
Краткое содержание
- Включаем расширение pg_trgm.
- Добавляем триграммный индекс в столбцах, где выполняется полнотекстовый поиск.
class AddTrigramIndex < ActiveRecord::Migration[6.0]
disable_ddl_transaction!
def change
enable_extension :pg_trgm
add_index :table, :column, opclass: :gin_trgm_ops, using: :gin,
algorithm: :concurrently, name: ‘index_trgm’
end
end
Если все понятно, то переходите к следующей статье. Хотите досконально разобраться, как значительно доработать производительность поиска? Читайте дальше.
Введение
Что самое лучшее в разработке ПО? Оптимизация кода, запросов, моделей данных, исправление показателей скорости Google…
Когда что-то подобное попадает вам в руки, вы должны прыгать от счастья. Нигде не делаешь так мало (обычно), чтобы добиться таких больших изменений для конечного пользователя!
Разберемся, как же доработать функцию поиска на дашборде приложения. Пока оно небольшое, производительность этой функции — не проблема:
def search(query)
Post.where("body ILIKE (?)", "%#{query}%")
end
Постов немного, и последовательное сканирование достаточно быстрое. Но для приложения побольше этот запрос слишком медленный — нужно исправить.
Что такое «триграммный индекс»?
Это разновидность обратного индекса для эффективного поиска строк в больших таблицах, но без точного поискового запроса.
Триграммными индексами повышается эффективность соответствия подстроки и соответствия по сходству — за счет индексирования уникальных триграмм строки.
Но что такое «триграмма» и «обратный индекс»?
Триграмма — это три последовательных символа в строке:
SELECT show_trgm('trigram');
show_trgm
-------------------------------
{" t"," tr","am ",gra,igr,ram,rig,tri}
Обобщенный обратный индекс, или GIN-индекс, предназначен для работы с типами разделяемых данных. В индексе хранится ключ и ссылка, где это значение встречается.
GIN-индексы — это как оглавление книги, в котором в качестве номеров страниц используются heap-указатели на саму таблицу. Для получения определенного результата записи объединяются, как при поиске «компенсационных акселерометров» в этом примере:
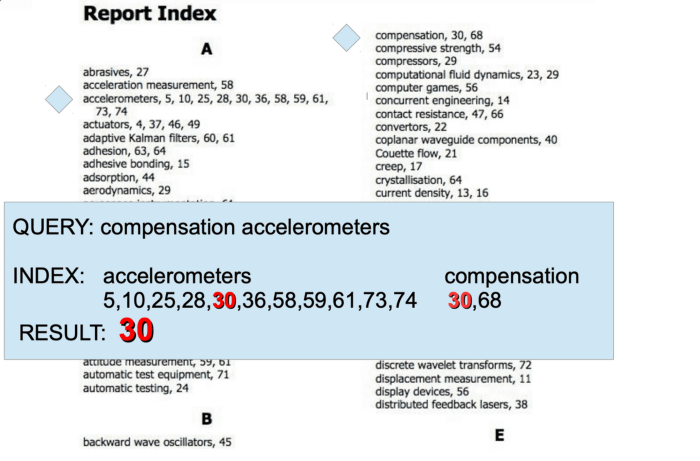
Допустим, в таблице постов у нас имеется индексированный столбец body, а тело поста — это строка Trigram Index:
SELECT show_trgm('Trigram Index');
-----------------------
{" i"," t"," in"," tr","am ",dex,"ex ",gra,igr,ind,nde,ram,rig,tri}
Всеми подстроками Trigram Index указывается на запись поста. Когда делается запрос на соответствие ключевому слову gram, в базе данных это слово делится на триграммы и выполняется сканирование Bitmap Index Scan с сопоставлением их с триграммами в индексе:
SELECT show_trgm('gram');
-----------------------
{" g"," gr", "am ", gra, ram}
-------------match--match-match
Триграммные индексы со сравнениями еще эффективнее.
В столбцах STRING ими поддерживаются следующие операторы сравнения.
- Равенство:
=. В поисках на равенство работа стандартных вторичных индексовbtreeможет быть лучше триграммных. - Сопоставление с образцом (учитывается регистр):
LIKE. - Сопоставление с образцом (учитывается регистр):
ILIKE. - Соответствие по сходству:
%. Этим оператором возвращаетсяtrue, если в строках в сравнении имеется сходство, превышающее пороговое значение или соответствующее ему.
Один из недостатков всего этого — в больших таблицах записи медленнее.
Триграммный индекс в действии
Для примера возьмем 40 000 пользователей в базе данных и запустим простой запрос ILIKE по их почте:
SELECT "users".* FROM "users" WHERE users.email ILIKE ('%emir%');
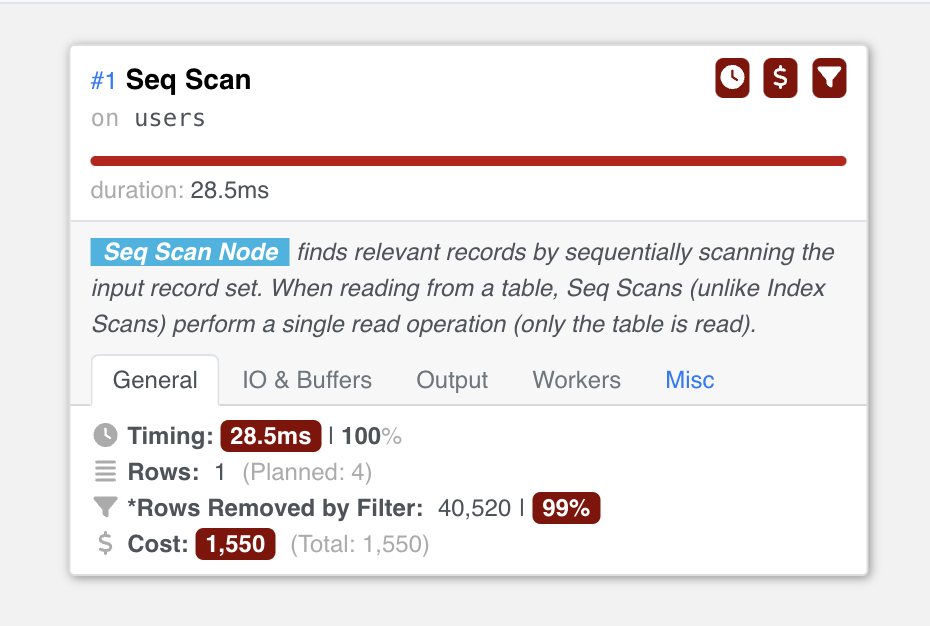
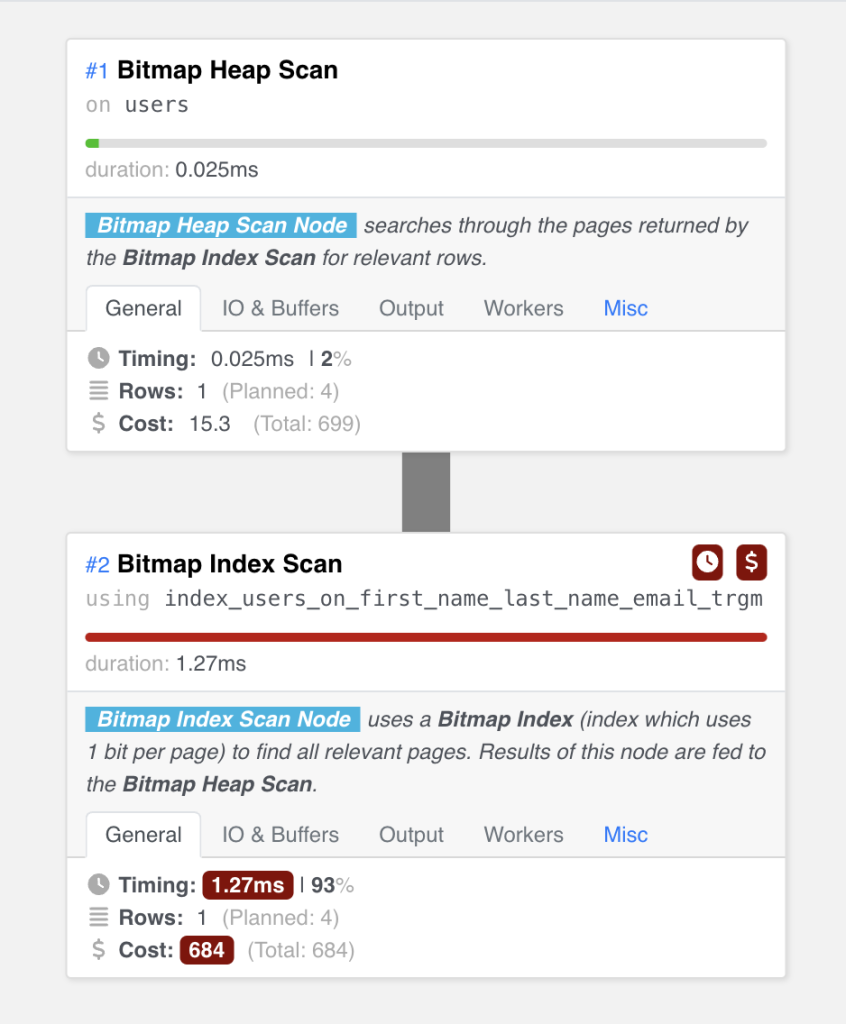
Разница в столбцах с почтой очень заметна — даже в таком маленьком и простом наборе данных. В больших наборах данных со столбцами покрупнее или в запросах посложнее, где поиск выполняется по нескольким полям, результаты будут куда значительнее.
Заключение
Включение расширения pg_trgm и добавление триграммного индекса — простой и эффективный способ повышения производительности запросов LIKE и ILIKE в PostgreSQL. Применяя специализированную структуру данных и алгоритмы триграммных индексов, вы обеспечиваете быстроту и эффективность выполняемых запросов, а значит — бо́льшую удовлетворенность пользователей.
Читайте также:
- Оптимизация работы баз данных с PostgreSQL 12
- PostgreSQL вместо Kafka: способ реализации системы очередей
- Python FastAPI: OpenAPI, CRUD, PostgreSQL в Docker и внедрение зависимостей
Читайте нас в Telegram, VK и Дзен
Перевод статьи Emir Vatric: Simple Trick for Lightning-Fast LIKE and ILIKE Queries





