
PostgreSQL претендует на звание самой передовой базы данных с открытым исходным кодом в мире, и вполне заслуженно. Основные технические возможности, производительность и рабочие характеристики позволяют относить ее к числу ведущих баз данных для коммерческого использования, делая ее очень подходящей, экономически эффективной альтернативой как для стартапов, так и для крупных компаний, которым необходимо хранить данные и осуществлять управление ими.
Постараемся здесь дать исчерпывающее, развернутое представление об этой замечательной системе управления базами данных — от установки, настройки, резервного копирования и восстановления с помощью barman 2.11 и до репликации и переключения с использованием repmgr 5.0.0 на Ubuntu 20.10. Акцент, впрочем, сделаем на достижении конкретных результатов, целей и задач. Поэтому особое внимание уделим соответствующим этапам и командам, оставив в стороне фоновые сведения и подробные объяснения.
Введение
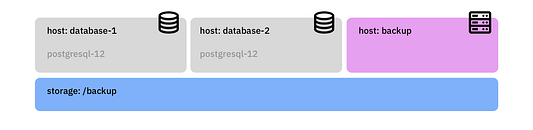
Задействуем три физических компьютера или три виртуальные машины (database-1, database-2 и backup). Каждый компьютер или машину запускаем на ubuntu 20.10 и подключаем к подсоединенному хранилищу, смонтированному в /backup:
Установка
Начальная настройка инфраструктуры
Убедитесь, что DNS правильно сконфигурирован на каждой из машин — наше руководство будет ссылаться не на IP-адреса, а только на имена хостов.
Установка Postgres
- Устанавливаем закадычных друзей:
sudo apt -y install vim bash-completion wget joe. - Теперь обновляем определения пакетов apt:
apt-get update. - Устанавливаем postgresql 12:
apt install postgresql. - Устанавливаем интерфейс командной строки barman:
apt install barman-cli. - Проверяем состояние запущенной службы:
systemctl status postgresql.service. - Проверяем подключение postgres:
su - postgres. - Даем пользователю postgres более надежный пароль:
psql -c "alter user postgres with password 'MyStrongAdminP@ssw0rd'". - То же самое проделываем на уровне ОС (с тем же паролем). Выполняем с правами администратора
passwd postgres. - Затем перезагружаем машину.
- Повторяем эти пункты для машины
database-2. - На обоих серверах баз данных от имени пользователя
postgresсоздаем файл~/.bash_rcи добавляем следующее содержимое:
PATH=$PATH:/usr/lib/postgresql/12/bin
alias l='ls -al --color=auto'
- И добавляем эти строчки привилегированному пользователю
rootв~/.bashrcна обоих серверах.
Конфигурация Postgres
- конфигурируем
/etc/postgresql/12/main/postgresql.confследующим образом:
# прослушиваем любое устройство машины и ее IP-адрес
listen_addresses = '*'
# включаем режим архивации и настраиваем архивацию WAL-журнала barman rsync
archive_mode = on
archive_command = 'rsync -a %p barman@backup:/backup/barman/database-1/incoming/%f'
wal_level = replica
# закомментируем include_dir: это предотвратит запуск сервера во время восстановления
# include_dir = 'conf.d'- редактируем
/etc/postgres/12/main/pg_hba.confи добавляем следующие строки (здесь уже содержится конфигурация репликации, которая потом понадобится дляrepmgr):
host all all <your-c-net> trust
host repmgr repmgr <your-c-net> trust
host replication repmgr <your-c-net> trustSQLite: как организовывать таблицы
- создаем начальную структуру базы данных (на этом этапе она может быть любой).
Настройка резервного копирования и восстановления с помощью barman
- Запускаемся с нового сервера резервного копирования на ubuntu 20.10.
- В
backupустанавливаем barman:apt-get install barman barman-cli. - Создаем закрытый ключ для пользователя postgres и пользователя barman в
database-1иbackupсоответственно. - В
database-1меняем на пользователя postgressu - postgresи генерируем пару ключей:ssh-keygen -b 2048 -t rsa -N "" -C "postgres@database-1". - В
database-2меняем на пользователя postgressu - postgresи генерируем пару ключей:ssh-keygen -b 2048 -t rsa -N "" -C "postgres@database-2". - В
backupменяем на пользователя barmansu - barmanи создаем пару ключей:ssh-keygen -b 2048 -t rsa -N "" -C "barman@backup". - Добавляем открытый ключ postgres и barman соответственно к
~/.ssh/authorized_keys:
on database-1 as postgres : cat <database-2.server id_rsa.pub> >> ./ssh/authorized_keys
on database-1 as postgres : cat <backup.server id_rsa.pub> >> ./ssh/authorized_keyson database-2 as postgres : cat <database-1.server id_rsa.pub> >> ./ssh/authorized_keys
on database-2 as postgres : cat <backup.server id_rsa.pub> >> ./ssh/authorized_keyson backup as postgres : cat <database-1.server id_rsa.pub> >> ./ssh/authorized_keys
on backup as postgres : cat <database-2.server id_rsa.pub> >> ./ssh/authorized_keys- С каждой из машин подключаем одну к другой, используя соответствующее имя пользователя и полное имя хоста:
from database-1 as postgres user : ssh barman@backup
from database-1 as postgres user : ssh postgres@database-2
from database-2 as postgres user : ssh barman@backup
from database-2 as postgres user : ssh postgres@database-1
from backup as barman user : ssh postgres@database-1
from backup as barman user : ssh postgres@database-2
Таким образом соответствующие хосты будут добавлены в файл known_hosts, необходимый для правильной работы barman- В
backupперемещаем файл/etc/barman.confв/etc/barman.conf.origи воссоздаем его со следующим содержимым:
[barman]
barman_home = /backup/barman
barman_user = barman
log_file = /backup/barman/barman.log
compression = gzip
reuse_backup = link
backup_method = rsync
archiver = on
immediate_checkpoint = true
basebackup_retry_times = 3
basebackup_retry_sleep = 30
last_backup_maximum_age = 1 DAYS
[database-1]
description = "database-1"
ssh_command = ssh postgres@database-1
conninfo = host=database-1 user=postgres port=5432
retention_policy_mode = auto
retention_policy = RECOVERY WINDOW OF 7 days
wal_retention_policy = main
backup_options = exclusive_backup
[database-2]
description = "database-2"
ssh_command = ssh postgres@database-2
conninfo = host=database-2 user=postgres port=5432
retention_policy_mode = auto
retention_policy = RECOVERY WINDOW OF 7 days
wal_retention_policy = main
backup_options = exclusive_backup- Настраиваем входящие в WAL — в
backupполучаем этот каталог сbarman show-server database-1 | grep incoming_wals_directory: should beincoming_wals_directory: /backup/barman/database-1/incoming. - Убеждаемся, что этот путь такой же, как и на postgresql.conf в
archive_command. - Выводим список всех доступных серверов резервного копирования:
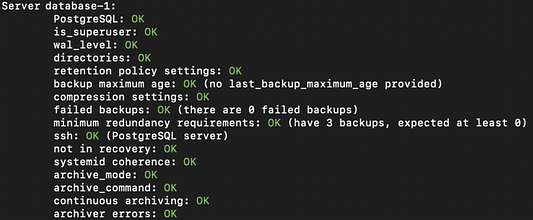
barman list-server. - Проверяем архивацию WAL-журнала и все остальные части нашего сервера:
barman check database-1.
- Тестируем архивацию WAL-журнала с
barman switch-wal --force --archive database-1. - Если видите строку
WAL archive: FAILED (please make sure WAL shipping is setup), это означает одно из трех: 1) возможно, база данных еще не создала никаких файлов в WAL; 2) они уже были удалены; 3) rsync не работает. Загляните в логи PostgreSQL: там все ответы.
Но если rsync работает правильно и никаких данных в базу данных фактически не записывается, то сервер не будет выдавать никаких WAL-файлов. Стало быть, резервную копию создавать не из чего. WAL-файлы создаются после получения определенного объема данных. Рекомендую создать таблицу и добавить в нее данные. Для принудительного закрытия текущего WAL-файла используйте: barman switch-wal --force --archive database-1.
- Создаем базовую резервную копию:
barman backup database-1. - Выводим список всех имеющихся резервных копий для одного сервера
barman list-backup database-1:
barman@backup:~$ barman list-backup database-1
database-1 20210209T115342 - Tue Feb 9 11:53:45 2021 - Size: 70.7 MiB - WAL Size: 0 B
database-1 20210209T114450 - Tue Feb 9 11:44:53 2021 - Size: 70.7 MiB - WAL Size: 32.3 KiB
database-1 20210209T114054 - Tue Feb 9 11:40:58 2021 - Size: 70.7 MiB - WAL Size: 32.2 KiB- Более подробная информация из конкретной резервной копии получается с помощью:
barman show-backup server-a 20210209T115342. - Планируем резервное копирование с помощью cron:
barman cronвыполняется каждую минуту (операции архивирования WAL-журнала проходят параллельно на серверной основе, при этом обеспечивается соблюдение политик хранения на этих серверах).- Выполняем резервное копирование базы данных каждый день в полночь.
* * * * * barman /usr/bin/barman cron
0 0 * * * barman /usr/bin/barman backup database-1- Удаляем
/etc/cron.dвbackup.
Полезные команды barman
barman check database-1 — проверка конфигурации barman для конкретного сервера.barman status database-1 — показ состояния конкретного сервера.barman backup database-1 — создание резервной копии для конкретного сервера.barman backup --reuse=link main — принудительное добавочное резервное копирование.barman list-backup database-1 — вывод списка всех доступных резервных копий на конкретном сервере.barman show-backup database-1 <timestamp>п — показ содержимого резервной копии.barman show-backup database-1 latest — показ последней доступной резервной копии.
Восстановление резервной копии после аварийного завершения
- Подключаемся к схеме баз данных
database-1и удаляем часть данных, некоторые таблицы или базы данных, имитируя аварийную ситуацию. - Выключаем целевой сервер postgres на
database-1:systemctl stop postgresql.service. - В
backupот имени пользователяbarmanпросматриваем последнюю резервную копию barmanbarman show-backup database-1 latest:
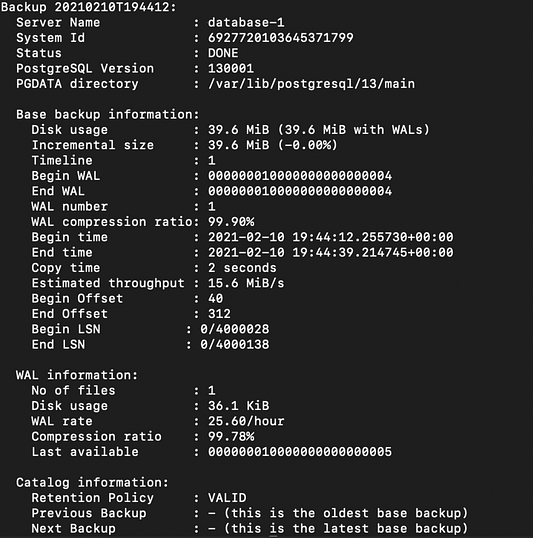
- Обращаем внимание на идентификатор резервной копии и время окончания резервного копирования.
- Здесь же в
backupот имени пользователяpostgresвыполняем следующую команду для восстановления этой резервной копии:
barman recover \\
--target-time "2021-02-10 19:44:39.214745+00:00" \\
--remote-ssh-command "ssh postgres@database-1" \\
database-1 20210210T194412 /var/lib/postgresql/12/main- Ждем завершения резервного копирования с сообщением:
Your PostgreSQL server has been successfully prepared for recovery!(«Ваш сервер PostgreSQL готов к восстановлению!»). - От имени пользователя
postgresвdatabase-1запускаем postgres в режиме восстановления:
# запускаем postgresql вручную, чтобы начать восстановление
/usr/lib/postgresql/12/bin/pg_ctl -D /var/lib/postgresql/12/main start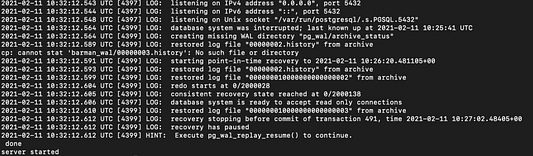
- Перезагружаем блок со 2-й базой данных
database-2. - Теперь сервер баз данных восстановлен из резервной копии.
Жесткая перезагрузка кластера Postgres
В случае если резервная копия базы данных не подлежит восстановлению и повреждена, практически ничего другого не остается, кроме как прибегнуть к жесткой перезагрузке кластера pg без переустановки контейнера базы данных. Для этого используют следующую процедуру. ВНИМАНИЕ!!! Это приведет к удалению всех данных.
# выводим список всех имеющихся в системе кластеров pg
pg_lsclusters
# удаляем кластер (на основе версии и идентификатора кластера)
pg_dropcluster 12 main
# создаем новый кластер
pg_createcluster 12 main- А теперь выполните описанную выше процедуру настройки кластера PostgreSQL в
/etc/postgres/..., ведь вся последняя конфигурация была удалена. - Если сервер Postgres не появляется после восстановления, посмотрите подробные логи запуска с помощью следующей команды:
/usr/lib/postgresql/12/bin/postgres -d 3 -D /var/lib/postgresql/12/main/ -c config_file=/etc/postgresql/13/main/postgresql.conf
Установка и настройка repmgr
Для настройки репликации между узлами postgres database-1 и database-2 будем использовать repmgr:
- В обоих блоках баз данных устанавливаем repmgr
apt-get install postgresql-12-repmgr. - В
database-1(основной узел) создаем пользователя repmgr и базу данных и выполняем от имени пользователяpostgresследующее:createuser --superuser repmgrcreatedb --owner=repmgr repmgr. - Меняем путь поиска пользователя repmgr по умолчанию:
psql -c "ALTER USER repmgr SET search_path TO repmgr, public;". - Редактируем
/etc/postgresql/12/main/postgresql.confи добавляем следующую строкуshared_preload_libraries = 'repmgr'. При запуске PostgreSQL будет загружено расширение repmgr. - В
database-1создаем стандартный конфигурационный файл repmgrtouch /etc/repmgr.confи добавляем следующее:
node_id=1
node_name=database-1
conninfo='host=database-1 user=repmgr dbname=repmgr port=5432'
data_directory='/var/lib/postgresql/12/main'
barman_host=backup
barman_server=database-1
restore_command='/usr/bin/barman-wal-restore -U barman backup database-1 %f %p'
pg_bindir='/usr/lib/postgresql/12/bin'
log_file='/backup/barman/repmgr.log'- В
database-1редактируем/etc/default/repmgrdи применяем следующее содержимое:
# отключение repmgrd по умолчанию, чтобы не запускался после установки
# допустимые значения: да/нет
REPMGRD_ENABLED=yes
# конфигурационный файл (обязательно)
REPMGRD_CONF=/etc/repmgr.conf
# дополнительные параметры
#REPMGRD_OPTS=""
# запуск repmgrd от имени пользователя
#REPMGRD_USER=postgres
# двоичный repmgrd
#REPMGRD_BIN=/usr/bin/repmgrd
# pid-файл
#REPMGRD_PIDFILE=/var/run/repmgrd.pid- В
database-2создаем стандартный конфигурационный файл repmgrtouch /etc/repmgr.confи добавляем следующее:
node_id=2
node_name=database-2
conninfo='host=database-2 user=repmgr dbname=repmgr port=5432 connect_timeout=2'
data_directory='/var/lib/postgresql/12/main'
log_file='/backup/barman/repmgr.log'- В
database-2редактируем/etc/default/repmgrdи применяем следующее содержимое:
# отключение repmgrd по умолчанию, чтобы не запускался после установки
# допустимые значения: да/нет
REPMGRD_ENABLED=yes
# конфигурационный файл (обязательно)
REPMGRD_CONF="/etc/repmgr.conf"
# дополнительные параметры
#REPMGRD_OPTS=""
# запуск repmgrd от имени пользователя
#REPMGRD_USER=postgres
# двоичный repmgrd
#REPMGRD_BIN=/usr/bin/repmgrd
# pid-файл
#REPMGRD_PIDFILE=/var/run/repmgrd.pid- Чтобы репликация работала,
database-1должна принять подключение репликации отdatabase-2. Реплика запрашивает информацию о репликации, а не наоборот. Вdatabase-1удостоверяемся в наличии следующей конфигурации в/etc/postgresql/12/main/pg_hba.conf(она у вас уже должна быть):
host all all <your-c-net> trust
host repmgr repmgr <your-c-net>trust
host replication repmgr <your-c-net> trust- От имени пользователя
postgresрегистрируем вdatabase-1основной узелdatabase-1с repmgr/usr/bin/repmgr -f /etc/repmgr.conf primary register:
INFO: connecting to primary database...
NOTICE: attempting to install extension "repmgr"
NOTICE: "repmgr" extension successfully installed
NOTICE: primary node record (ID: 1) registered- Проверяем состояние кластера
/usr/bin/repmgr -f /etc/repmgr.conf cluster show:

- Запускаем с правами администратора
rootrepmgrd вdatabase-1:/etc/init.d/repmgrd start. - Настраиваем 2-й узел, переключаемся на
database-2и останавливаем postgresql/etc/init.d/postgresql stop. - Выполняем от имени пользователя
postgres:/usr/bin/repmgr -h database-1 -U repmgr -d repmgr -p 5432 -F -f /etc/repmgr.conf standby clone --dry-run.
ИНФОРМАЦИЯ: все необходимые условия для standby clone («резервного клона») соблюдены
- По завершении выполняем операцию клонирования
/usr/bin/repmgr -h database-1 -U repmgr -d repmgr -p 5432 -F -f /etc/repmgr.conf standby clone:
NOTICE: standby clone (using pg_basebackup) complete
NOTICE: you can now start your PostgreSQL server
HINT: for example: pg_ctl -D /var/lib/postgresql/12/main start
HINT: after starting the server, you need to register this standby with "repmgr standby register"- На этом этапе PostgreSQL не работает в резервных узлах. Хотя у резервного узла есть скопированный из основного узла каталог данных Postgres, в том числе любые имеющиеся там конфигурационные файлы PostgreSQL.
- Теперь запускаем службу postgresql на вторичном узле
/etc/init.d/postgresql start. - Регистрируем от имени пользователя
postgresвторичный узел с repmgr/usr/bin/repmgr -f /etc/repmgr.conf standby register:
INFO: connecting to local node "database-2" (ID: 2)
INFO: connecting to primary database
WARNING: --upstream-node-id not supplied, assuming upstream node is primary (node ID 1)
INFO: standby registration complete
NOTICE: standby node "database-2" (ID: 2) successfully registered- Теперь проверим настройку кластера repmgr:
/usr/bin/repmgr -f /etc/repmgr.conf cluster show --compact

- Самое время протестировать репликацию: на основном сервере
database-1создаем базы данных, таблицы, записи и видим мгновенные изменения наdatabase-2→ поддерживает идеальную синхронизацию со вспомогательным сервером. Отличная работа!
Настройка переключения вручную
- Наша цель — с помощью repmgr переключиться с первичного узла/сервера на вторичный и обратно.
- Перед переключением обратимся к настройке кластера
sudo -u postgres /usr/bin/repmgr -f /etc/repmgr.conf cluster show --compact:

- Выполняем переключение в
database-2:
/usr/bin/repmgr standby switchover -f /etc/repmgr.conf:
NOTICE: executing switchover on node "database-2" (ID: 2)
NOTICE: local node "database-2" (ID: 2) will be promoted to primary; current primary "database-1" (ID: 1) will be demoted to standby
NOTICE: stopping current primary node "database-1" (ID: 1)
NOTICE: issuing CHECKPOINT
DETAIL: executing server command "/usr/lib/postgresql/12/bin/pg_ctl -D '/var/lib/postgresql/12/main' -W -m fast stop"
INFO: checking for primary shutdown; 1 of 60 attempts ("shutdown_check_timeout")
INFO: checking for primary shutdown; 2 of 60 attempts ("shutdown_check_timeout")
NOTICE: current primary has been cleanly shut down at location 0/25000028
NOTICE: promoting standby to primary
DETAIL: promoting server "database-2" (ID: 2) using pg_promote()
NOTICE: waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete
NOTICE: STANDBY PROMOTE successful
DETAIL: server "database-2" (ID: 2) was successfully promoted to primary
INFO: local node 1 can attach to rejoin target node 2
DETAIL: local node's recovery point: 0/25000028; rejoin target node's fork point: 0/250000A0
NOTICE: setting node 1's upstream to node 2
WARNING: unable to ping "host=database-1 user=repmgr dbname=repmgr port=5432"
DETAIL: PQping() returned "PQPING_NO_RESPONSE"
NOTICE: starting server using "/usr/lib/postgresql/12/bin/pg_ctl -w -D '/var/lib/postgresql/12/main' start"
WARNING: unable to ping "host=database-1 user=repmgr dbname=repmgr port=5432"
DETAIL: PQping() returned "PQPING_NO_RESPONSE"
WARNING: unable to ping "host=database-1 user=repmgr dbname=repmgr port=5432"
DETAIL: PQping() returned "PQPING_NO_RESPONSE"- На ubuntu с командой
/usr/lib/postgresql/12/bin/pg_ctl -w -D '/var/lib/postgresql/12/main' start, скорее всего, возникнут проблемы:PQping() returned "PQPING_NO_RESPONSE"будет появляться несколько раз, пока не истечет время ожидания. В этом случае запустите postgres вручную наdatabase-1в то время, когда будут повторные попытки подключиться к/etc/init.d/postgresql start. - А теперь проверим настройку кластера repmgr:
sudo -u postgres /usr/bin/repmgr -f /etc/repmgr.conf cluster show --compact:

- Сейчас кластер repmgr работает с
database-2в качестве основного узла. - Выполняем обратное переключение в
database-1от имени пользователяpostgres:/usr/bin/repmgr standby switchover -f /etc/repmgr.conf. - Опять же, в этом сценарии на ubuntu у postgres возможны проблемы с правильным возвращением на
database-2. Здесь тоже запускаем postgres с правами администратораrootс помощью/etc/init.d/postgres start. - Проверим настройку кластера repmgr:
sudo -u postgres /usr/bin/repmgr -f /etc/repmgr.conf cluster show --compact:
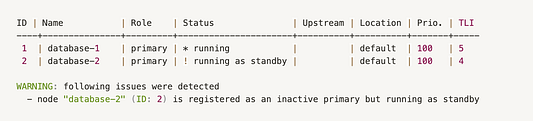
- Предупреждающее сообщение подсказывает, что нужно выбрать вновь ставший основным сервер: в
database-2от имени пользователяpostgresвыполняемrepmgr standby follow. - Вот мы и переключились в кластере с первичного узла repmgr на вторичный и обратно.
Очищаем конфигурацию repmgr и начинаем сначала
- Возможны ситуации, когда проще удалить текущую и, быть может, поломанную конфигурацию repmgr и начать все сначала. В этом случае в основном узле от имени пользователя
postgresвыполняем:
psql -c "delete from repmgr.events;" repmgr
psql -c "delete from repmgr.monitoring_history;" repmgr
psql -c "delete from repmgr.nodes;" repmgr
psql -c "delete from repmgr.voting_term;" repmgrЗаключение
Поздравляю, мы настроили PostgreSQL с резервным копированием, полной репликацией и научились переключаться с основного узла базы данных на вторичный и обратно без риска для данных.
В добавок ко всему этому неплохо было бы выполнять полное текстовое резервное копирование с применением статической диспетчеризации (например, каждое воскресенье) с помощью pg_dumpall | gzip > backup.gz. Ведь когда-нибудь может понадобиться полный дамп всего содержимого кластера баз данных в текстовом формате для использования на разных ОС, версиях PostgreSQL или даже в разных системах управления базами данных.
А кроме того, мы еще не рассматривали то, как с переключением справляется прикладной уровень. Здесь возможны варианты: использовать средство балансировки нагрузки для принятия фактического решения о том, к какому серверу базы данных подключиться клиенту, или создать и настроить эту возможность на прикладном уровне.
Читайте также:
- SQLite: как организовывать таблицы
- Суперсила индексов для оптимизации SQL-запросов
- Основы SQLite на примере практической задачи
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Thomas Reinecke: Database operational excellence with PostgreSQL 12





