
В Databricks я помогаю крупным предприятиям розничной торговли развертывать и масштабировать конвейеры данных и машинного обучения. В этой статье я поделюсь 8 самыми важными лайфхаками по использованию Spark, освоенными мной в процессе работы.
Надеюсь, вы обладаете базовыми практическими знаниями о Spark и его структуре, хотя статья должна быть доступна для специалистов всех уровней.
Итак, погрузимся в тему!
Краткий обзор Spark
Вкратце рассмотрим, как работает Spark.
Spark — это движок для обработки больших данных. Он конвертирует код Python/Java/Scala/R/SQL в высокооптимизированный набор преобразований.
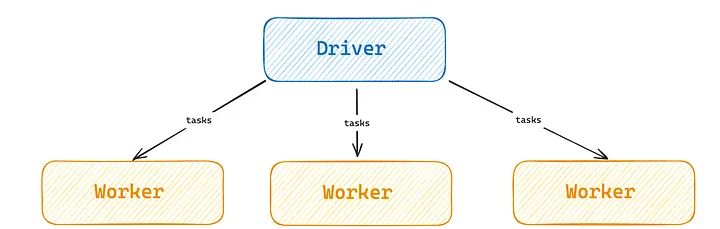
На самом низком уровне Spark создает задачи, которые представляют собой распараллеливаемые преобразования разделов данных. Затем эти задачи распределяются с узла-драйвера на узлы-воркеры, которые задействуют свои ядра CPU для выполнения преобразований. Распределяя задачи между потенциально большим количеством узлов-воркеров, Spark позволяет выполнять горизонтальное масштабирование и тем самым поддерживать сложные конвейеры данных, что было бы невозможно на одной машине.
Эти советы должны пригодиться как специалистам среднего уровня, так и тем, кто только начинает осваивать Spark.
1. Представьте, что Spark — это продуктовый магазин
Spark — сложная система. Легче понять его структуру поможет довольно удачная аналогия, заимствованная из теории массового обслуживания: Spark — это продуктовый магазин.
Если говорить о компонентах распределенных вычислений в Spark, то можно выделить три основных компонента.
- Разделы данных: подмножества строк данных (в продуктовом магазине это продукты).
- Задачи Spark: низкоуровневые преобразования, выполняемые в отношении раздела данных (в продуктовом магазине это покупатели).
- Ядра: часть процессора (процессоров), выполняющая параллельную работу (в продуктовом магазине это кассиры).
Теперь с помощью этих понятий я расскажу об основных принципах работы со Spark.
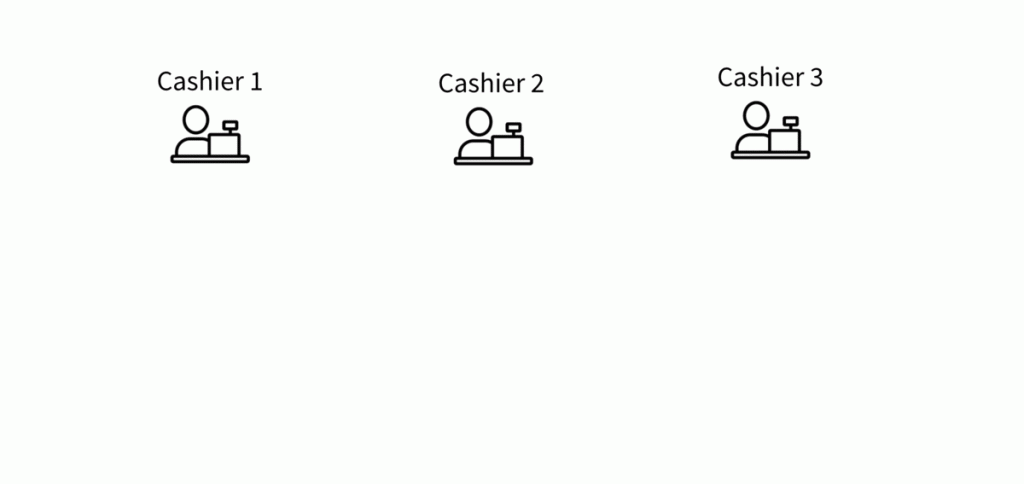
Как показано на рис. 3, кассиры (ядра) могут одновременно обрабатывать только одного покупателя (задачу). Кроме того, у некоторых покупателей много продуктов (количество строк раздела), как показано на примере первого покупателя у кассира 2. Из этих простых наблюдений следует:
- Чем больше кассиров (ядер), тем больше клиентов (задач) вы можете обрабатывать параллельно. Это и есть горизонтальное/вертикальное масштабирование.
- Если у вас недостаточно клиентов (задач), чтобы загрузить работой кассиров (ядра), вы будете платить за то, что кассир сидит без дела. Речь идет об автомасштабировании, размере кластера и размере раздела.
- Если покупатели (задачи) имеют разное количество продуктов (количество строк раздела), вы столкнетесь с неравномерной загрузкой кассиров. Это и есть искажение данных.
- Чем лучше кассиры (ядра), тем быстрее они могут обрабатывать одного покупателя (задачу). Для этого стоит модернизировать процессор.
Учитывая, что аналогия взята из теории массового обслуживания — области, непосредственно связанной с распределенными вычислениями, — она весьма убедительна!
Используйте этот пример для отладки, коммуникации и разработки Spark.
2. Собирайте данные в память один раз
Самая распространенная ошибка новичков в работе со Spark — непонимание роли ленивой оценки.
Ленивая оценка означает, что никакие преобразования данных не будут выполняться до тех пор, пока вы не вызовете коллекцию в памяти. Методы, вызывающие коллекцию, включают (но не ограничиваются этими примерами):
- .collect(): занести DataFrame в память в виде Python-списка.
- .show(): вывести первые
nстрок DataFrame. - .count(): получить количество строк в DataFrame.
- .first(): получить первую строку DataFrame.
Самым распространенным неправильным методом создания коллекции является использование .count() во всей программе. Каждый раз, когда вы вызываете коллекцию, все предшествующие преобразования вычисляются заново, поэтому если у вас есть 5 вызовов .count(), программа будет асимптотически работать в 5 раз дольше.
Spark работает с ленивой оценкой! Конвейеры должны иметь единый поток от источника(ов) к цели(ям).
3. Придерживайтесь SLA, но не забывайте о тайм-аутах
Удивительно частая проблема, возникающая при работе с крупными организациями, заключается в том, что они не видят общей картины и поэтому оптимизируют конвейеры неэффективным образом.
Вот как следует оптимизировать конвейеры для большинства случаев использования.
- Определите, насколько выгоден вам проект. Проще говоря, подумайте, что вы на самом деле получите от оптимизации конвейера. Если рассчитываете увеличить время работы на 20%, а конвейер обходится в 100 долларов, стоит ли тратить чрезвычайно затратные усилия инженера данных, чтобы сэкономить 20 долларов на каждом запуске? Возможно, да. А может, и нет.
- Ищите в коде “торчащие уши”. Согласившись на выполнение проекта, проверьте, нет ли в коде очевидных недостатков. Примерами могут служить ненадлежащее использование ленивой оценки, ненужные преобразования и неправильный порядок преобразований.
- Добейтесь выполнения задания в рамках SLA, используя вычисления. Убедившись, что код относительно эффективен, просто задействуйте вычисления для решения задачи, чтобы 1) соблюсти требования SLA и 2) собрать статистические данные от пользовательского интерфейса Spark.
- Вовремя остановитесь. Если вы максимально используете вычисления и затраты не являются вопиющими, выполните необходимые оптимизации, а затем остановитесь. Ваше время стоит дорого. Не тратьте его на экономию нескольких долларов, если можете получить тысячи долларов за другие проекты.
- Выполните глубокое погружение. И наконец, если вам действительно нужно глубоко погрузиться в тему, потому что затраты неприемлемы, тогда засучите рукава, оптимизируйте данные, пишите код и делайте вычисления.
Прелесть этого фреймворка в том, что шаги 1–4 требуют лишь беглого ознакомления со Spark и очень быстро выполняются — иногда можно собрать информацию по шагам 1–4 в процессе 30-минутного телефонного разговора. Фреймворк также гарантирует возможность прекращения работы после достижения надлежащего уровня эффективности. Наконец, если понадобится шаг 5, можно делегировать его тем членам команды, которые лучше всего владеют Spark.
Обнаружение способов избежать чрезмерной оптимизации конвейера позволяет экономить драгоценные часы разработки.
4. Избегайте сброса данных на диск
Сброс данных на диск — самая распространенная причина медленного выполнения задач Spark.
Тут все достаточно просто. Spark предназначен для обработки данных в памяти. Если у вас недостаточно памяти, Spark попытается записать лишние данные на диск, чтобы предотвратить сбой процесса. Это называется “сброс на диск”.
Запись на диск и чтение с него происходят медленно, поэтому их следует избегать. Вот распространенные и простые методы минимизации риска сброса на диск.
- Обрабатывайте меньше данных на задачу. Это можно сделать, изменив количество разделов с помощью spark.shuffle.partitions (настройки количества разделов, используемых при перемешивании данных для объединения или агрегирования) или repartition (повторного разделения).
- Увеличьте соотношение “оперативная память/ядра” в компьютере.
Если хотите, чтобы задача выполнялась за оптимальное время, предотвратите сброс данных на диск.
5. Используйте синтаксис SQL
Независимо от того, какой язык вы используете — Scala, Java, Python, SQL или R, — Spark всегда будет задействовать “под капотом” одни и те же преобразования. Поэтому выбирайте подходящий язык для своей задачи.
SQL — наименее многословный из всех поддерживаемых Spark языков для многих операций! Пара рекомендаций:
- Если добавляете или изменяете столбец, используйте selectExpr или expr, особенно в паре с f-строками Python.
- Если нужен сложный SQL, создайте временные представления, а затем используйте spark.sql().
Вот два небольших примера:
# Переименование и преобразование столбцов с помощью SQL
df = df.selectExpr([f"{c}::int as {c}_abc" for c in df.columns])
# Переименование и преобразование столбцов с помощью нативного Spark
for c in df.columns:
df = df.withColumn(f"{c}_abc", F.col(c).cast("int")).drop(c)
# Оконные функции с SQL
df.withColumn("running_total", expr(
"sum(value) over (order by id rows between unbounded preceding and current row)"
))
#Оконные функции с нативным Spark
windowSpec = Window.orderBy("id").rowsBetween(Window.unboundedPreceding, Window.currentRow)
df_with_running_total_native = df.withColumn("running_total", F.sum("value").over(windowSpec))
Используйте SQL.
6. Применяйте глобальные фильтры
Нужно прочитывать множество файлов с данными, хранящихся в сложном каталоге? Если да, используйте чрезвычайно мощные опции чтения в Spark.
Впервые столкнувшись с этой проблемой, я переписал os.walk, чтобы он взаимодействовал с моим облачным провайдером, где хранились данные. Когда я с гордостью показал этот метод своему партнеру по проекту, тот просто сказал: “Посмотри на мой монитор”, и познакомил меня с глобальными фильтрами.
# Прочтение всех parquet-файлов в каталоге (и подкаталогах)
df = spark.read.load(
"examples/src/main/resources/dir1",
format="parquet",
pathGlobFilter="*.parquet"
)
Когда вместо пользовательского os.walk я применил приведенный выше глобальный фильтр, операция занесения данных ускорилась более чем в 10 раз.
Spark обладает мощными параметрами. Проверяйте, существует ли необходимая вам функциональность, прежде чем создавать ее специально.
7. Использование Reduce с DataFrame.Union
Циклы почти всегда пагубно влияют на производительность Spark.
Дело в том, что у Spark есть две основные фазы: планирование и выполнение. На этапе планирования Spark создает направленный ациклический граф (DAG), который показывает, как будут выполняться указанные вами преобразования. Фаза планирования является относительно дорогостоящей и иногда может занимать несколько секунд, поэтому нужно вызывать ее как можно реже.
Рассмотрим пример использования, в котором необходимо просмотреть множество DataFrame’ов, выполнить дорогостоящие преобразования, а затем добавить их в таблицу.
Начнем с того, что существует встроенная поддержка почти всех итеративных сценариев использования, включая определяемые пользователем функции Pandas, оконные функции и джойны. Если же вам действительно нужен цикл, вот как можно вызвать только фазу планирования и таким образом получить все преобразования в единственном DAG.
import functools
from pyspark.sql import DataFrame
paths = get_file_paths()
# Плохо: цикл for
for path in paths:
df = spark.read.load(path)
df = fancy_transformations(df)
df.write.mode("append").saveAsTable("xyz")
# Хорошо: functools.reduce
lazily_evaluated_reads = [spark.read.load(path) for path in paths]
lazily_evaluted_transforms = [fancy_transformations(df) for df in lazily_evaluated_reads]
unioned_df = functools.reduce(DataFrame.union, lazily_evaluted_transforms)
unioned_df.write.mode("append").saveAsTable("xyz")
В первом решении используется цикл for для итерации по путям, выполнения причудливых преобразований и последующего добавления в интересующую дельта-таблицу. Во втором случае мы храним список лениво оцененных DataFrame’ов, применяем к ним преобразования, затем сокращаем с помощью объединения, выполняя единственно фазу планирования Spark и запись.
Можно увидеть разницу в архитектуре на бэкенде посредством пользовательского интерфейса Spark.
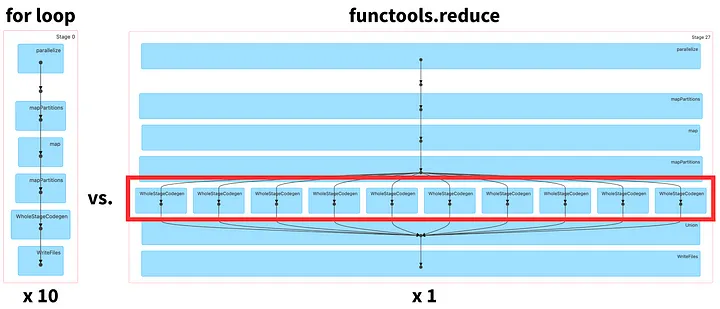
На рис.5 DAG слева, соответствующий циклу for, будет состоять из 10 этапов. Однако у DAG справа, соответствующего циклу functools.reduce, будет один этап и, следовательно, он может легче обрабатываться параллельно.
В случае необходимости прочтения 400 уникальных дельта-таблиц и последующего добавления в дельта-таблицу, этот метод оказался в 6 раз быстрее цикла for.
Подходите креативно к созданию единственного DAG Spark.
8. Используйте ChatGPT
Речь идет не о попадании в мейнстрим.
Spark — это хорошо зарекомендовавший себя и, соответственно, хорошо документированный программный продукт. Большие языковые модели (LLM), в частности GPT-4, хорошо справляются с трансформацией сложной информации в удобоваримые и лаконичные объяснения. С момента выхода GPT-4 я не разработал ни одного сложного проекта на Spark, в котором не опирался бы на GPT-4.
Тем не менее, если говорить об очевидном (надеюсь), будьте осторожны, используя LLM. Все, что вы отправляете в модель с закрытым исходным кодом, может стать обучающими данными для материнской организации. Убедитесь в том, что не отправляете ничего конфиденциального. Кроме того, следите, чтобы результаты GPT не противоречили законодательству.
При правильном использовании большие языковые модели меняют ситуацию с обучением и развитием Spark. Это обходится в 20 долларов в месяц.
Читайте также:
- Об Apache Spark - интересно и со вкусом!
- Хватит использовать Pandas, пора переходить на Spark + Scala!
- Apache Spark: гайд для новичков
Читайте нас в Telegram, VK и Дзен
Перевод статьи Michael Berk: 1.5 Years of Spark Knowledge in 8 Tips





