
В статье мы поговорим о библиотеке structlog и узнаем, как она помогает писать качественные логи. Такие логи содействуют ежедневной работе программиста и способствуют внедрению эффективных практик для обеспечения последовательного подхода к логированию во всем проекте.
Помимо этого, рассмотрим распространенные проблемы логирования и способы их решения посредством structlog. Материал будет интересен как для начинающих, так и для опытных разработчиков, поскольку данный инструмент способен кардинально изменить процесс написания логов!
Когда-то я часто пренебрегал логами и писал их только тогда, когда они помогали в среде разработки. Логи служили эффективным средством для обнаружения ошибок или проверки надлежащей работы кода, но их польза ограничивалась только локальной отладкой.
После освоения structlog я научился писать логи, которые не только помогают в повседневной работе, но и обязывают применять качественные практики для обеспечения согласованного подхода к логированию.
Как результат, упрощается парсинг логов для поставляемого приложения и улучшается мониторинг в таких инструментах, как Datadog и Grafana.
В статье я поделюсь опытом работы со structlog и продемонстрирую ее возможности на примерах. Допустим, пользователь намерен загрузить файлы, и мы уже создали конечную точку, принимающую эти запросы. В прошлом я бы написал логи таким образом:
import logging
...
logging.debug("Start uploading file with name %s. Number of retries: %s", file_name, 0)
...
logging.error("Failed uploading file with name %s. Current retry: %s.", file_name, retries)
...
С данным фрагментом кода все в порядке, и он выдает следующие логи:

Эти две строки логов описывают, что происходит во время запроса. Однако можно было бы улучшить нотацию повторных попыток, добавить больше контекста и повысить читаемость строк логов.
Классические проблемы логирования
Прежде чем перейти к практической части, рассмотрим распространенные проблемы логирования на основе вышеуказанного примера.
1. Отсутствие контекстной информации
Строка лога совершенно верно сообщает, что не удалось загрузить my_file. Этой информации может быть достаточно для среды разработки, в которой: 1) только один пользователь и один клиент отправляют запросы; 2) данные хранятся в локальной файловой системе; 3) все запросы выполняются последовательно.
Однако при обнаружении такого лога в системе продакшн могут возникнуть типичные вопросы:
- Кто отправил этот запрос?
- К какой организации принадлежит пользователь?
- К какому файловому хранилищу мы подключились? Существует ли идентификатор сеанса или что-то еще, что поможет отследить ошибку?
- Связана ли данная строка лога с идентификатором запроса?
Для получения требуемых сведений придется в каждую строку лога добавлять эту дополнительную информацию, а в худшем случае несколько раз извлекать одно и то же значение из базы данных, чтобы внести этот информационный контекст во всю базу кода.
2. Переход от логов разработки к машиночитаемым логам
В зависимости от среды строки лога в системе продакшн должны предоставляться в понятном для человека виде и машиночитаемом формате. Следует подсчитать общее количество повторных попыток или выбрать имя незагрузившегося файла в развертывании продакшн. В данном сценарии необходимо провести сопоставление подстрок. Намного проще написать запросы, позволяющие фильтровать события по образцу SQL:
select file_name from logs where retry_count > 1
3. Непоследовательные формулировки
Бывает, что в одном и том же модуле Python строки логов выглядят совершенно по-разному. Порой теряется важная информация. В зависимости от автора строки логов могут сильно отличаться. По-разному именуются сущности, значения переменных добавляются в лог с кавычками или без, меняются формулировки в рамках всего модуля.
Все это усложняет поиск событий и занимает много времени.
Structlog
Structlogрасполагает множеством отличных функциональностей, позволяющих быстро и безболезненно писать логи. Данная библиотека помогает добавлять в логгер контекстные данные и предлагает модульную конфигурацию для парсинга строк лога в машиночитаемый и человекочитаемый формат.
В нашем случае это приносит ряд бонусов: мы получаем красивые разноцветные строки логов в среде разработки и парсированный JSON для мониторинга; добавляем имена файлов в качестве контекстных данных; работаем с более удобными функциональностями. Несмотря на то что можно настроить нативный логгер на логирование в формате JSON, structlog такую возможность предусматривает по умолчанию.
Шаг 1. Замена нативного логгера Python на structlog
Используем structlog для вышеуказанного фрагмента кода. Мы должны получить логгер и добавить переменные в сообщения лога. Код выглядит следующим образом:
import structlog
logger = structlog.get_logger()
...
logger.debug("Start uploading file.", file_name=file_name,retries=0)
...
logger.error("Failed uploading file.", file_name=file_name,retries=retries)
...
В первую очередь отмечаем, что переменные больше не загружаются в строку, а являются kwargs методов debug и error. Такой прием не только добавляет значения этих переменных в логгер, но также привязывает имена ключей к сообщению лога. Получившиеся строки лога:

Сравнение с предыдущим примером показывает, что имя файла и повторные попытки добавляются в строки лога путем сопоставления значений ключей, а не посредством вставки значений в виде необработанной строки.

Шаг 2. Привязка контекстных данных к логгерам
structlog позволяет добавлять контекстные данные двумя способами.
1. Явная привязка переменных путем вызова .debug(…). Обновим предыдущий фрагмент кода. Для этого привяжем file_name к логгеру и используем экземпляр логгера для вывода сообщений лога:
import structlog
logger = structlog.get_logger()
...
log = logger.bind(file_name=file_name)
log.debug("Start uploading file.", retries=0)
...
log.error("Failed uploading file.", retries=retries)
...
Действуя таким образом, мы удаляем имя файла из всех строк лога и перемещаем его в верхнюю часть, где он вызывается один раз. Structlog самостоятельно добавляет его в каждую строку лога.
2. Неявная привязка контекстных переменных путем вызова structlog.contextvars.bind_contextvars(…). Эта функция задействует контекстные переменные каждый раз, когда логгер в том же потоке выводит сообщения лога. Рассмотрим фрагмент кода, который выводит те же самые сообщения лога с помощью контекстных переменных:
# /controller/file.py
import structlog
logger = structlog.get_logger()
...
structlog.contextvars.bind_contextvars(file_name=file_name)
logger.debug("Start uploading file.", retries=0)
...
logger.error("Failed uploading file.", retries=retries)
Однако данный сценарий отличается от предпочтительного варианта использования контекстных переменных для добавления значений в логгер. В разделе о проблемах логирования уже упоминалось, что классический подход часто подразумевает включение контекстных данных. Перед обработкой файла предусматривается действие механизма аутентификации и авторизации. Он проверяет возможность получения пользователем доступа к конечной точке. Во фреймворках по типу FastAPI эта рабочая нагрузка обрабатывается промежуточным ПО (англ. middleware). Поскольку мы уже получили ID пользователя для аутентификации запроса, добавляем эту пару “ключ-значение” в логгер:
# /auth/middleware.py
def verify_user(request: Request) -> bool:
if not validate(request.token):
return False
user_id = get_user_id(request.token)
structlog.contextvars.bind_contextvars(user_id=user_id)
return True
Таким образом structlog самостоятельно вносит эту контекстную информацию, избавляя нас от забот по добавлению ID пользователя вручную.
Шаг 3. Конфигурация для машиночитаемых логов
К этому моменту мы узнали, как добавлять информацию в строки лога с помощью structlog. Теперь нужно настроить ее так, чтобы в локальную среду разработки она отправляла красиво оформленные строки лога, а в сервис логирования — парсированный JSON. Воспользуемся первым и самым простым решением из документации structlog. Но сначала разберем две концепции из structlog: препроцессоры (англ. preprocessor) и рендереры (англ. renderer).
Препроцессоры расширяют содержимое сообщений лога. Осуществляется это путем добавления временных меток, изменения полей для сокрытия имен пользователей или удаления строк лога на основе определенных условий.
Рендереры управляют представлением строк лога. В зависимости от ситуации они могут отображать красивые и разноцветные строки лога или машиночитаемый JSON.
Возможность писать пользовательские реализации этих узлов обеспечивает высокий уровень расширяемости.
Воспользуемся предустановленными препроцессорами structlog для определения содержимого строк лога. Следующая схема показывает, как обрабатывать строки лога, применяющие логгер structlog. После этапа вывода (output) в зависимости от среды разработки мы добавляем рендерер, который форматирует строки лога в человекочитаемый или машиночитаемый вывод.
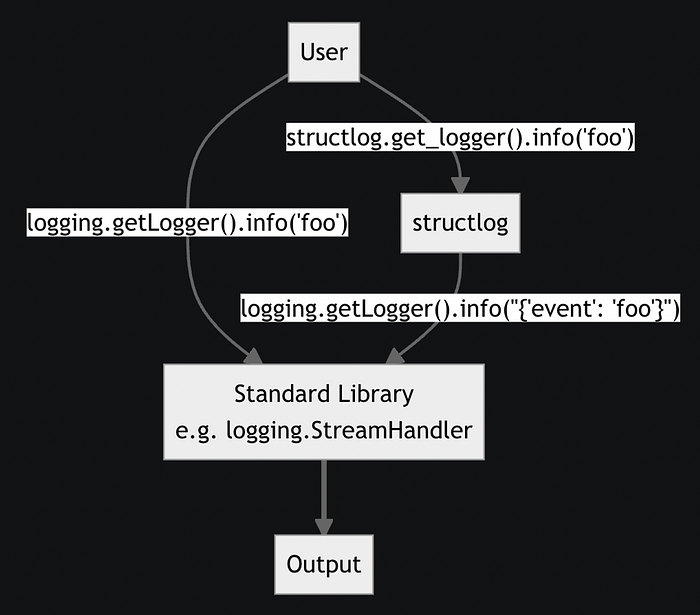
Сначала настраиваем набор препроцессоров, которые добавляют временные метки, устанавливают уровень лога и объединяют контекстные переменные из шага 2:
import structlog
from structlog.dev import ConsoleRenderer
from structlog.processors import JSONRenderer
# Препроцессор timestamper для добавления единых временных меток в каждый лог
timestamper = structlog.processors.TimeStamper(fmt="iso", utc=True)
# Препроцессоры Structlog
structlog_processors = [
structlog.stdlib.add_log_level
structlog.processors.add_log_level,
structlog.contextvars.merge_contextvars,
structlog.processors.StackInfoRenderer(),
structlog.dev.set_exc_info,
timestamper,
]
Теперь определяем функцию, которая возвращает ConsoleRenderer или JSONRenderer библиотеки structlog в зависимости от настроек среды, и добавляем этот рендерер к препроцессорам.
# __init__.py
from structlog.dev import ConsoleRenderer
from structlog.processors import JSONRenderer
def get_renderer() -> Union[JSONRenderer, ConsoleRenderer]:
"""
Get renderer based on the environment settings
:return structlog renderer
"""
if os.get("DEV_LOGS", True):
return ConsoleRenderer()
return JSONRenderer()
## Structlog
structlog.configure(
processors=structlog_processors + [get_renderer()],
wrapper_class=structlog.stdlib.BoundLogger,
context_class=dict,
logger_factory=structlog.PrintLoggerFactory(),
cache_logger_on_first_use=False,
)
Примечание. Это повлияет только на строки лога, выводимые внутри приложения, и не затронет логи, которые создаются модулями приложения. Если требуется отформатировать эти логи как
JSON, то воспользуйтесь инструкциями руководства 3 в документацииstructlog.
После установки переменной среды DEV_LOGS в значение False строки лога выводятся как необработанный JSON.

Теперь мы можем использовать данный формат в системе мониторинга, легко выполнять его парсинг и агрегацию, поскольку он уже является не потоком текста, а потоком удобного для парсинга JSON.
В локальной среде по-прежнему остается возможность работать с разноцветными строками лога:

Ограничения
Сама по себе библиотека structlog не решает всех противоречий логирования. Но зато она помогает наладить более последовательный и защищенный от ошибок рабочий процесс.
Для обеспечения целостности базы кода мы используем набор стандартных соглашений об именовании. Их никто не заставляет применять, но они проясняют подход к написанию логов.
<entity>_id← (обязательно) каждая обрабатываемая сущность (например, файл) должна добавляться в логгер.<entity>_name← (необязательно) каждая сущность (например, файл) может добавляться с суффиксом_nameдля удобочитаемости.<entity>_<additional_key>← (обязательно) разрешается добавлять дополнительные свойства сущностей с именем ключа в качестве суффикса.<custom_usecase_specific_field>← (необязательно) Иногда необходимо добавить информацию, присущую конкретному случаю. Тогда вы можете задействовать дополнительные произвольные ключи. Однако по мере возможности следует соблюдать соглашения об именовании из пунктов 1–3.
Это не единственный способ именования, но зато он больше всего подходит для нашего случая.
Заключение
По итогам изучения материала статьи мы узнали следующее:
- Использование формата “ключ-значение” для переменных помогает создавать единообразные сообщения лога и способствует соблюдению согласованных соглашений об именовании.
- Контекстные данные можно добавлять явно и неявно. В первом случае мы привязываем переменные к логгеру, а во втором — применяем контекстные переменные, которые наполняют строки лога полезными метаданными.
- Выбор рендерера
structlogпозволяет легко выполнять парсинг строк лога в машиночитаемый или человекочитаемый формат в зависимости от среды.
Читайте также:
- 7 лучших CLI-библиотек Python в 2023 году
- История путешествий вместе с Plotly Express
- 4 бесплатные игры для изучения Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи Kristof: Writing Professional Python Logs





