
В быстро меняющейся сфере технологий генеративный ИИ выступает в качестве революционной силы, которая совершенствует подходы разработчиков и инженеров ИИ/МО к решению сложных задач и внедрению инноваций. В этой статье мы погрузимся в мир генеративного ИИ, чтобы ознакомиться с фреймворками и инструментами, необходимыми каждому разработчику.
LangChain

Разработанная Харрисоном Чейзом, платформа с открытым исходным кодом LangChain дебютировала в октябре 2022 года. Она предназначена для создания мощных приложений на основе LLM (больших языковых моделей), таких как чат-боты ChatGPT и различные специализированные приложения.
LangChain предоставляет инженерам по данным всеобъемлющий набор инструментов для использования LLM в различных приложениях, включая чат-боты, автоматизированные ответно-вопросные системы, создание обзоров информационных текстов и другие.
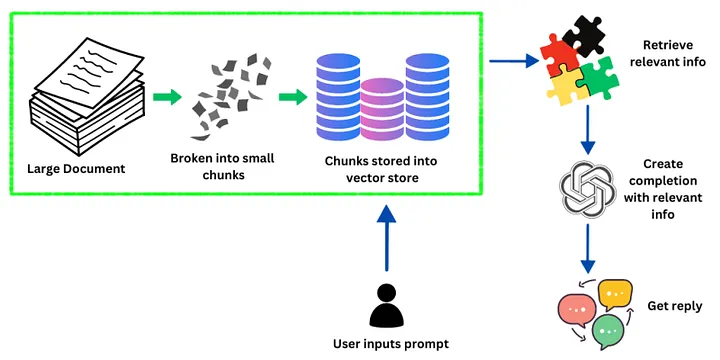
На приведенном выше изображении показано, как LangChain обрабатывает информацию и отвечает на запросы пользователя. Изначально в систему поступает большой документ, содержащий огромное количество данных. Затем этот документ разбивается на более мелкие управляемые фрагменты.
Далее эти фрагменты встраиваются в векторы — процесс, преобразующий данные в формат, который может быть быстро и эффективно получен системой. Эти векторы хранятся в хранилище векторов — базе данных, оптимизированной для работы с векторными данными.
Когда пользователь вводит в систему запрос, LangChain запрашивает это векторное хранилище, чтобы найти информацию, которая точно соответствует запросу пользователя или имеет к нему отношение. Система задействует большие LLM для понимания контекста и намерений пользователя, что позволяет извлекать соответствующую информацию из векторного хранилища.
После того как необходимая информация найдена, LLM использует ее для создания или завершения ответа, который точно соответствует запросу. На последнем этапе пользователь получает конкретный ответ, который является результатом работы системы по обработке данных и генерации языка.
SingleStore Notebook

Инновационный инструмент SingleStore Notebook, основанный на Jupyter Notebook, значительно улучшает процесс исследования и анализа данных, особенно при работе с распределенной SQL-базой данных SingleStore. Благодаря интеграции с Jupyter Notebook, он стал привычной мощной платформой для дата-сайентистов и других специалистов. Вот краткое описание его ключевых особенностей и преимуществ.
- Нативная поддержка SingleStore SQL. Эта функция упрощает процесс запроса к распределенной базе данных SingleStore SQL, который инициируется непосредственно из ноутбука. Таким образом, отпадает необходимость в сложных строках подключения и предоставляется более безопасный и простой метод исследования и анализа данных.
- Взаимодействие SQL и Python. Эта особенность обеспечивает бесшовную интеграцию между SQL-запросами и Python-кодом. Пользователи могут выполнять SQL-запросы в ноутбуке и использовать результаты непосредственно в Python-датафреймах, и наоборот. Такая совместимость необходима для эффективного манипулирования данными и их анализа.
- Совместные рабочие процессы. Ноутбук поддерживает совместное использование и редактирование, позволяя членам команды взаимодействовать при работе над проектами по анализу данных. Эта функция повышает способность команды координировать и эффективно объединять свои знания и опыт.
- Интерактивная визуализация данных. Благодаря поддержке популярных библиотек визуализации данных, таких как Matplotlib и Plotly, SingleStore Notebook позволяет пользователям создавать интерактивные и информативные графики и диаграммы прямо в среде ноутбука. Такая возможность очень важна для дата-сайентистов, которым необходимо наглядно представлять свои результаты.
- Простота использования и обучающие ресурсы. Платформа удобна в использовании, оснащена шаблонами и документацией, которые помогают новичкам быстро освоиться. Эти ресурсы неоценимы для овладения основами работы с ноутбуком и выполнения сложных задач анализа данных.
- Будущие усовершенствования и интеграция. Команда SingleStore стремится постоянно совершенствовать ноутбуки, планируя внедрить такие функции, как импорт/экспорт, автозаполнение кода и галерея ноутбуков для различных сценариев. Ожидается и появление бот-возможностей, которые могут облегчить создание SQL- и Python-кода в SingleStoreDB.
- Упрощение интеграции Python-кода. В будущем планируется упростить прототипирование кода Python в ноутбуках и интегрировать этот код в базу данных в виде хранимых процедур, что повысит общую эффективность и функциональность системы.
SingleStore Notebook — это мощный инструмент для дата-сайентистов, сочетающий в себе универсальность Jupyter Notebook и специальные улучшения для работы с SQL-базой данных SingleStore. Ориентация на простоту использования, совместную работу и интерактивную визуализацию данных, а также обещание будущих улучшений делают его ценным ресурсом среди членов сообществ по науке о данных и машинному обучению.
Просмотрите бесплатные туториалы, описывающие функционал SingleStore Notebook.
Тут есть очень интересные руководства, в том числе по распознаванию образов, сопоставлению изображений, созданию LLM-приложений, способных видеть, слышать, говорить и т. д. И все это можно попробовать бесплатно.
LlamaIndex

LlamaIndex — усовершенствованная система оркестровки, разработанная для расширения возможностей LLM, таких как GPT-4. Несмотря эффективность LLM, обученных на обширных публичных наборах данных, им часто не хватает средств для взаимодействия с приватными или специфическими для конкретной области данными. LlamaIndex устраняет этот пробел, предлагая структурированный способ получения, организации и использования различных источников данных, включая API, базы данных и PDF-файлы.
Индексируя эти данные в форматах, оптимизированных для LLM, LlamaIndex облегчает составление запросов на естественном языке, позволяя пользователям легко взаимодействовать с приватными данными без необходимости переобучения моделей. Этот универсальный фреймворк подходит как для новичков, использующих высокоуровневый API для быстрой настройки, так и для экспертов, стремящихся к глубокой настройке с помощью API более низкого уровня. По сути, LlamaIndex полностью раскрывает потенциал LLM, делая их более доступными и применимыми к индивидуальным задачам, связанным с данными.
Как работает LlamaIndex?
Фреймворк LlamaIndex служит мостом, соединяющим впечатляющие возможности LLM с различными источниками данных. Тем самым он открывает новую сферу приложений, способных использовать синергию между пользовательскими данными и продвинутыми языковыми моделями. Предлагая инструменты для ввода и индексирования данных, а также интерфейс обработки запросов на естественном языке, LlamaIndex позволяет разработчикам и компаниям создавать надежные приложения, дополненные данными, которые значительно повышают эффективность принятия решений и вовлеченность пользователей.
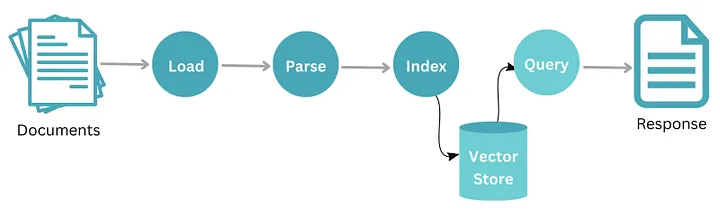
Функционирование LlamaIndex предполагает систематизированный рабочий процесс, который начинается с набора документов. Сначала эти документы проходят процесс загрузки, в ходе которого они импортируются в систему. После загрузки данные подвергаются парсингу, во время которого осуществляется анализ и структурирование контента в понятной форме. После парсинга информация индексируется для оптимального поиска и хранения.
Эти проиндексированные данные надежно хранятся в центральном хранилище, обозначенном как “store”. Чтобы получить определенную информацию из этого хранилища, пользователь или система отправляет запрос. В ответ на этот запрос извлекаются соответствующие данные и предоставляются в виде ответа. Он может представлять собой набор релевантных документов или конкретную информацию, взятую из них. Из этого процесса видно, как LlamaIndex эффективно управляет и извлекает данные, обеспечивая быстрые и точные ответы на запросы пользователей.
Llama 2

Llama 2 — это современная языковая модель, разработанная компанией Meta. Она стала преемницей оригинальной LLaMA, предложив улучшения в плане масштабирования, эффективности и производительности. Модели Llama 2 имеют от 7 млрд до 70 млрд параметров, что позволяет удовлетворить потребности различных вычислительных мощностей и приложений. Предназначенная для интеграции с чат-ботами, Llama 2 демонстрирует превосходство в диалоговых сценариях, предлагая детальные и последовательные ответы, которые расширяют границы возможностей разговорного ИИ.
Llama 2 проходит предварительное обучение на общедоступных онлайн-данных. Для этого модель подвергается воздействию большого массива текстовых данных, таких как книги, статьи и другие источники письменного контента. Цель такого предварительного обучения — помочь модели изучить общие языковые шаблоны и получить широкое понимание структуры языка. В процессе обучения также используются контролируемая тонкая настройка и обучение с подкреплением на основе обратной связи от человека (RLHF).
Одним из компонентов RLHF является критическая выборка, которая предполагает выбор ответа модели и его принятие или отклонение на основе обратной связи с человеком. Другой компонент RLHF — проксимальная оптимизация политики (PPO), которая включает обновление политики модели непосредственно на основе обратной связи с человеком. Наконец, итеративная доработка обеспечивает достижение моделью желаемого уровня производительности с помощью контролируемых итераций и корректировок.
Hugging Face

Hugging Face — это многофункциональная платформа, которая играет важную роль в развитии искусственного интеллекта, особенно в области обработки естественного языка (NLP) и генеративного ИИ. Она включает различные элементы, взаимодействие которых позволяет пользователям исследовать, создавать и демонстрировать приложения на основе ИИ.
Вот описание ее ключевых аспектов.
1. Концентратор моделей
- Hugging Face содержит обширный репозиторий предварительно обученных моделей для различных NLP-задач, включая классификацию текстов, ответы на вопросы, перевод и генерацию текстов.
- Эти модели обучены на больших наборах данных и могут быть точно настроены под конкретные требования, что делает их легко применимыми для различных целей.
- Репозиторий избавляет пользователей от необходимости обучать модели с нуля, что экономит время и ресурсы.
2. Наборы данных
- Наряду с библиотекой моделей, Hugging Face предоставляет доступ к обширной коллекции наборов данных для NLP-задач.
- Эти наборы данных охватывают различные области и языки, предлагая ценные ресурсы для обучения и тонкой настройки моделей.
- Пользователи также могут предоставлять свои собственные наборы данных, обогащая ресурсы платформы и способствуя сотрудничеству с сообществом.
3. Инструменты для обучения и тонкой настройки моделей
- Hugging Face предлагает инструменты и функциональные возможности для обучения и тонкой настройки готовых моделей на конкретных наборах данных и задачах.
- Это позволяет пользователям адаптировать модели под собственные нужды, повышая их производительность и точность в целевых приложениях.
- Платформа предоставляет гибкие возможности для обучения, включая локальное обучение на персональных компьютерах или облачные решения для больших моделей.
4. Создание приложений
- Hugging Face облегчает разработку приложений на основе ИИ, легко интегрируясь с такими популярными библиотеками программирования, как TensorFlow и PyTorch.
- Это позволяет разработчикам создавать чат-боты, инструменты для генерации контента и другие приложения на базе ИИ, используя предварительно обученные модели.
- Многочисленные шаблоны приложений и туториалы помогают пользователям ускорить процесс разработки.
5. Сообщество и сотрудничество
- Hugging Face может похвастаться активным сообществом разработчиков, исследователей и энтузиастов ИИ.
- Платформа способствует сотрудничеству благодаря таким функциям, как общее использование моделей, репозитории кода и тематические форумы.
- Такая среда сотрудничества продвигает обмен знаниями, ускоряет инновации и стимулирует развитие NLP-технологий и генеративного ИИ.
Hugging Face — не просто хранилище моделей. Это комплексная платформа, включающая модели, наборы данных, инструменты и процветающее сообщество, позволяющие пользователям с легкостью изучать, создавать и распространять приложения для ИИ. Hugging Face — ценный актив для частных лиц и организаций, стремящихся использовать возможности ИИ в своих начинаниях.
Haystack

Haystack можно определить как сквозной фреймворк для создания приложений на основе различных NLP-технологий, включая генеративный ИИ, но не ограничиваясь им. Не будучи ориентированным непосредственно на создание генеративных моделей с нуля, Haystack предоставляет надежную платформу для следующих целей.
1. Генерация, дополненная поиском (RAG)
Haystack отлично сочетает поисковые и генеративные подходы к поиску и созданию контента. Он позволяет интегрировать различные методы поиска, включая векторный поиск и традиционный поиск по ключевым словам, для получения соответствующих документов для дальнейшей обработки. Эти документы затем служат исходным материалом для генеративных моделей, в результате чего получаются более целенаправленные и контекстуально релевантные результаты.
2. Разнообразные NLP-компоненты
Haystack предлагает обширный набор инструментов и компонентов для решения различных NLP-задач , включая предварительную обработку документов, обзоры информационных текстов, ответы на вопросы и распознавание именованных сущностей. Это позволяет создавать сложные конвейеры, сочетающие несколько NLP-методов для достижения конкретных целей.
3. Гибкость настройки и открытый исходный код
Haystack — это фреймворк с открытым исходным кодом, построенный на базе популярных библиотек, таких как Transformers и Elasticsearch. Это позволяет настраивать и интегрировать его с существующими инструментами и рабочими процессами, что делает фреймворк адаптируемым к различным потребностям.
4. Масштабируемость и производительность
Haystack разработан для эффективной обработки больших массивов данных и рабочих нагрузок. Он интегрируется с мощными векторными базами данных, такими как Pinecone и Milvus, обеспечивая быстрый и точный поиск и извлечение информации даже из миллионов документов.
5. Интеграция с генеративным ИИ
Haystack легко интегрируется с такими популярными генеративными моделями, как GPT-3 и BART. Такая способность позволяет использовать возможности генеративных моделей для решения различных задач (например, создание, обобщение и перевод текстов в приложениях, разработанных на Haystack).
Хотя Haystack ориентирован не только на генеративный ИИ, он обеспечивает надежную основу для создания приложений, использующих эту технологию. Его сильные стороны в области поиска, разнообразные NLP-компоненты, гибкость и масштабируемость делают его ценным фреймворком для разработчиков и исследователей, позволяющим использовать потенциал генеративного ИИ в различных приложениях.
Заключение
В стремительно развивающейся сфере генеративного ИИ лидируют такие фреймворки и инструменты, как HuggingFace, LangChain, LlamaIndex, Llama2, Haystack и SingleStore Notebooks. Эти технологии предлагают разработчикам множество вариантов интеграции ИИ в их проекты, будь то обработка естественного языка, аналитика данных или сложные приложения на основе ИИ.
Читайте также:
- Новая большая речевая модель Watson от IBM предоставит голос генеративному ИИ
- Программирование будущего: беспилотный автомобиль, управляемый JavaScript и ИИ
- LangChain + Streamlit + LlaMA: установка диалогового бота с ИИ на локальный компьютер
Читайте нас в Telegram, VK и Дзен
Перевод статьи Pavan Belagatti: Gen AI Frameworks and Tools Every AI/ML Engineer Should Know!





