
В начале 2020 года мне представилась уникальная возможность получить доступ к GPT-3 от OpenAI, новейшей языковой модели с поистине удивительными способностями. В процессе подробного изучения этой технологии я обнаружил множество способов использовать ее потенциал в личных и профессиональных целях. Она стала эффективным средством для быстрого решения задач и выявления новых подходов.
При этом вскоре выяснилось, что работать с GPT не так просто, как кажется. Несмотря на появление ChatGPT, призванного восполнить данный пробел и сделать эту инновационную технологию доступной широкой аудитории, пользователи по-прежнему нуждаются в полном понимании того, как максимально задействовать потенциал этого инструмента.
В последнее время я часто общался со многими инженерами и предпринимателями, которые внедряют языковые модели в свои сервисы и продукты. И мне довелось наблюдать одну повторяющуюся тенденцию — запрос ответов от языковых моделей в формате JSON. Однако я обнаружил серьезные последствия для качества вывода, обусловленные формулировкой, структурой текстовых подсказок и инструкций. Эти факторы могут существенно влиять на способность пользователя контролировать и настраивать вывод, генерируемый GPT и аналогичными языковыми моделями.
Исходя из личного опыта, я чувствовал, что JSON не является эффективным форматом для запрашиваемых ответов языковых моделей. Приведу аргументы:
- Проблемы с синтаксисом. Формат
JSONчувствителен к кавычкам, запятым и другим зарезервированным символам, что затрудняет последовательное выполнение инструкций языковыми моделями. - Приставка и суффикс в ответе. Языковые модели обычно обертывают вывод ненужным текстом.
- Чрезмерные затраты. Формат
JSONтребует открытия и закрытия тегов, создания лишних текстовых символов и увеличения общего количества токенов и затрат. - Крайне длительное время выполнения. Использование языковых моделей в приложении, особенно если оно ориентировано на клиента, может быть очень чувствительным ко времени отклика. Вследствие всех вышеперечисленных факторов применение
JSONможет обернуться замедленными и непредсказуемыми результатами с негативными последствиями для пользовательского опыта.
Наглядный эксперимент №1
Чтобы подтвердить свои предположения относительно JSON и сравнить его с YAML, проведем наглядный эксперимент.
Задача следующая: протестировать эффективность GPT при парсинге текста одинакового содержания. Для этого просим его cгенерировать простой список названий месяцев в формате JSON и сравниваем его с форматом YAML. Сравнение осуществляется с помощью инструмента Tokenizer от OpenAI (более подробная информация о токенах в следующих разделах). Этот простой пример показывает, что формат YAML сокращает затраты на 50%:

Очевидно, что в данном случае YAML намного более эффективен с точки зрения затрат и времени, чем JSON.
Наглядный эксперимент №2
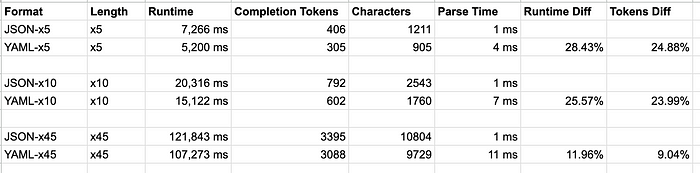
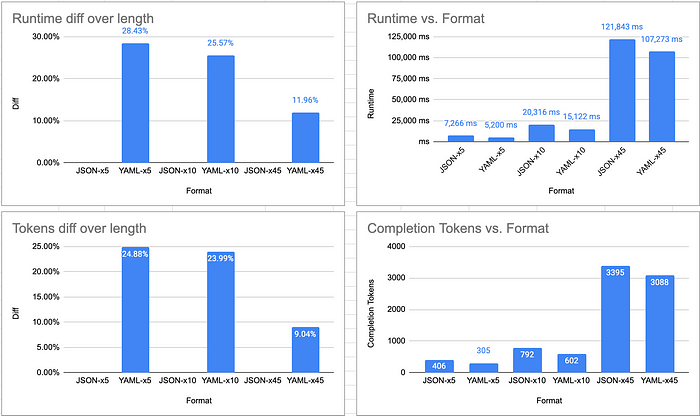
Теперь определим время выполнения большего объема токенизации и выявим разницу в показателях парсинга вывода JSON и YAML.
Воспользуемся пакетом js-yaml для парсинга вывода в объекты JS и PyYAML для Python.
Применяем следующую инструкцию для генерации детерминированного тестового набора с предопределенной структурой и измеренными результатами при различных объемах токенизации (x5, x10 и x45, занимающих все контекстное окно токенов):
Сгенерируй базовую демографическую информацию о 10 ведущих странах (по численности населения). Она должна включать следующие поля: страна, население, столица, официальный_язык, валюта, площадь_км, ввп_usd, в корневой папке «страны». Вывод в формате {{format}}, сократить другой текст. (формат: YAML|JSON)
Полученные результаты:
Итоговые выводы JSON и YAML представлены в соответствующих репозиториях GitHub по указанным ссылкам.
Допустим, вы задействуете данную инструкцию в масштабе 1 миллион запросов в месяц, используя JSON и GPT-4. В этом случае простой трюк с переходом на YAML сэкономит 190 токенов и 11 400 $ в месяц (с учетом стоимости на момент выхода статьи).
Объяснение результатов экспериментов
Выясним, почему так происходит. Для этого нужно разобраться, как языковые модели преобразуют текст в токены, а токены обратно в текст.
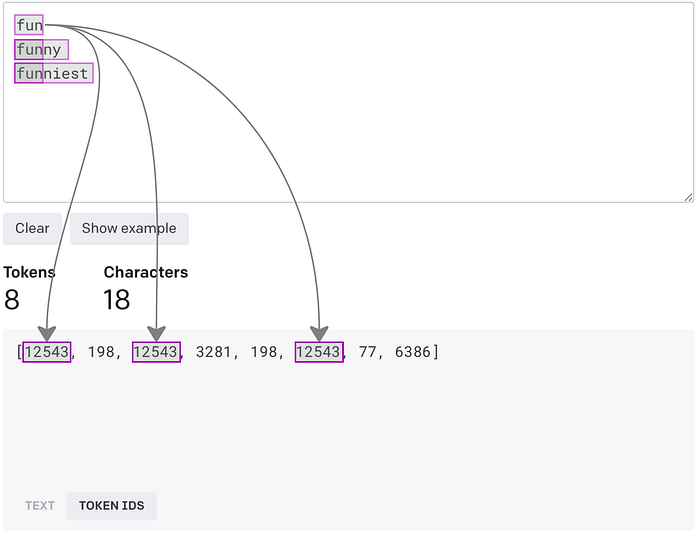
Языковые модели — это модели машинного обучения, а машины не понимают “слова” как цельный текст. Поэтому слова кодируются в представления для последующей обработки. Каждое слово представлено уникальным ID, который распознается машиной. Данный процесс обычно называется “кодированием на основе индексов”. Но его нельзя назвать эффективным, поскольку близкие по значению однокоренные слова, например “fun” (забава), “funny” (забавный) и “funniest” (забавнейший), будут представлены совершенно разными и отличными друг от друга ID.
В 1994 году Филипп Гейдж ввел в практику новый метод сжатия данных. Этот метод заменяет частые пары последовательных байтов на один байт, который не встречается в данных. Иначе говоря, разделение слов на части позволяет представлять их уникальными ID токенов, эффективно их сохранять и извлекать. Данный алгоритм называется Byte Pair Encoding (BPE), т.е. кодирование пар байтов, и применяется для токенизации на подслова. Он лег в основу таких моделей, как BERT, GPT, RoBERTa и многих других.
Возьмем для примера токен est в словах “estimate” (оценивать) и “highest” (наивысший), где est встречается в начале или в конце слова в разных значениях. Чтобы правильно его обработать, алгоритм BPE объединяет пары двух байтов или части слов.
Обратимся за помощью к инструменту Tokenizer и покажем наглядно:
Когда алгоритм сталкивается с одиночными символами, такими как фигурные кавычки, происходит нечто интересное:
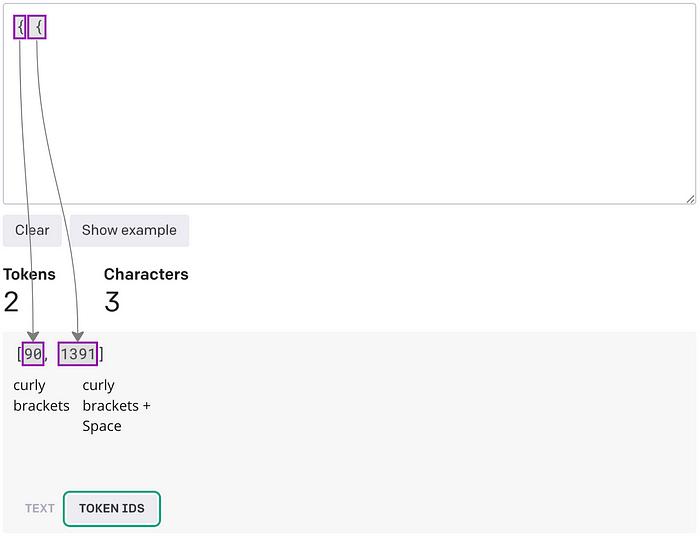
Такое фундаментальное поведение само по себе отлично вписывается в структуру YAML, где разрывы строк и пробелы представлены в виде специальных символов и нет необходимости открывать и закрывать фигурные скобки, кавычки и запятые. А JSON, в отличии от YAML, требует открытия и закрытия тегов. Эта процедура влияет на базовое представление в токенах, что приводит к дополнительным циклам больших языковых моделей (LLM) и сказывается на общей способности выполнять инструкции. Таким образом, формат YAML не только экономит символы, но и в целом помогает языковым моделям представлять слова в виде ID токенов, которые чаще всего встречаются в словаре BPE.

При сравнении JSON и YAML мы видим непоследовательное распределение токенов в JSON и более организованную структуру YAML. Теоретически формат YAML повышает способность LLM фокусироваться больше на содержании, чем на структурных аспектах, что в результате улучшает качество вывода в целом.
В заключении отметим, что JSON превосходит YAML в скорости парсинга и использования. При этом YAML намного эффективнее JSON в плане временных и ресурсных затрат. Кроме того, он помогает языковым моделям быстрее и дешевле генерировать то же самое содержание. По сути, эффективнее запрашивать YAML и преобразовывать результат в JSON на стороне кода, чем напрямую запрашивать JSON. Стоит сказать, что потенциальный компромисс достижим за счет строгости JSON для некоторых форматов (числа могут выводиться в виде строк, заключенных в кавычки). Для этого следует предоставить схему или преобразовать поля в правильный тип данных. В любом случае рекомендуется преобразовывать типы данных на стороне кода.
Бонусный раздел: подсказки по цепочке рассуждений с комментариями YAML
Помимо преимуществ в скорости и затратах, YAML обладает еще одной превосходящей JSON способностью — включать комментарии. Рассмотрим классический тестовый пример на основе метода подсказок по цепочке рассуждений (англ. Chain-of-Thought Prompting, CoT), развивающих у LLM способность к логическому мышлению:
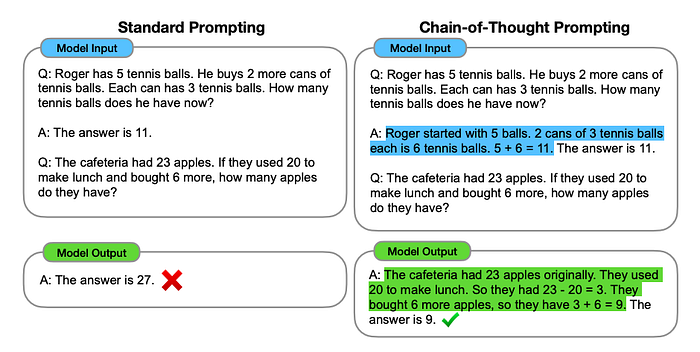
(слева) Стандартный способ составления инструкций
Вопрос: У Роджера 5 теннисных мячей. Он купил еще 2 банки с мячами, в каждой из которых по 3 мяча. Сколько мячей теперь у Роджера?
Ответ: Ответ — 11.
Вопрос: В буфете 23 яблока. Если потратить 20 яблок на приготовление обеда и докупить еще 6 яблок, сколько яблок останется буфете?
Вывод модели:
Ответ: Ответ — 27. Неправильно.
(справа) Составление инструкций на основе метода подсказок по цепочке рассуждений
Вопрос: У Роджера 5 теннисных мячей. Он купил еще 2 банки с мячами, в каждой из которых по 3 мяча. Сколько мячей теперь у Роджера?
Ответ: Сначала у Роджера было 5 мячей. 2 банки по 3 мяча в каждой получается 6 теннисных мячей. Итого: 5+6=11. Ответ — 11.
Вопрос: В буфете 23 яблока. Если потратить 20 яблок на приготовление обеда и докупить еще 6 яблок, сколько яблок останется буфете?
Вывод модели:
Ответ: Изначально в буфете было 23 яблока. Потрачено на приготовление обеда 20. Итого: 23–20 = 3. Затем было докуплено еще 6 яблок. Итого: 3+6=9. Ответ — 9.
Допустим, нужно получить вывод в машиночитаемом формате. JSON и отсутствие CoT приведут к неверному результату:
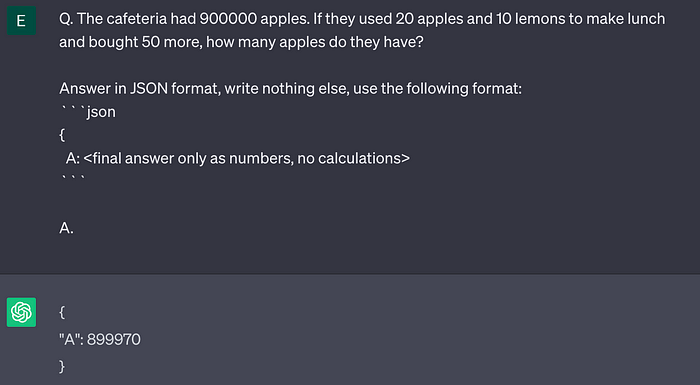
Вопрос: В буфете 900 000 яблок. Если потратить 20 яблок и 10 лимонов на приготовление обеда и докупить еще 50 яблок, сколько яблок останется в буфете?
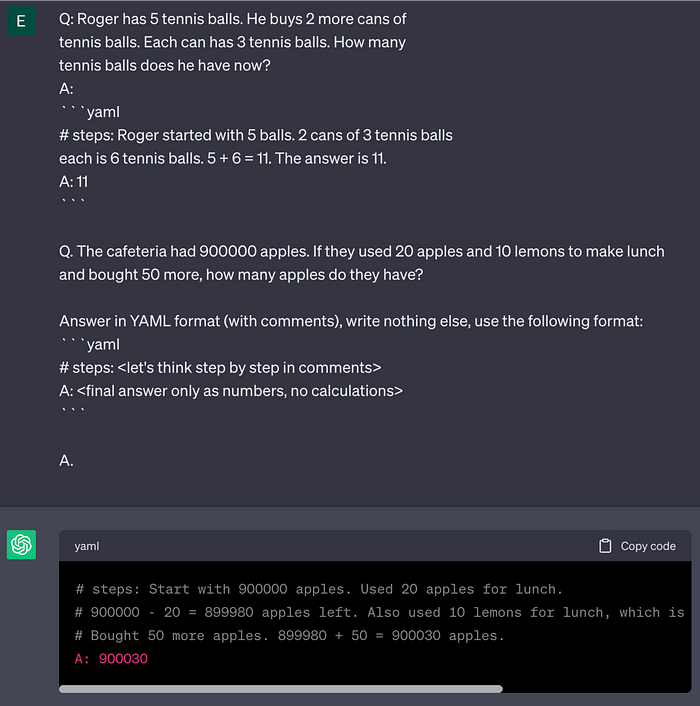
Используя YAML, мы можем определить формат, который содержит CoT в комментариях и представляет итоговый ответ в заданном ключе. В результате генерируется правильный вывод:
Читайте также:
- Как создать простой агент с Guidance и локальной моделью LLM
- Как усилить электронные таблицы Google возможностями ChatGPT
- Большой языковой модели недостаточно: пример использования Merkle Genai. Часть 2
Читайте нас в Telegram, VK и Дзен
Перевод статьи Elya Livshitz: YAML vs. JSON: Which Is More Efficient for Language Models?





