
Переход с Pandas на Spark и Scala не настолько труден, насколько вы можете предположить, при этом в итоге ваш код будет выполняться быстрее, и, скорее всего, качество его написания тоже возрастёт.
Работая инженером по работе с данными, я понял, что в Pandas создание конвейеров зачастую требует от нас регулярного повышения ресурсов, чтобы поспевать за растущим потреблением памяти. Кроме того, мы нередко видим много ошибок среды выполнения в связи с неожиданными типами данных или нулевыми значениями. Если же использовать Spark и Scala, то решения получаются как более надёжными, так и легче поддающимися рефакторингу или расширению.
В этой статье мы рассмотрим следующее:
- Почему стоит использовать Spark и Scala вместо Pandas.
- Узнаем, что Scala Spark API не сильно отличается от Pandas API.
- Разберёмся, как начать использовать либо блокнот Jupyter, либо вашу любимую IDE.
Что такое Spark?
- Spark — это открытый фреймворк от Apache.
- Его можно использовать в качестве библиотеки и запускать либо на локальном кластере, либо на кластере Spark.
- На кластере Spark код можно выполнять распределённым способом с помощью одного ведущего и нескольких рабочих узлов, разделяющих нагрузку.
- Даже на локальном кластере вы сможете увидеть прирост производительности по сравнению с Pandas, и мы поговорим об этом ниже.
Зачем использовать Spark?
Spark стал популярен, благодаря способности обрабатывать огромные наборы данных с высокой скоростью.
- По умолчанию Spark работает в многопоточном режиме, в то время как Pandas в однопоточном.
- Код Spark можно выполнять распределённым способом на кластере Spark, Pandas же выполняется на одной машине.
- Spark ленив, поэтому он будет выполнять код, только когда вы выполняете инструкцию collect (т.е. когда вам фактически нужно вернуть что-либо), в остальное же время он составляет план оптимального выполнения кода.
- Pandas же наоборот энергична и выполняет каждый шаг сразу при его достижении.
- Spark также с меньшей вероятностью истощит ресурсы памяти, поскольку при достижении её лимита, он начинает использовать диск.
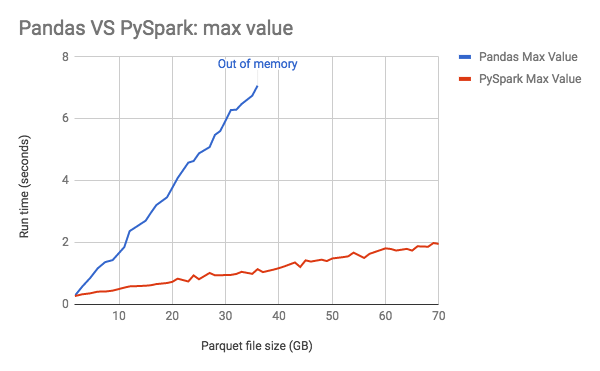
Для визуального сравнения среды выполнения просмотрите приведённую ниже диаграмму от Databricks, на которой видно, что Spark существенно быстрее, чем Pandas, а также то, что Pandas исчерпывает ресурсы памяти на более раннем этапе.
У Spark богатая экосистема
- Библиотеки для обработки данных вроде встроенной Spark ML или Graph X для алгоритмов на графах.
- Spark Streaming для обработки данных в реальном времени.
- Совместимость с другими системами и типами файлов (orc, parquet и т.д.)
Почему Scala, а не PySpark?
Spark предоставляет знакомый API, поэтому использование Scala вместо Python не потребует длительного изучения. Вот некоторые из причин, почему вам стоит предпочесть Scala:
- Scala статически типизированный язык, благодаря чему появление в коде ошибок среды выполнения менее вероятно, чем с Python.
- Scala также позволяет создавать неизменяемые объекты, т.е. при обращении к объекту вы можете быть уверены, что с момента создания и до момента вызова его состояние не изменялось.
- Spark написан на Scala, поэтому в Scala новый функционал появляется раньше, чем в Python.
- Использование Scala может способствовать сотрудничеству инженеров и аналитиков данных, поскольку код Scala предлагает безопасность типов и неизменяемость.
Ключевые принципы Spark
- Датафрейм: в Spark датафрейм— это структура данных очень схожая с датафреймом в Pandas.
- Набор данных: набор данных— это типизированный датафрейм, который может быть очень полезен для обеспечения соответствия ваших данных ожидаемой схеме.
- RDD: это основная структура данных в Spark, поверх которой создаются датафреймы и наборы данных.
Вообще мы будем использовать наборы данных везде, где только сможем, потому что они типобезопасны, более эффективны и повышают читаемость, поскольку становится ясно, какие данные мы в них ожидаем.
Набор данных
Для создания набора данных нам сначала нужно создать класс-образец, который похож на класс данных в Python и всего лишь является способом определить структуру данных.
К примеру, давайте создадим класс-образец FootballTeam с несколькими полями:
case class FootballTeam(
name: String,
league: String,
matches_played: Int,
goals_this_season: Int,
top_goal_scorer: String,
wins: Int
)А теперь давайте создадим экземпляр этого класса:
val brighton: FootballTeam =
FootballTeam(
"Brighton and Hove Albion",
"Premier League",
matches_played = 29,
goals_this_season = 32,
top_goal_scorer = "Neil Maupay",
wins = 6
)Давайте введём ещё один экземпляр, назвав его manCity и теперь из этих двух FootballTeam мы создадим набор данных.
val teams: Dataset[FootballTeam] = spark.createDataset(Seq(brighton,
manCity))Другой способ реализации этого:
val teams: Dataset[FootballTeam] =
spark.createDataFrame(Seq(brighton, manCity)).as[FootballTeam]Второй способ может быть полезен при считывании данных из внешнего источника и возвращении датафрейма, поскольку затем вы можете привести его в набор данных, чтобы в итоге получить типизированную коллекцию.
Преобразование данных
Большую часть (если не все) преобразований данных, которые вы можете применить к датафреймам Pandas, доступны в Spark. Есть, конечно, отличия в синтаксисе, а иногда и дополнительные требующие внимания моменты, некоторые из которых мы сейчас рассмотрим.
В целом я убедилась, что Spark более последователен в нотации по сравнению с Pandas и, поскольку Scala типизирован статически, вы зачастую можете просто выполнить myDataset и ожидать, пока компилятор сообщит вам, какие методы доступны.
Давайте начнём с простого преобразования, в котором мы просто добавим в наш набор данных новый столбец и присвоим ему постоянное значение. В Pandas это выглядит так:
Pandasdf_teams['sport'] = 'football'
В Spark есть небольшое отличие помимо синтаксиса, а именно то, что добавление постоянного значения этому новому полю требует импортировать функцию Spark под названием lit.
Sparkimport org.apache.spark.sql.functions.litval newTeams = teams.withColumn("sport", lit("football"))
Обратите внимание, что мы создали новый объект, поскольку наш изначальный набор данных teams является val, т.е. он неизменяемый. Это хорошо, так как мы знаем, что, где бы мы ни использовали наборданных teams, мы везде получим один и тот же объект.
А теперь давайте добавим столбец на основе функции. В Pandas это будет выглядеть так:
Pandasdef is_prem(league):
if league == 'Premier League':
return True
else:
return False
df_teams['premier_league'] = df_teams['league'].apply(lambda x:
is_prem(x))Чтобы проделать то же самое в Spark нам нужно сериализовать функцию, чтобы Spark мог её применить. Это делается при помощи использования так называемых UserDefinedFunctions (пользовательских функций). Мы также использовали сопоставление со значением league, поскольку в Scala эта реализация более симпатична, чем if-else, хотя сработает и та, и другая.
Помимо этого, нам потребуется импортировать ещё одну полезную функцию Spark — col, которая используется для обращения к столбцу.
Sparkimport org.apache.spark.sql.functions.coldef isPrem(league: String): Boolean =
league match {
case "Premier League" => true
case _ => false
}
val isPremUDF: UserDefinedFunction =
udf[Boolean, String](isPrem)
val teamsWithLeague: DataFrame = teams.withColumn("premier_league",
isPremUDF(col("league")))Теперь, когда мы добавили новый столбец, не находящийся в нашем классе-образце, он преобразует его обратно в датафрейм. Поэтому нужно либо добавить ещё одно поле в изначальный класс-образец (и допустить для него нулевые значения, используя Option), либо создать новый.
Option в Scala просто означает, что поле допускает нулевое значение. Если значение нулевое, мы используем None, а если заполнено, то Some("value"). Пример опциональной строки:
val optionalString : Option[String] = Some("something")
Для получения отсюда строки мы можем вызвать optionalString.get(), получив тем самым "something". Обратите внимание, что если мы не уверены, будет ли значение нулевым, то можем использовать optionalString.getOrElse("nothing"), которая в случае нулевого значения вернёт строку "nothing".
Фильтрация набора данных является ещё одним общим требованием и является хорошим примером лучшей последовательности Spark в сравнении с Pandas, поскольку она следует тем же шаблонам, что и другие преобразования, где мы производим “точечную” трансформацию набора данных (например, dataset.filter(...)).
Pandasdf_teams = df_teams[df_teams['goals_this_season'] > 50]
Sparkval filteredTeams = teams.filter(col("goals_this_season") > 50)Нам, скорее всего, потребуется выполнить с нашим набором данных ряд агрегаций, которые в Pandas и Spark очень схожи.
Pandasdf_teams.groupby(['league']).count()
Sparkteams.groupBy("league").count()Для нескольких агрегаций мы можем опять же делать всё аналогично Pandas, используя отображение поля в агрегацию. Если же мы хотим делать свои собственные агрегации, то можем использовать UserDefinedAggregations (пользовательские агрегации).
teams.agg(Map(
"matches_played" -> "avg",
"goals_this_season" -> "count"))Зачастую нам также нужно совместить несколько наборов данных, что можно сделать при помощи объединения (union):
Pandaspd.concat([teams, another_teams], ignore_index=True)
Sparkteams.unionByName(anotherTeams)… или присоединения (join):
val players: Dataset[Player] = spark
.createDataset(Seq(neilMaupey, sergioAguero))
teams.join(players,
teams.col("top_goal_scorer") === players.col("player_name"),
"left"
).drop("player_name")В этом примере мы также создали новый набор данных, на этот раз используя класс Player. Обратите внимание, что этот класс-образец содержит поле injury, которое может быть null.
case class Player(player_name: String, goals_scored: Int,
injury: Option[String])Стоит заметить, что мы отбросили (drop) столбец player_name, поскольку он бы повторял top_goal_scorer.
Нам также может понадобиться, чтобы части кода просто использовали нативные структуры данных Scala вроде массивов, списков и т.д. Чтобы получить один из наших столбцов в качестве массива, нам нужно отобразить значение и вызвать .collect().
val teamNames: Array[String] = teams.map(team => team.name)
.collect()Обратите внимание, что мы можем использовать встроенные в классы-образцы геттеры, чтобы вернуть поле name, и если в классе FootballTeam не окажется поля name, то компиляция не произойдёт.
Кстати говоря, мы также можем добавлять в наши классы-образцы функции. В этом случае и значения, и функции будут появляться в виде вариантов автодополнения при использовании IDE вроде IntelliJ или VS Code с плагином Metals.
Чтобы отфильтровать набор данных, опираясь на то, существует ли он в этом массиве, нам нужно обработать его как последовательность аргументов, вызвав _*.
val filteredPlayers: Dataset[Player] = players
.filter(col("team").isin(teamNames: _*))Выполнение кода
Надеюсь, что к данному моменту у вас уже возникло желание написать какой-нибудь код в Spark, даже просто ради того, чтобы убедиться в верности моего утверждения об их схожести с Pandas.
У нас есть два варианта: мы можем либо использовать блокнот, который окажется быстрым способом получить данные и начать с ними экспериментировать, либо настроить простой проект. Так или иначе у нас должна быть установлена Java 8.
Блокнот
Для этого примера мы будем использовать ядро spylon в блокноте Jupyter (https://pypi.org/project/spylon-kernel/). Сначала выполните настройку блокнота с помощью нижеприведённых команд, которые должны открыть его в браузере. Затем выберите из доступных ядер spylon-kernel.
pip install spylon-kernel
python -m spylon_kernel install
jupyter notebookДавайте проверим наличие правильной версии Java, добавив в ячейку следующее:
!java -version
Вывод должен быть таким:
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)Если нет, проверьте переменную JAVA_HOME в профиле bash и убедитесь, что она указывает на Java 8.
Следующим шагом будет установка ряда зависимостей. Для этого мы можем добавить в новую ячейку фрагмент кода, приведённый ниже. Он установит определённую конфигурацию Spark и также позволит добавить зависимости. Здесь я добавил библиотеку визуализации под названием vegas.
%%init_spark
launcher.num_executors = 4
launcher.executor_cores = 2
launcher.driver_memory = '4g'
launcher.conf.set("spark.sql.catalogImplementation", "hive")
launcher.packages = ["org.vegas-viz:vegas_2.11:0.3.11",
"org.vegas-viz:vegas-spark_2.11:0.3.11"]Для подключения к источнику данных мы можем определить функцию, например такую:
def getData(file: String): DataFrame =
spark.read
.format("csv")
.option("header", "true")
.load(file)Это подключение к csv-файлу, но есть множество других источников данных, к которым мы можем подключаться. Эта функция возвращает датафрейм, который можно преобразовать в набор данных:
val footballTeams: Dataset[FootballTeam] =
getData("footballs_teams.csv").as[FootballTeam]
Мы можем начать работать с этими данными, а также пробовать рассмотренные ранее их преобразования и многое другое.
Настройка проекта
Теперь, когда вам уже известно, как можно экспериментировать с данными, вы, наверняка, захотите настроить проект.
В него нужно включить два основных компонента:
- build.sbt — если ранее мы добавляли зависимости в одну из ячеек блокнота, то теперь нужно добавить их в файл build.sbt.
- SparkSession —в блокноте у нас уже была сессия Spark, что давало возможность совершать такие действия, как
spark.createDataFrame. В проекте же нам нужно создать эту сессию Spark.
Пример build.sbt:
name := "spark-template"
version := "0.1"
scalaVersion := "2.12.11"val sparkVersion = "2.4.3"
libraryDependencies += "org.apache.spark" %% "spark-core" % sparkVersion
libraryDependencies += "org.apache.spark" %% "spark-sql" % sparkVersionПример SparkSession:
import org.apache.spark.sql.SparkSession trait SparkSessionWrapper { val spark: SparkSession = SparkSession
.builder()
.master("local")
.appName("spark-example")
.getOrCreate()
}Затем мы можем расширить объекты с помощью этой обёртки, предоставляемой сессией Spark:
object RunMyCode extends SparkSessionWrapper { //место для кода
}object RunMyCode extends SparkSessionWrapper { //место для кода
}После этого вы можете начинать писать код Spark.
Подводя итог, хочу отметить, что Spark — это отличный инструмент для быстрой обработки данных с также быстро растущей популярностью в этой области. В результате Scala также становится более востребованным языком, и, благодаря его типобезопасности, может стать хорошим выбором для инженеров по работе с данными и аналитиков, которые чаще больше знакомы с Python и Pandas. Spark — это отличное введение в язык, потому что мы можем использовать знакомые принципы вроде датафреймов, благодаря чему долгого изучения не потребуется.
Надеюсь, что, предоставив этот краткий обзор, я смогла заинтересовать вас изучением Spark в рамках вашего блокнота или нового проекта.
Удачи!
Читайте также:
- Apache Spark: гайд для новичков
- Функциональное программирование со Scala: введение
- 3 функции Pandas, которые стоит использовать чаще
Перевод статьи Chloe Connor: Stop using Pandas and start using Spark with Scala.





