
Инкрементное проектирование
Теперь, когда бизнес-проблема разбита на требования к данным, разобьем их на еще более мелкие задачи — создадим дорожную карту инкрементной разработки проекта. Будем следовать принципам Agile, чтобы обеспечить получение ценности на каждой итерации (временном интервале, в течение которого решаются определенные задачи).
Спринт 1. Создание простого конвейера для приема данных
Начнем с создания очень простого конвейера для приема данных для нашего бизнеса. Это своего рода POC (proof of concept, доказательство правильности концепции), и мы можем быстро создать MVP (продукт с минимальным функционалом) — простой конвейер данных для “Крупной кредитной компании”.
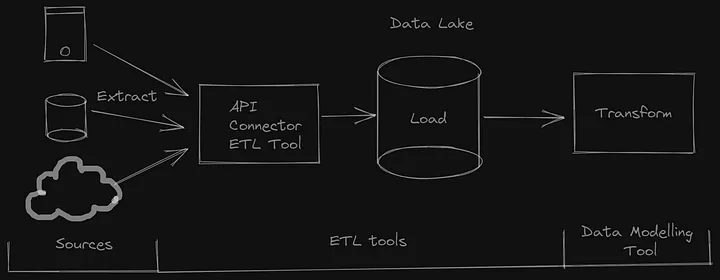
Разобьем эту задачу на более мелкие.
- Определение источников данных. У нас есть 3 структурированных, 2 полуструктурированных и 1 неструктурированный источник данных. Предположим, что источниками являются 3 базы данных SQL, 1 база данных NoSQL, совместно используемый сетевой путь для сбора документов и API для получения данных о кредитах. Разнообразие источников определит инструмент/технологию приема данных.
- Выбор инструмента для приема данных. Это очень важный компонент, который должен быть проанализирован с учетом имеющихся навыков, требований к источникам данных и т. д. Однако для простоты обучения возьмем базовый Python/Scala для приема данных. Можно поэкспериментировать с различными инструментами в реальной проектной среде.
- Ручная настройка инфраструктуры. Установка Python/Scala, всех зависимостей и необходимой инфраструктуры (общей папки/облачного хранилища/HFDS-хранилища).
- Извлечение данных. Написание кода на Python/Scala для подключения к различным источникам и извлечения данных из них.
- Загрузка в озеро данных. Создание папки RAW/Bronze в локальной файловой системе, облачном озере данных или HDFS. Эта папка будет рассматриваться как озеро данных. Подключение к папке и копирование данных из источника в озеро данных.
- Преобразование данных. Создание в озере данных папки silver/refined. Это второй уровень преобразования данных. Реализация базовых преобразований, таких как дедупликация, очистка данных, объединение в единый источник достоверных данных и т. д.
- Загрузка в место назначения (Хранилище/Золотой слой). Это слой данных, готовых к представлению. В идеале данные загружаются в хранилище данных по схеме “звезды” (Star schema)/киоска данных (data mart)/хранилища данных по типу data vault schema. В этом слое реализуется моделирование данных. Здесь также можно использовать относительно новые таблицы delta lake/iceberg.
В процессе создания вы можете познакомиться с различными инструментами ELT/ETL, например Fivetran, Airbyte и Azure Data Factory. Вы узнаете о таких механизмах преобразования, как Spark и MapReduce.
Весь этот процесс не должен занять у вас больше недели. На второй неделе добавим в конвейер несколько дополнительных сложностей.
Спринт 2. Добавление идемпотентности конвейеру
Что означает понятие “идемпотентность”? Обратимся к учебному материалу платформы Start Data Engineering:
“Идемпотентность — свойство некоторых операций в математике и информатике, при котором они могут применяться многократно без изменения результата, полученного после первоначального применения” (Википедия).
Определяется как:
f(f(x)) = f(x)
В инженерии данных это означает следующее: многократный запуск конвейера данных с одними и теми же входными данными всегда приводит к одному и тому же результату.
- Отслеживание реализации. Для распознавания и игнорирования повторяющихся операций можно использовать уникальный идентификатор или механизм отслеживания. Таким образом, даже при повторном выполнении операции она либо не будет выполняться снова, либо даст те же результаты. Можно использовать операции удаления-записи (Delete-Write), записи-проверки-публикации (Write-Audit-Publish) или сравнения и слияния. Подробнее об этом позже.
- Дедупликация. При случайном повторном запуске конвейера данных или повторном запуске при сбое данные могут дублироваться. Убедитесь, что дублирование данных не происходит даже при повторном запуске. Здесь также помогут шаблоны из пункта 1.
- Наверстывание пропущенных данных. Конвейер должен иметь возможность наверстать данные за пропущенные дни. Одним из способов реализации этого является логирование того, что уже было загружено, и загрузка только тех новых данных, которые были созданы после этого.
- Перезагрузка данных. Конвейеры данных должны быть параметризованы таким образом, чтобы в случае необходимости перезагрузки данных в определенные дни конвейеры могли сделать это без каких-либо проблем или без дублирования данных. В этом могут помочь шаблоны, описанные в пункте 1, а также логирование, о котором шла речь в пункте 3.
Теперь вы не только создали конвейер данных, но и реализовали один из ключевых принципов проектирования конвейера данных. Можно расслабиться, передохнуть и перейти к решению следующей задачи.
Спринт 3. Добавление модульного тестирования
Добавление модульных тестов в конвейер приносит огромную пользу. Так в процессе производства ничего не нарушится и не возникнет простоев в работе.
- Написание тестируемого кода. Используйте лучшие практики программирования наряду с функциональным программированием для создания небольших фрагментов кода в виде функций. Небольшие модули кода обеспечивают тестируемость всех функций.
- Написание тестовых (контрольных) примеров. Определите различные тестовые примеры с высоким уровнем охвата. Определите исходные данные (образец) и ожидаемые данные. Напишите тестовые случаи, соответствующие этим данным.
- Автоматизация тестирования. Используйте процесс CI/CD для автоматического выполнения кодов модульных тестов, а также ноутбуки.
Спринт 4. Создание нескольких конвейеров на одних и тех же принципах
Зачастую создание полноценной системы анализа данных требует ввода данных из нескольких таблиц. Одним из способов решения этой задачи является создание отдельных конвейеров для каждой таблицы или нескольких динамических конвейеров, способных читать несколько таблиц. В любом случае часто приходится использовать один конвейер в качестве шаблона для создания нескольких конвейеров.
- Шаблонирование конвейеров. Убедитесь, что все компоненты конвейера написаны по модульному принципу, что позволяет создавать шаблоны, которые можно повторно использовать для нескольких конвейеров.
- Управление зависимостями. Любые зависимости должны создаваться в виде независимых конфигураций, классов или методов, чтобы их можно было использовать в разных конвейерах.
Спринт 5. Оркестровка и управление рабочими процессами
Все конвейеры должны быть встроены в оркестрованный рабочий процесс. Обычно создается основной конвейер, который запускает различные дочерние конвейеры на основе критериев успеха/неудачи/завершения.
Оркестровка конвейеров представляется в виде направленного ациклического графа (Directed Acyclic Graph, DAG). Для создания DAG можно использовать low-code/no-code инструменты или такие средства, как Airflow и Mage.
- Рабочий процесс с основными данными.
- Зависимость между дочерними конвейерами.
Спринт 6. Автоматизация конвейеров данных
После того как основные конвейеры готовы и протестированы, важно автоматизировать их.
- Планирование. Составьте график работы каждого конвейера на определенный срок, чтобы обеспечить его автоматическое выполнение по мере необходимости.
- Мониторинг. При несоблюдении графика работы конвейеров будут происходить сбои. Важно добавить надежный механизм оповещения на случай сбоя. Для хранения сообщений об ошибках можно использовать логирование. Важно последовательно контролировать выполнение конвейера и следить за тем, чтобы он не сбоил и перезапускался в срок.
- Автоматизация повторного запуска и попыток повторного запуска. Повторный запуск конвейера может происходить несколькими способами. Один из них — когда инженер техподдержки/обслуживания по вызову видит ошибку, выясняет ее первопричину и принимает решение о повторном запуске конвейера. Другой способ — автоматизация всего процесса повторного запуска. Повторно запустить конвейер можно на основе сообщения об ошибке. Кроме того, можно создать определенный набор правил для автоматического повторного запуска контейнера при возникновении ошибки, а также определить количество попыток повторного запуска.
После прохождения 6-го спринта у вас уже будет качественный результат, в котором реализованы лучшие практики, а также проведено тестирование на предмет корректности результатов. Вам удалось создать все конвейеры, необходимые для полноценного аналитического решения, а также автоматизировать процесс загрузки данных. Теперь можно запускать конвейеры несколько раз, наблюдать повторяющиеся сбои и находить закономерности в ошибках.
В следующих спринтах попробуем добавить больше функциональности, чтобы избежать повторяющихся сбоев в конвейерах.
Спринт 7. Качество данных и валидация
Качество данных — это важный аспект обеспечения их надежности. Предприятия будут использовать создаваемые вами информационные продукты только в том случае, если смогут доверять вашим данным и инсайтам. Поэтому очень важно внедрить инструмент по оценке качества данных (Data Quality Framework) в рамках конвейера данных.
Ниже приведены некоторые базовые задачи, которые можно выполнить для постепенного достижения базового уровня Data Quality Framework. Обратите внимание, что продвинутый проект предполагает множество нюансов при оценке качества данных, мы же знакомимся с основными понятиями.
- Определение метрик и правил качества данных. Определите все проверки качества данных и правила, обязательные к выполнению. Правила проверки данных могут быть следующими: номера телефонов должны состоять только из 10 цифр, идентификаторы электронной почты должны иметь формат xxxx@yyy.com, имя клиента не может быть null и т. д. Наряду с правилами проверки качества данных, необходимо также определить метрики качества данных, например точность адреса клиента должна составлять 90%, более 5% столбцов данных не должны содержать значений null и т. д.
- Автоматизация валидации данных. На основе правил качества данных необходимо написать в коде автоматические проверки. Эти проверки будут выполняться после загрузки данных, завершения их преобразования и т. д. Такая автоматическая валидация данных обеспечивает их целостность, непротиворечивость и точность. Также нужно добавить валидацию данных и при извлечении данных из источника.
- Мониторинг качества данных и оповещения. Результаты автоматизированных валидаций качества данных необходимо отслеживать для исправления ситуации. Для выявления неудачных результатов валидации качества должны быть предусмотрены оповещения. Если проблемы с данными возникают в самом источнике, необходимо оповестить об этом upstream-команды. Данные, не прошедшие валидацию, могут быть записаны в журналы ошибок и удалены из процесса загрузки данных.
Спринт 8. Непрерывная интеграция и непрерывное развертывание (CI/CD)
Контроль версий для совместной работы и CI/CD для непрерывного системного проектирования — чрезвычайно важный аспект инженерии данных. CI/CD в конвейере проекта по инженерии данных считается частью обработки данных. Поэтому вам необходимо ознакомиться с этими концепциями и хотя бы одним инструментом.
- Контроль версий и ветвление. Версионирование кода с помощью любого инструмента управления версиями кода (GIT) является практически необходимостью. Кроме того, правильная стратегия ветвления обеспечивает бесперебойную совместную работу разработчиков в команде. Поэтому добавьте весь код в GIT и используйте правильную стратегию ветвления для проверки, внесения изменений и слияния фрагментов кода.
- Автоматизация сборки. После внесения изменений необходимо внедрить автоматизацию сборки, чтобы при каждом изменении проект собирался автоматически, и все модульные тесты выполнялись автоматически. На этом этапе также следует убедиться, что встроены все необходимые DAG (Database Availability Group, группы обеспечения доступности баз данных). Используйте такие инструменты CI/CD, как Azure DevOps / GitHub Actions, для создания автоматических сборок для конвейера данных.
- Автоматизированное развертывание. После создания правильного ветвления и автоматической сборки необходимо рассмотреть возможность автоматического развертывания в средах более высокого уровня. В личном проекте вы можете не беспокоиться о различных средах, но в реальном вы будете разрабатывать и тестировать код в Dev-среде. Однако код для всех остальных сред более высокого уровня (test/stage/prod) должен автоматически разворачиваться с помощью CI/CD-конвейеров. Стоит позаботиться об “умной” разработке конвейера, чтобы он мог справиться с любой средой.
Спринт 9. Инфраструктура, представленная как код (IaC)
Важной частью конвейера CI/CD является также автоматическое развертывание всей инфраструктуры. Инфраструктура, представленная как код (IaC), — это относительно новый, но необходимый навык дата-инженеров.
- Представление инфраструктуры как кода. Все требования к инфраструктуре должны быть определены в виде кода/конфигурации с помощью YML-файлов. Инструменты IaC могут быть использованы для автоматического развертывания инфраструктуры из YML-файлов.
- Контроль версий для IaC. Как и обычный код и файлы конвейера, код или конфигурационные файлы IaC также необходимо отслеживать с помощью систем контроля версий, например GIT.
- Автоматизация предоставления ресурсов. Используйте такие инструменты, как Terraform, Ansible и Chef, для автоматического создания различных инфраструктур, таких как серверы/VM/программное обеспечение/облачные компоненты и т. д. Эти инструменты позволяют читать YML-файлы и создавать необходимую инфраструктуру.
К этому моменту у вас уже будет готовый сквозной конвейер производственного уровня. Инкрементный подход к разработке всего проекта позволит вам оставаться вовлеченным в процесс обучения.
Спринт 10. Масштабируемость и оптимизация
Любое программное обеспечение большую часть времени проводит в эксплуатации, а не в разработке. Как и в случае с любым другим ПО, создание конвейера данных занимает не более нескольких месяцев, но в реальной производственной среде он работает годами.
После запуска конвейера в производство возникают новые проблемы с данными. Одни из них требуют исправления, а другие нужно полностью переделывать.
При этом проблема, которая почти наверняка появится, — это узкие места в производительности. Данные в Dev-среде обычно слишком чистые и зачастую не дотягивают до объема производственных данных. Независимо от того, каков объем валидации и оптимизации был проделан в процессе разработки и тестирования, производственные данные и инфраструктура обязательно создадут проблемы с производительностью.
Здесь-то и пригодятся навыки по повышению производительности, оптимизации времени загрузки и масштабированию с учетом объема данных. Поэтому в качестве последнего шага начните добавлять оптимизацию и масштабируемость в конвейер.
- Стратегии масштабирования. Планируйте работу с растущими объемами данных, оптимизируя масштабируемость конвейера. Структура проекта должна быть модульной, чтобы ее можно было повторно использовать и масштабировать под любой объем данных.
- Настройка и оптимизация производительности. Выявление “узких мест” и оптимизация конвейера для повышения производительности.
- Управление кластерами. Если конвейеры работают в кластере, то в идеале кластер должен запускаться и работать только во время загрузки и преобразования данных. Когда работа не выполняется, кластер следует приостановить для экономии средств. В идеале необходимо создать автоматизированный процесс приостановки кластеров сразу после завершения процесса загрузки данных. Существуют и другие действия по управлению кластерами.
В двух словах о главном
Разработку проектов по инженерии данных следует выполнять инкрементно.
- Начните с создания MVP-конвейера.
- Добавьте идемпотентность, модульное тестирование, оркестровку.
- Реализуйте автоматическую сборку кода и инфраструктуры.
- Используйте CI/CD для автоматического развертывания.
- Выполните мониторинг, тестирование и оптимизацию.
Такой практический поэтапный подход поможет вам изучать различные концепции по мере продвижения. Небольшие постепенные шаги будут давать вам заряд адреналина каждый раз, когда вы будете вычеркивать из списка очередную выполненную задачу.
Читайте также:
- Принципы SOLID в инженерии данных. Часть 2
- 5 уникальных подходов Google к инженерии данных
- 8 структур данных, которые должен знать каждый дата-сайентист
Читайте нас в Telegram, VK и Дзен
Перевод статьи Saikat Dutta: How to Create First Data Engineering Project? An Incremental Project Roadmap





