
ChatGPT привлек внимание всего мира к искусственному интеллекту и его потенциалу.
Ключевым фактором популярности ChatGPT стал его чат-интерфейс, благодаря которому возможности ИИ оказались более доступными, чем когда-либо прежде.
Ажиотаж вокруг “парадигмы чат-ботов”, хотя и привел к новому витку интереса к ИИ, оставил практически незамеченным еще одно ключевое нововведение.
Большие языковые модели (LLM) привнесли значительные инновации в текстовой эмбеддинг. Углубимся в эту область машинного обучения, а также рассмотрим простые, но крайне важные случаи применения текстового эмбеддинга.
Текстовые эмбеддинги
Текстовые эмбеддинги (векторные представления текстов) переводят слова в числа. Однако это не просто числа. Это числа, которые передают смысл исходного текста.
Это важно, потому что цифры (гораздо) легче анализировать, чем слова.
Например, если вы находитесь на корпоративном мероприятии и хотите узнать среднестатистический рост людей в зале, вы можете измерить рост каждого и вычислить среднее значение с помощью Microsoft Excel. Однако если вы хотите узнать должность, наиболее распространенную среди собравшихся людей, то никакая функция в Excel вам не поможет.
Именно здесь на выручку приходят эмбеддинги текстов. Эффективный способ перевода текста в числа обеспечивает доступ к огромному набору статистических методов и техник машинного обучения для исследования текстовых данных.
Объяснение эмбеддингов текста с помощью визуализации
Лучше понять, что значит “переводить текст в числа”, позволит наглядный пример.
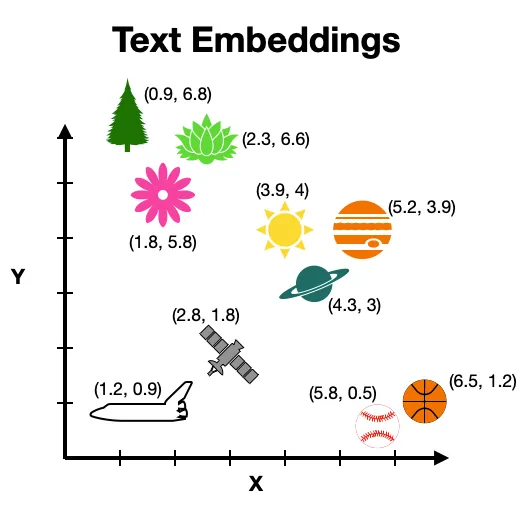
Рассмотрим следующий текстовой набор: дерево, цветок лотоса, маргаритка, солнце, Сатурн, Юпитер, спутник, космический шаттл, баскетбол, бейсбол.
Хотя этот набор слов может показаться случайным, некоторые из приведенных понятий более схожи по смыслу, чем другие. Можно передать эти сходства (и различия) следующим образом.

Приведенная выше визуализация интуитивно упорядочивает понятия. Схожие предметы (например, дерево, маргаритка и цветок лотоса) расположены близко друг к другу, а несхожие (например, дерево и бейсбольный мяч) — далеко друг от друга.
Числа вписываются в эту картину, поскольку можно присвоить координаты каждому слову, исходя из его местоположения на приведенном выше графике. Эти координаты (т. е. числа) используются для анализа текста.
Откуда взялись эмбеддинги?
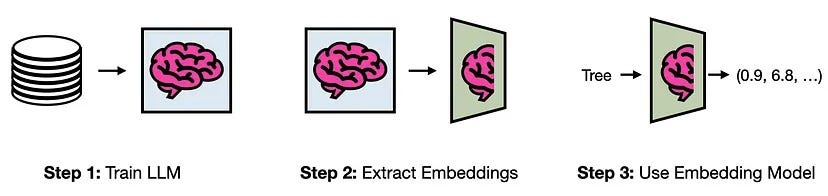
Идея перевода текста в числа, чтобы сделать текст более машиночитаемым, не нова. Исследователи занимаются этим с первых дней развития вычислительной техники (примерно с 1950 года).
Хотя за прошедшие годы было придумано бесчисленное множество способов цифрового представления текста, самые современные из них создаются на основе LLM.
Их эффективность объясняется тем, что в процессе обучения LLM тренируются на (очень) хороших числовых представлениях текстов. Слои, генерирующие эти представления, можно выделить из модели и использовать отдельно. Результатом этого процесса является модель текстового эмбеддинга.
Почему нельзя просто использовать ChatGPT?
Прежде чем перейти к примерам использования текстового эмбеддинга, отвечу на вопрос, который может у вас возникнуть: “Зачем мне знать о текстовых эмбеддингах? Разве нельзя просто создать пользовательский ChatGPT для анализа текстов?”.
Конечно, можно использовать такие техники, как RAG (генерация с дополненным поиском) и Fine-tuning (дообучение модели), чтобы создать агента ИИ под конкретный набор задач. Однако эти системы находятся еще в самом начале своего развития, что делает создание надежного агента ИИ (то есть не прототипа) дорогой и нетривиальной инженерной задачей (связанной с большими вычислительными затратами, рисками безопасности LLM, непредсказуемыми ответами и галлюцинациями).
С другой стороны, текстовые эмбеддинги, существующие уже несколько десятилетий, легки и предсказуемы. Таким образом, создание систем ИИ на основе эмбеддингов гораздо проще и дешевле, чем создание агента ИИ (при этом они сохраняют значительную часть смысла, если не большую).
Пример использования № 1: классификация текстов
Перейдем к случаям использования текстовых эмбеддингов для решения реальных задач.
Сначала рассмотрим классификацию текстов. Она заключается в присвоении метки конкретному тексту. Например, можно пометить электронное письмо как спам или не спам, заявку на кредит как высокорискованную или низкорискованную, предупреждение системы безопасности как реальное или ложное.
В нашем примере будут использованы текстовые эмбеддинги для классификации резюме как “Data Scientist” (дата-сайентист) и “Not Data Scientist” (не дата-сайентист). Подобная задача может быть актуальна для рекрутеров, пытающихся сориентироваться в потоке кандидатов на должность дата-сайентиста.
Чтобы избежать проблем с конфиденциальностью, создадим синтетический набор данных резюме с помощью gpt-3.5-turbo. Хотя использование синтетических данных требует некоторого скепсиса в отношении результатов, этот пример станет поучительной демонстрацией того, как использовать текстовые эмбеддинги для классификации.
Код примера и данные находятся в свободном доступе в репозитории GitHub.
Импорт
Начнем с импорта зависимостей. В этом примере будем использовать модель текстового эмбеддинга от OpenAI, которая требует ключа API. Мой API-ключ хранится в отдельном файле sk.py.
import openai
from sk import my_sk
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
Теперь считываем синтетический обучающий набор данных в виде датафрейма Pandas. Данные получаем из файла .csv с двумя столбцами, состоящими из текста резюме и связанной с ним должности.
df_resume = pd.read_csv('resumes/resumes_train.csv')
Генерация эмбеддингов
Чтобы преобразовать резюме в эмбеддинги, выполним простой вызов API к API OpenAI. Для этого используем функцию, представленную ниже.
def generate_embeddings(text, my_sk):
# настройка учетных данных
client = openai.OpenAI(api_key = my_sk)
# API-вызов
response = client.embeddings.create(
input=text,
model="text-embedding-3-small"
)
# возврат текстового эмбеддинга
return response.data
Применим эту функцию к каждому резюме в датафрейме и сохраним результат в списке.
# генерация эмбеддингов
text_embeddings = generate_embeddings(df_resume['resume'], my_sk)
# извлечение эмбеддингов
text_embedding_list =
[text_embeddings[i].embedding for i in range(len(text_embeddings))]
Сохранение эмбеддингов в датафрейме
Создадим новый датафрейм для хранения текстовых эмбеддингов и целевой переменной для обучения модели.
# определение имен столбцов датафрейма
column_names =
["embedding_" + str(i) for i in range(len(text_embedding_list[0]))]
# сохранение текстовых эмбеддингов в датафрейме
df_train = pd.DataFrame(text_embedding_list, columns=column_names)
# создание целевой переменной
df_train['is_data_scientist'] = df_resume['role']=="Data Scientist"
Обучение модели
Подготовив обучающие данные, приступим к обучению модели классификации в одной строке кода. При этом будем использовать классификатор Random Forest (RF).
# Разделение переменных на предикторы и цель
X = df_train.iloc[:,:-1]
y = df_train.iloc[:,-1]
# обучение rf-модели
clf = RandomForestClassifier(max_depth=2, random_state=0).fit(X, y)
Оценка модели
Чтобы быстро получить представление о производительности модели, можно оценить ее на обучающих данных. Вычислим среднюю точность и ROC-кривую (Receiver Operating Characteristic curve — кривую операционных характеристик модели), то есть AUC (Area Under Curve — площадь под кривой ошибок).
# Точность модели для обучающих данных
print(clf.score(X,y))
# Значение AUC для обучающих данных
print(roc_auc_score(y, clf.predict_proba(X)[:,1]))
# Вывод
# 1
# 1
Значения точности и AUC, равные 1, свидетельствуют об идеальной работе на обучающем наборе данных, что вызывает подозрения. Поэтому стоит оценить модель на незнакомом ей тестовом наборе данных.
# Импорт тестовых данных
df_resume = pd.read_csv('resumes/resumes_test.csv')
# Генерация эмбеддингов
text_embedding_list = generate_embeddings(df_resume['resume'], my_sk)
text_embedding_list =
[text_embedding_list[i].embedding for i in range(len(text_embedding_list))]
# Сохранение текстовых эмбеддингов в датафрейме
df_test = pd.DataFrame(text_embedding_list, columns=column_names)
# Создание целевой переменной
df_test['is_data_scientist'] = df_resume['role']=="Data Scientist"
# Определение предикторов и цели
X_test = df_test.iloc[:,:-1]
y_test = df_test.iloc[:,-1]
# Точность модели для тестовых данных
print(clf.score(X_test,y_test))
# Значение AUC для тестовых данных
print(roc_auc_score(y_test, clf.predict_proba(X_test)[:,1]))
# Вывод
# 0.98
# 0.9983333333333333
Решение проблемы переобучения
Несмотря на хорошие результаты при применении тестовых данных, модель все же может оказаться переобученной по двум причинам.
- Во-первых, у нас 1537 предикторов и всего 100 резюме для прогнозирования, поэтому модели не составило труда “запомнить” каждый пример в обучающих данных.
- Во-вторых, обучающие и тестовые данные были сгенерированы из gpt-3.5-turbo похожим образом. Таким образом, они имеют много общих характеристик, что делает задачу классификации проще, чем при использовании реальных данных.
Есть много способов для преодоления проблемы переобучения. Можно, к примеру, уменьшить количество предикторов с помощью ранжирования их важности, или увеличить минимальное количество образцов в “листовом” узле, или использовать более простую технику классификации, например логистическую регрессию. Однако, если цель — применить модель в практических условиях, то лучшим вариантом будет сбор большего количества данных и использование реальных резюме.
Пример использования № 2: семантический поиск
Теперь рассмотрим семантический поиск. В отличие от поиска по ключевым словам, семантический поиск генерирует результаты, основываясь на смысле запроса пользователя, а не на конкретных словах или фразах.
Например, поиск по ключевым словам может не дать ожидаемых результатов по запросу “Мне нужен человек для создания инфраструктуры данных”, поскольку в нем нет конкретного упоминания о должности человека, который занимается созданием инфраструктуры данных (т. е. инженера по данным). Однако для семантического поиска это не проблема, так как с ним можно подобрать кандидатов необходимой квалификации, например “экспертов в области моделирования, преобразования и хранения данных”.
Далее будем использовать текстовые эмбеддинги для обеспечения такого типа поиска по тому же набору данных, что и в предыдущем примере. Образец кода (снова) будет доступен в репозитории GitHub.
Импорт
Начнем с импорта зависимостей и синтетического набора данных.
import numpy as np
import pandas as pd
from sentence_transformers import SentenceTransformer
from sklearn.decomposition import PCA
from sklearn.metrics import DistanceMetric
import matplotlib.pyplot as plt
import matplotlib as mpl
df_resume = pd.read_csv('resumes/resumes_train.csv')
# Перемена метки для random role ("other")
df_resume['role'][df_resume['role'].iloc[-1] == df_resume['role']] = "Other"
Генерация эмбеддингов
Теперь сгенерируем текстовые эмбеддинги. Вместо того чтобы использовать API OpenAI, воспользуемся моделью из Python-библиотеки Sentence Transformers с открытым исходным кодом. Эта модель была специально настроена для семантического поиска.
# Импорт предварительно обученной модели (полный список: https://www.sbert.net/docs/pretrained_models.html)
model = SentenceTransformer("all-MiniLM-L6-v2")
# Кодировка текста
embedding_arr = model.encode(df_resume['resume'])
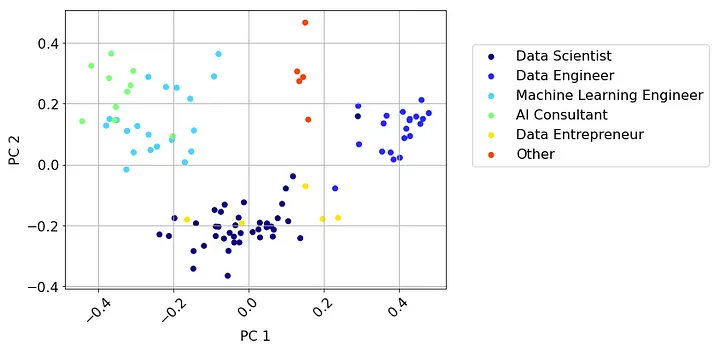
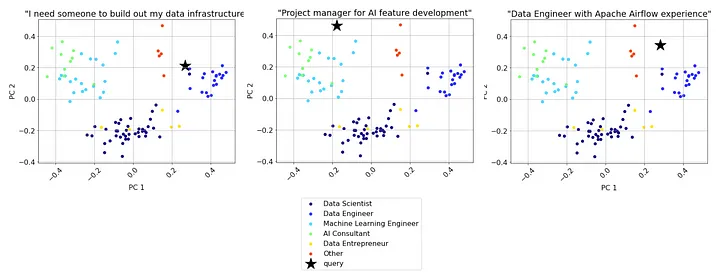
Чтобы увидеть различные резюме в наборе данных и их расположение относительно друг друга в пространстве понятий, можно использовать PCA (Principal Component Analysis — анализ основных компонентов) для уменьшения размерности эмбеддинговых векторов и визуализировать данные на 2D-графике (код на GitHub).
Из этого представления видно, что резюме на определенную должность имеют тенденцию скапливаться (группироваться).
Выполнение семантического поиска
Чтобы выполнить семантический поиск по этим резюме, можно взять запрос пользователя, преобразовать его в текстовой эмбеддинг и затем вернуть ближайшие резюме в эмбеддинг-пространстве. Вот как это выглядит в коде:
# Определение запроса
query = "I need someone to build out my data infrastructure"
# Кодировка запроса
query_embedding = model.encode(query)
# Определение метрики расстояния (другие варианты: manhattan, chebyshev)
dist = DistanceMetric.get_metric('euclidean')
# Вычисление парных расстояний между эмбеддингом запроса и эмбеддингами резюме
dist_arr = dist.pairwise(embedding_arr, query_embedding.reshape(1, -1)).flatten()
# Сортировка результатов
idist_arr_sorted = np.argsort(dist_arr)
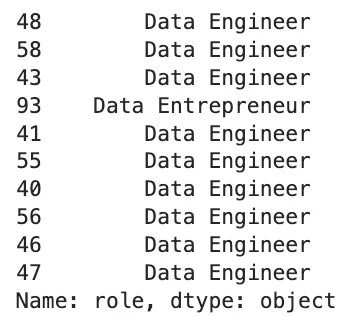
Просматривая топ-10 результатов, можно заметить: почти все они представляют должность “инженер по данным”, что является хорошим знаком.
# Вывод ролей 10 наиболее близких к запросу резюме в эмбеддинг-пространстве
print(df_resume['role'].iloc[idist_arr_sorted[:10]])
Взглянем на резюме из топовых результатов поиска.
# Вывод резюме, наиболее близких к запросу в эмбеддинг-пространстве
print(df_resume['resume'].iloc[idist_arr_sorted[0]])
**John Doe**
/**Джон Доу**/
---
**Summary:**
Highly skilled and experienced Data Engineer with a strong background in
designing, implementing, and maintaining data pipelines. Proficient in data
modeling, ETL processes, and data warehousing. Adept at working with large
datasets and optimizing data workflows to improve efficiency.
**Резюме**
Высококвалифицированный и опытный инженер по обработке данных
с большим опытом работы в области проектирования, внедрения и поддержки
конвейеров данных. Хорошо разбирается в моделировании данных,
ETL-процессах и хранении данных. Умеет работать с большими наборами данных и оптимизировать
рабочие процессы для повышения эффективности.
---
**Professional Experience:**
- **Senior Data Engineer**
XYZ Tech, Anytown, USA
June 2018 - Present
- Designed and developed scalable data pipelines to handle terabytes of data daily.
- Optimized ETL processes to improve data quality and processing time by 30%.
- Collaborated with cross-functional teams to implement data architecture best practices.
**Профессиональный опыт:**
- **Старший инженер по обработке данных**
XYZ Tech, город такой-то, США
Июнь 2018 - настоящее время
- Проектирование и разработка масштабируемых конвейеров данных для ежедневной обработки терабайтов данных.
- Оптимизировал ETL-процессы для повышения качества данных и ускорения времени обработки на 30 %.
- Сотрудничал с межфункциональными командами для внедрения лучших практик архитектуры данных.
- **Data Engineer**
ABC Solutions, Sometown, USA
January 2015 - May 2018
- Built and maintained data pipelines for real-time data processing.
- Developed data models and implemented data governance policies.
- Worked on data integration projects to streamline data access for business users.
- **Инженер по обработке данных**
ABC Solutions, город такой-то, США
Январь 2015 - май 2018
- Создавал и поддерживал конвейеры данных для обработки данных в режиме реального времени.
- Разрабатывал модели данных и внедрял политики управления данными.
- Работал над проектами по интеграции данных, чтобы упростить доступ к данным для бизнес-пользователей.
---
**Education:**
- **Master of Science in Computer Science**
University of Technology, Cityville, USA
Graduated: 2014
- **Bachelor of Science in Computer Engineering**
State College, Hometown, USA
Graduated: 2012
**Образование:**
- **Магистр в области компьютерных наук**
Технологический университет, город такой-то, США
Окончил: 2014
- **Бакалавр в области компьютерной инженерии**
Государственный колледж, город такой-то, США
Окончил: 2012
---
**Technical Skills:**
- Programming: Python, SQL, Java
- Big Data Technologies: Hadoop, Spark, Kafka
- Databases: MySQL, PostgreSQL, MongoDB
- Data Warehousing: Amazon Redshift, Snowflake
- ETL Tools: Apache NiFi, Talend
- Data Visualization: Tableau, Power BI
**Технические навыки:**
- Программирование: Python, SQL, Java
- Технологии больших данных: Hadoop, Spark, Kafka
- Базы данных: MySQL, PostgreSQL, MongoDB
- Хранилища данных: Amazon Redshift, Snowflake
- ETL-инструменты: Apache NiFi, Talend
- Визуализация данных: Tableau, Power BI
---
**Certifications:**
- Certified Data Management Professional (CDMP)
- AWS Certified Big Data - Specialty
**Сертификаты:**
- Сертифицированный специалист по управлению данными (CDMP)
- Специализация: AWS Certified Big Data
---
**Awards and Honors:**
- Employee of the Month - XYZ Tech (July 2020)
- Outstanding Achievement in Data Engineering - ABC Solutions (2017)
**Награды и признания:**
- Сотрудник месяца - XYZ Tech (июль 2020 г.)
- Выдающиеся достижения в области инженерии данных - ABC Solutions (2017)
Хотя это выдуманное резюме, кандидат, скорее всего, обладает всеми необходимыми навыками и опытом, чтобы удовлетворить потребности пользователя.
Еще один способ визуально оценить результаты поиска — 2D-графики. Вот как они выглядят для нескольких запросов (см. заголовки графиков).
Оптимизация поиска
Хотя в этом простом примере поиска мы успешно справились с задачей подбора конкретных кандидатов по заданному запросу, он не идеален. Один из его недостатков проявляется в тех случаях, когда запрос пользователя включает определенный навык. Например, в запросе “инженер по данным с опытом работы с Apache Airflow” только 1 из 5 топовых результатов включает опыт работы с Airflow.
Это убеждает в том, семантический поиск не во всех ситуациях лучше поиска по ключевым словам. У каждого из них есть свои сильные и слабые стороны.
Таким образом, надежная поисковая система будет использовать так называемый гибридный поиск, который сочетает в себе лучшее из обоих методов. Хотя существует множество способов создания такой системы, простой подход заключается в применении поиска по ключевым словам для фильтрации результатов, за которым следует семантический поиск.
Две дополнительные стратегии оптимизации поиска — использование модели повторного ранжирования и тонкая настройка текстовых эмбеддингов (дообучение модели).
Модель повторного ранжирования (реранкер) — это модель, которая напрямую сравнивает два фрагмента текста. Другими словами, вместо того чтобы вычислять сходство между фрагментами текста с помощью метрики расстояния в эмбеддинг-пространстве, такая модель вычисляет оценку сходства напрямую.
Модели повторого ранжирования обычно используются для уточнения результатов поиска. Например, можно получить 25 лучших результатов с помощью семантического поиска, а затем сократить их до 5 наиболее оптимальных с помощью реранкера.
Тонкая настройка текстовых эмбеддингов заключается в адаптации модели эмбеддинга к конкретной области. Это мощный подход, поскольку большинство моделей эмбеддинга основаны на широкой коллекции текстов и знаний. Таким образом, они не могут оптимально организовать понятия для конкретной отрасли, например дата-сайенс и ИИ.
Заключение
Хотя, казалось бы, все сосредоточены на потенциале агентов и помощников ИИ, недавние инновации в моделях текстового эмбеддинга открыли бесчисленные возможности для простых, но высокоэффективных сценариев использования в машинном обучении.
Мы рассмотрели два широко распространенных случая использования: классификацию текстов и семантический поиск. Текстовой эмбеддинг позволяет использовать более простые и дешевые LLM-методы, сохраняя при этом большую часть смысла.
Читайте также:
- Использование LLM в реальном мире
- Создание чат-бота с помощью LLM и LangChain
- Создание модели Mixture of Experts (MoE) с помощью MergeKit
Читайте нас в Telegram, VK и Дзен
Перевод статьи Shaw Talebi: Text Embeddings, Classification, and Semantic Search





