
Возможно, многие из вас уже начинали изучать инженерию данных, но вскоре понимали, что осилить эту науку вам не под силу. То ли из-за сложной терминологии, то ли из-за обучающих программ, требующих обширного опыта программирования, как правило, эта область знаний постигается с большим трудом.
Данное же руководство отличается доступной и увлекательной манерой изложения, понятной любому новичку. Вас ждёт работа над проектом и погружение в суть концепции датафрейма Spark.
В качестве напутствия советую вам не просто бегло просмотреть статью, а углубиться в осмысление её материала и самостоятельно выполнить задания, поскольку только в этом случае вы сможете извлечь из неё реальную практическую пользу.
Вступительная часть окончена — переходим к главному!
Подготовка к выполнению программ
Для работы с данным руководством необходимо установить IntelliJ, Git, Java и Apache Spark.
А теперь самое интересное!
Что такое Apache Spark?

Представьте себе пчелиный улей. В нем проживает одна матка и сотни или тысячи рабочих пчёл, при этом у всех свои конкретные роли. Королева пчёл — это центр управления общим процессом, она дирижирует целым оркестром своих подопечных, перед которыми стоят сотни насущных задач. В этом оркестре рабочие пчёлы — исполнители, которые делают все необходимое для их выполнения.
Что общего у пчёл и Apache Spark?
Хороший вопрос! Согласно официальному определению Apache Spark — это движок распределённой обработки данных широкого назначения. Он также известен как фреймворк для кластерных вычислений и крупномасштабной обработки данных. Теперь разберёмся во всем этом подробно.
Распределённые данные: Spark создан для работы с особо большими объёмами данных. Настолько большими, что при загрузке в приложение они запросто могут подвесить любой компьютер. Чтобы этого не произошло, Spark использует группу согласованных компьютеров (так называемый кластер), обрабатывающих задачи в соответствии с поставленными целями. Догадываетесь, почему здесь уместна аналогия с пчёлами? Рассмотрим диаграмму:
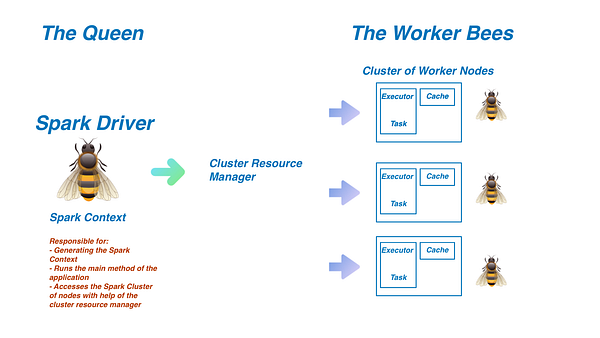
Драйвер Spark выполняет функции пчелиной матки. Он отвечает за создание такого важного класса, как Spark Context, обеспечивающего доступ ко всем функциональностям Spark. С помощью диспетчера кластерных ресурсов (как правило, YARN, Mesos или Standalone) этот драйвер через обращение будет распределять задачи между исполнителями кластера Spark, иначе называемыми рабочими узлами. Именно в нем выполняется основной метод, согласно которому любая написанная программа сначала взаимодействует с драйвером, после чего в виде задач отправляется на рабочие узлы.
Исполнители Spark играют роль рабочих пчёл. Они решают задачи, отправленные им драйвером через диспетчера кластерных ресурсов. В процессе выполнения установленных заданий исполнители будут сохранять результаты в области памяти, именуемой кэшем. Если один из узлов выходит из строя, то решение предписанной ему задачи поручается другому. Каждый узел может иметь до одного исполнителя на ядро. По завершении работы результаты возвращаются все в тот жедрайвер Spark.
Итак, мы затронули важные теоретические аспекты, теперь переходим к практике.
Главное понятие: датафреймы Spark
API датафреймов — это один из важнейших аспектов Spark, которому будут посвящены следующие разделы статьи.
Датафреймы представляют собой распределённые таблицы со строками и столбцами. Таблица разбивается по узлам, каждый из которых содержит схему датафрейма и несколько строк.
Схема в датафрейме — это список с описанием имён столбцов и типов строк. Она может включать произвольное число столбцов. Каждая строка каждого узла будет иметь одну и ту же схему для датафрейма. Spark использует принцип разделения, чтобы распределять данные по файлам для совместного использования узлами в кластере.
Работая с датафреймами, вы должны знать о них следующее:
- Они неизменяемы. Создав датафрейм, вы уже не сможете его изменить.
- Датафреймы могут работать с широким спектром форматов данных. В нашем случае мы имеем дело с данными в формате JSON.
- С помощью Spark SQL вы можете запросить датафрейм подобно любой реляционной базе данных.
Навстречу своему первому датафрейму!
А вот теперь самая интересная часть! Откройте новую вкладку и перейдите в репозиторий GitHub: https://github.com/nickrafferty78/Apache-Spark-Is-Fun.
Вероятно, у вас уже есть собственный аккаунт на GitHub. Если нет, то вам необходимо его создать, прежде чем приступать к следующему этапу.
Сначала создайте форк репозитория:
Далее перейдите в свой аккаунт GitHub и откройте репозиторий, форк которого был только что создан. Кликните на кнопку ‘Code’ и скопируйте указанный ниже URL. После этого введите следующую команду в терминал (не забудьте подставить своё имя пользователя вместо ‘your-github-username’):
git clone https://github.com/your-github-username/Apache-Spark-Is-Fun.git
Теперь запустим IntelliJ. Откройте в ней проект, который вы только что скопировали на компьютер, затем перейдите в класс Tutorial по адресу src/main/scala/Tutorial.scala.
Создание Spark Session
Вот небольшой стартовый код, который поможет настроить приложение. Он должен выглядеть следующим образом:
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.LongType
import Utilities._
object Tutorial extends App {
Utilities.setupLogging()
}Скопируйте и вставьте следующий код под Utilities.setupLogging():
val spark = SparkSession
.builder()
.appName("InstrumentReviews")
.master("local[*]")
.getOrCreate()Поздравляю — вы написали свой первый Spark Session (сеанс Spark)! Теперь разберём его более детально.
Как уже упоминалось, Spark Session — это отправная точка, с которой начинается использование датафреймов. О ней нужно знать следующее:
- Метод .appName даёт имя Spark Session. Поскольку в этом разделе будет использоваться набор данных InstrumentReviews.json, назовём его соответственно ‘InstrumentReviews’.
- Метод .master указывает URL, к которому должен подключиться Spark. Поскольку мы запускаем сеанс на своём компьютере, то ‘local’ говорит Spark использовать именно его вместо внешнего. Вслед за local следует интересный символ [*], с которым вы, возможно, не знакомы. Это один из основополагающих принципов Spark, благодаря которому распределение данных происходит самым эффективным способом. У вашего компьютера, скорее всего, больше одного ядра. Каждое ядро может выполнять задачи независимо друг от друга. У моего компьютера — 2 ядра, поэтому, используя [*], вы инструктируете Spark запустить рабочий процесс на каждом ядре.
- Наконец, .getOrCreate() создаёт сеанс.
Чтение данных
В следующем примере мы поработаем с данными обзора музыкальных инструментов. Прежде чем переходить к чтению данных, всегда следует с ними ознакомиться. Перейдём в /data/InstrumentReviews.json и увидим очень большой файл с информацией по обзору инструментов. Ниже приведён пример одной из записей:
{
"reviewerId":"A2IBPI20UZIR0U",
"reviewerName":"cassandra tu \,
"reviewText":"Этот поп-фильтр убирает лишние звуки, чтобы улучшить качество записей",
"overall":5.0,
"summary":"good"
}Теперь вернитесь к Tutorial.scala и под созданным Spark Session скопируйте и вставьте этот код:
val firstDataFrame = spark
.read
.format("json")
.option("inferSchema", "true")
.load("data/InstrumentReviews.json")Поскольку переменная Spark уже создана, в данном блоке кода сеанс Spark используется для чтения входящих данных.
- Метод .format указывает тип структуры, в который поступают данные. Наши данные обзора музыкальных инструментов — в JSON.
- .option, включающий “inferSchema” и “true”, говорит Spark вывести схему данных обзора музыкального инструмента без явного её определения.
- .load предоставляет Spark путь к файлу с данными.
Теперь посмотрим, будет ли все это работать!
Для отображения firstDataFrame под кодом напишите эти 2 строки:
firstDataFrame.show()
firstDataFrame.printSchema()
Если все прошло должным образом, то вы увидите следующий результат:
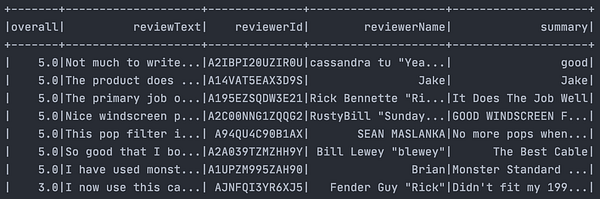
root
|-- overall: double (nullable = true)
|-- reviewText: string (nullable = true)
|-- reviewerId: string (nullable = true)
|-- reviewerName: string (nullable = true)
|-- summary: string (nullable = true)Если именно это у вас и получилось — значит вы только что написали свой первый датафрейм!
Что же все это значит?
В предыдущем разделе мы говорили о том, что датафрейм — это распределённая коллекция строк, согласованных со схемой.
Это ваша схема:
root
|-- overall: double (nullable = true)
|-- reviewText: string (nullable = true)
|-- reviewerId: string (nullable = true)
|-- reviewerName: string (nullable = true)
|-- summary: string (nullable = true)Когда вы велели Spark вывести схему (inferSchema), то получили соответствующий результат на основании структуры файла InstrumentReviews.json. Но нужно следить за тем, чтобы Spark не выводил неверные схемы. Поэтому напишем все необходимое вручную.
Сначала из переменной firstDataFrame удалите строку .option(“inferSchema”, “true”). Теперь перейдём к написанию схемы. В Spark можно создать StructType, содержащий массив из StructFields.
А что такое StructType?
В Spark StructType является объектом, используемым для определения схемы. Он содержит StructFields, которые определяют имя и тип поля, а также допускает ли оно значение null. Рассмотрим все на примере.
Перейдите в файл /data/InstrumentReviews.json. Вот ваша схема:
{
"reviewerId":"A2IBPI20UZIR0U",
"reviewerName":"cassandra tu \,
"reviewText":"Этот поп-фильтр убирает лишние звуки, чтобы улучшить качество записей",
"overall":5.0,
"summary":"good"
}Как видим, нам нужно назвать первый столбец ‘reviewerID’, и именно он будет StringType.
На основании этого приступаем к написанию схемы. Переходим в Utilities.scala и готовимся вручную писать Schema.
И снова стартовый код должен выглядеть следующим образом:
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{ArrayType, DoubleType, IntegerType, LongType, StringType, StructField, StructType}
object Utilities {
def setupLogging() = {
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
}
}Объявляем переменную под и вне метода setupLogging.
val instrumentReviewsSchema = StructType(Array(
/* Здесь место для вашего кода*/
))Постарайтесь выполнить эту часть, не заглядывая в решение. Что вы здесь напишите?
Надеюсь, что допустив кое-какие ошибки в синтаксисе, в целом на основании всего выше сказанного вы напишите все правильно. Полная схема обзораинструмента должна выглядеть вот так:
val instrumentReviewsSchema = StructType(Array(
StructField("reviewerId", StringType, nullable = true),
StructField("reviewerName", StringType, nullable = true),
StructField("reviewText", StringType, nullable = true),
StructField("overall", DoubleType, nullable = true),
StructField("summary", StringType, nullable = true),
))Вам нужно сказать Spark включить только что созданную схему. Поэтому вернитесь в Tutorial.scala и замените .option(“inferSchema”, “true”) на .schema(“instrumentReviewsSchema”).
Выполняем!
Самостоятельная работа: задание #1
Приступаем к первому заданию. Перейдите в src/main/scala/ExerciseOne.scala и в этом файле выполните следующее:
- Войдите в data/yelp.json и ознакомьтесь со структурой входящего файла JSON.
- В Utilities.scala напишите схему для yelp.json. На этом этапе вам предстоит решить непростую задачу, связанную с объектами поля JSON, которую мы ещё не рассматривали. Я настоятельно рекомендую вам изучить соответствующий материал и узнать, как это будет выглядеть.
- Создайте Spark Session и назовите сеанс любым именем по своему усмотрению. Например, “YelpReviews”.
- Считайте датафрейм из файла data/yelp.json. Убедитесь, что добавили схему, написанную на этапе #2.
- Отобразите и выведите схему для написанного датафрейма.
Готово! Эта пошаговая инструкция поможет вам начать работу с датафреймами. Если вы застопорились на каком-то этапе, обязательно вернитесь к вышеприведённым пояснениям и переходите далее, только решив проблему.
Внимание — спойлер! Ниже вы увидите ответы к заданию!
Все ответы записаны в AnswerKey.scala.
- Эта структура немного сложнее предыдущей, с которой мы работали. Но надеюсь, вас это обстоятельство не остановило. Данные выглядят следующим образом:
{
"name":"Peace of Mind and Body Massage",
"city":"Akron",
"stars":5.0,
"review_count":3,
"state":"OH",
"hours":{
"Friday":"9:0-17:0",
"Monday":"9:0-17:0",
"Saturday":"9:0-20:0",
"Tuesday":"9:0-17:0",
"Wednesday":"9:0-17:0"
}2. Основная сложность этого набора данных заключается во вложенном внутри “hours” объекте JSON. Для ее решения нужно повторитьуже проделанные шаги и написать внутри Structfield “hours” массив StructType, содержащий поля StructField. Вот пример:
StructField("hours", StructType(
Array(
StructField("Monday", StringType),
StructField("Tuesday", StringType),
StructField("Wednesday", StringType),
StructField("Thursday", StringType),
StructField("Friday", StringType),
StructField("Saturday", StringType),
StructField("Sunday", StringType)
)
))А вот вся схема:
val yelpSchema = StructType(Array(
StructField("name", StringType, nullable = true),
StructField("city", StringType, nullable = true),
StructField("stars", DoubleType, nullable = true),
StructField("review_count", IntegerType, nullable = true),
StructField("hours", StructType(
Array(
StructField("Monday", StringType),
StructField("Tuesday", StringType),
StructField("Wednesday", StringType),
StructField("Thursday", StringType),
StructField("Friday", StringType),
StructField("Saturday", StringType),
StructField("Sunday", StringType)
)
)),
))3. Spark Session очень похож на тот, что мы писали выше. В результате он должен выглядеть вот так:
val spark = SparkSession
.builder()
.appName("YelpReviews")
.master("local[*]")
.getOrCreate()4. Прочтите файл yelp.json с помощью определённой вами схемы.
val yelpDF = spark.read
.schema(yelpSchema)
.format("json")
.load("data/yelp.json")5. В завершении отобразите и выведите схему.
yelpDF.show()
yelpDF.printSchema()В итоге должно получиться следующее:
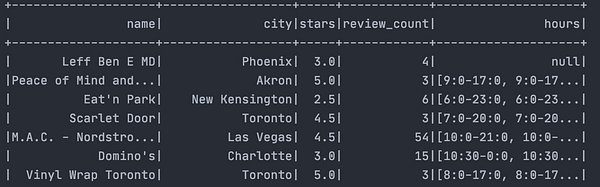
root
|-- name: string (nullable = true)
|-- city: string (nullable = true)
|-- stars: double (nullable = true)
|-- review_count: integer (nullable = true)
|-- hours: struct (nullable = true)
| |-- Monday: string (nullable = true)
| |-- Tuesday: string (nullable = true)
| |-- Wednesday: string (nullable = true)
| |-- Thursday: string (nullable = true)
| |-- Friday: string (nullable = true)
| |-- Saturday: string (nullable = true)
| |-- Sunday: string (nullable = true)Хорошая работа!
Поздравляю! Вы успешно справились с первым заданием в Spark. Теперь вы знаете, как создать сеанс Spark, написать схему и прочитать файл JSON. Не говоря уже о том, что вы реализовали своё желание узнать о Spark как можно больше. Но продолжайте изучать этот фреймворк, поскольку в нем ещё очень много интересного.
Читайте также:
- От HTTP до HTTP 3 - интернета будущего
- Решаем проблему запроса N+1 в GraphQL с помощью Dataloader
- Построение горизонтально масштабируемых stateful-приложений с помощью ASP.NET Core
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Nick Rafferty: Apache Spark Is Fun





