YAML, необходимую MergeKit для создания frankenMoE. В данном случае используем ветку mixtral библиотеки MergeKit. Более подробную информацию по подготовке конфигурации ищите на этой странице. Вот наша версия:
base_model: mlabonne/AlphaMonarch-7B
experts:
- source_model: mlabonne/AlphaMonarch-7B
positive_prompts:
- "chat"
- "assistant"
- "tell me"
- "explain"
- "I want"
- source_model: beowolx/CodeNinja-1.0-OpenChat-7B
positive_prompts:
- "code"
- "python"
- "javascript"
- "programming"
- "algorithm"
- source_model: SanjiWatsuki/Kunoichi-DPO-v2-7B
positive_prompts:
- "storywriting"
- "write"
- "scene"
- "story"
- "character"
- source_model: mlabonne/NeuralDaredevil-7B
positive_prompts:
- "reason"
- "math"
- "mathematics"
- "solve"
- "count"
Каждый эксперт получает по 5 основных положительных промптов. При желании можете проявить больше изобретательности и написать целые предложения. Оптимальная стратегия заключается в использовании реальных промптов, которые должны активировать определенного эксперта. Можете также добавить отрицательные промпты для обратного эффекта.
Как только все будет готово, сохраните конфигурацию как config.yaml. В ту же папку загрузите и установите библиотеку MergeKit (ветку mixtral).
git clone -b mixtral https://github.com/arcee-ai/mergekit.git
cd mergekit && pip install -e .
pip install -U transformers
Если на вашем компьютере достаточно оперативной памяти (примерно 24–32 ГБ ОЗУ), выполните следующую команду:
mergekit-moe config.yaml merge --copy-tokenizer
Если у вас недостаточно оперативной памяти, разделите модели следующим образом (это займет больше времени):
mergekit-moe config.yaml merge --copy-tokenizer --allow-crimes --out-shard-size 1B --lazy-unpickle
Эта команда автоматически загружает экспертов и создает frankenMoE в каталоге merge. Для шлюзового режима hidden также можете использовать опции --load-in-4bit и --load-in-8bit, чтобы вычислять скрытые состояния с меньшей точностью.
Кроме того, можете скопировать свою конфигурацию в LazyMergekit, обертку, которая упрощает объединение моделей. В этом ноутбуке Colab введите название своей модели, выберите ветвь mixtral, укажите имя пользователя/токен Hugging Face и запустите ячейки. После создания FrankenMoE модель также будет загружена на Hugging Face Hub вместе с карточкой модели в хорошем формате.
Назовем модель Beyonder-4x7B-v3 и создадим ее GGUF-версии с помощью AutoGGUF. При отсутствии возможности запустить GGUF-версии на своем локальном компьютере, можете делать выводы с помощью этого ноутбука Golab.
Судить о возможностях Beyonder-4x7B-v3 позволят ее оценки по трем бенчмаркам: Nous, EQ-Bench и Open LLM Leaderboard. Архитектура нашей модели не позволяет ей преуспевать по меркам традиционных бенчмарков, где не предусматривается тестирование моделей для написания кода и ролевых моделей. Тем не менее благодаря сильным экспертам общего назначения она показывает отличные результаты.
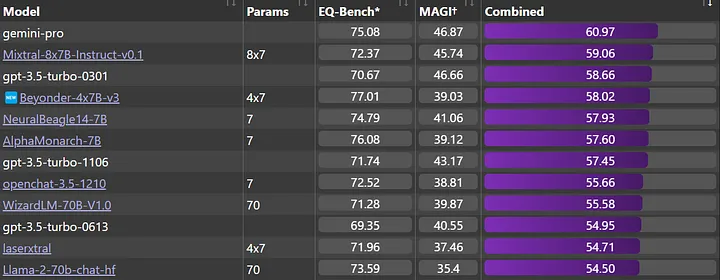
Nous. Beyonder-4x7B-v3 — одна из лучших моделей в наборе средств тестирования Nous (оценка проводилась с помощью LLM AutoEval), значительно превосходящая модель v2. Посмотреть всю таблицу лидеров можно здесь.
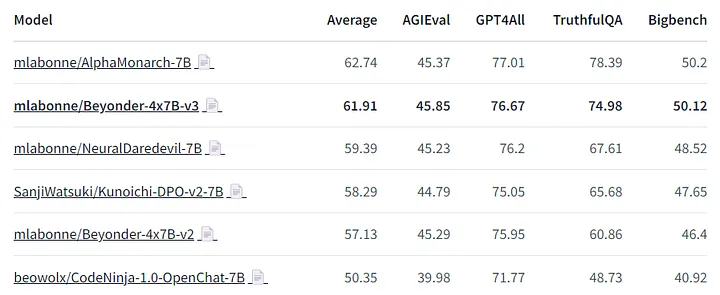
EQ-Bench. Beyonder также стала лучшей моделью 4x7B в таблице лидеров EQ-Bench, опередив старые версии ChatGPT и Llama-2–70b-chat. Она очень близка к Mixtral-8x7B-Instruct-v0.1 и Gemini Pro, которые (предположительно) являются гораздо более мощными моделями.
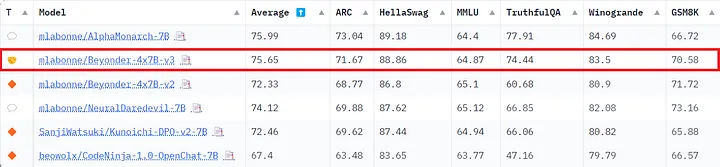
Open LLM Leaderboard. Наконец, эта модель также показала достойные результаты на Open LLM Leaderboard, значительно превосходя модель v2.
В дополнение к этим количественным оценкам рекомендую проверить результаты модели более качественным способом, используя версию GGUF на LM Studio. Обычный метод тестирования таких моделей — собрать приватный набор вопросов и проверить их результаты. Используя эту стратегию, я обнаружил, что Beyonder-4x7B-v3 довольно устойчива к изменениям в пользовательских и системных промптах по сравнению с другими моделями, включая AlphaMonarch-7B. Это очень здорово, поскольку повышает полезность модели в целом.
FrankenMoE — многообещающий, но все еще экспериментальный подход. Компромиссы, такие как более высокая потребность в VRAM и низкая скорость вывода, не позволяют увидеть его преимущество перед более простыми методами объединения нейросетей, такими как SLERP и DARE TIES. В частности, при использовании frankenMoE только с двумя экспертами, она может работать не так хорошо, как при простом объединении двух моделей. Тем не менее frankenMoE отлично сохраняет знания, что может привести к созданию более сильных моделей, как было продемонстрировано в случае Beyonder-4x7B-v3. При наличии подходящего аппаратного оборудования указанные недостатки можно эффективно устранить.
Заключение
В этой статье была представлена архитектура Mixture of Experts. В отличие от традиционных MoE, которые обучаются с нуля, MergeKit помогает создание MoE путем объединения экспертов, предлагая инновационный подход к улучшению производительности и эффективности модели. Процесс создания frankenMoE с помощью MergeKit описан подробно с выделением практических шагов, связанных с выбором и объединением различных экспертов для создания MoE высокого качества.
Попробуйте создать собственную модель frankenMoE с помощью LazyMergeKit: выберите несколько моделей, разработайте свою конфигурацию на основе Beyonder и запустите ноутбук для создания своей модели!
Читайте также:
- 8 базовых понятий статистики для науки о данных
- 7 признаков того, что вы стали продвинутым пользователем Sklearn
- Использование Snowflake для прогнозирования эскалации в колл-центре
Читайте нас в Telegram, VK и Дзен
Перевод статьи Maxime Labonne: Create Mixtures of Experts with MergeKit


 на Go")


