
Pandas — одна из самых популярных библиотек Python. Ее DataFrame интуитивно понятен и оснащен продвинутыми API для выполнения задач по работе с данными. Многие библиотеки Python были интегрированы с Pandas DataFrame, чтобы повысить скорость их принятия.
Однако библиотека Pandas не является эталоном в области обработки больших наборов данных. Она преимущественно используется для анализа данных на одной машине, а не на кластере машин. В этой статье будут представлены результаты оценки производительности более быстрых альтернатив: Polars, DuckDB, Vaex и Modin.
Почему Pandas работает медленно на больших наборах данных?
Основная причина заключается в том, что библиотека не была создана для работы на нескольких ядрах. Pandas использует только одно ядро процессора за раз для выполнения задач по манипулированию данными, поэтому не имеет никаких преимуществ на современных ПК, оснащенных несколькими ядрами для параллелизма.
Как решить проблему, когда объем данных велик (хотя может поместиться на одной машине) и потребуется много времени для работы с Pandas? Одно из решений — использовать такой фреймворк, как Apache Spark, предназначенный для выполнения задач манипулирования данными с применением кластеров. В некоторых случаях более эффективным может оказаться анализ данных посредством выборки и анализа на одной машине.
Работать на одной машине также можно, используя такие альтернативы Pandas, как Polars, DuckDB, Vaex и Modin. Чтобы понять, сколько времени понадобится для обработки большого количества данных, воспользуйтесь представленным здесь бенчмарком производительности на одной машине.
Подготовка к оценке производительности
Технические характеристики тестируемой машины
- MacBook Pro (13-дюймовый, 2020 год, четыре порта Thunderbolt 3).
- Процессор: 2 ГГц, четырехъядерный Intel Core i5 (4 ядра).
- Память: 16 ГБ, 3733 МГц LPDDR4X.
- ОС: MacOS Monterey 12.2.
Тестовый набор данных
Для демонстрации различий будет достаточно среднего по объему набора данных. Талоны на парковку в Нью-Йорке — подходящий набор данных для бенчмарка. Он содержит 42,3 млн строк и 51 столбец данных, собранных с августа 2013 года по июнь 2017 года, а также содержит такую полезную информацию, как страна регистрации, марка автомобиля и цвет автомобиля. Для данного теста был использован набор данных за 2017 финансовый год с 10,8 млн строк. Объем файла составляет около 2,09 Гб.
Процесс оценки
- Поскольку общее время работы включает в себя отображение данных в память, рассмотрим загрузку данных отдельно.
- Обработаем один и тот же вызов 5 раз, чтобы избежать граничных случаев, и используем для отчета медианное значение в качестве окончательного результата производительности.
Вспомогательная функция для повторения и вычисления медианы
from itertools import repeat
from statistics import median
import functools
import time
durations = []
## повторить заданную функцию несколько раз, добавить продолжительность выполнения в список
def record_timer(func, times = 5):
for _ in repeat(None, times):
start_time = time.perf_counter()
value = func()
end_time = time.perf_counter()
run_time = end_time - start_time
print(f"Finished {func.__name__!r} in {run_time:.10f} secs")
durations.append(run_time)
return value
## Декоратор и вычисление функции медианы
def repeat_executor(times=5):
def timer(func):
"""Print the runtime of the decorated function"""
@functools.wraps(func)
def wrapper_timer(*args, **kwargs):
value = record_timer(func, times=times)
print(f'{median(list(durations))}')
return value
return wrapper_timer
return timer
Предупреждение: чтобы вы лучше поняли процесс, весь код приведен здесь (чтобы не отсылать вас на GitHub). Если вас не интересует процесс, пропустите эту часть и перейдите сразу к окончательному результату.
Pandas: базовый уровень
Чтобы установить базовые параметры для сравнения, рассмотрим известные случаи использования в ежедневной аналитической работе.
- Фильтрация: поиск марки автомобиля (Vehicle Make) BMW.
- Агрегирование: группировка по марке автомобиля и выполнение подсчета.
- Соединение: SELF JOIN количества талонов на парковку (Summons Number).
- Оконная функция: ранжирование марки автомобиля на основе подсчетов.
Выберем только те поля, которые будут использованы в тестировании, а именно ‘Summons Number’, ‘Vehicle Make’ и ‘Issue Date’. Обратите внимание: если выбрать все поля, последние два запроса будут выполняться значительно медленнее.
import pandas as pd
from repeat_helper import repeat_executor
df = pd.read_csv("./Parking_Violations_Issued_-_Fiscal_Year_2017.csv")
df = df[['Summons Number', 'Vehicle Make', 'Issue Date']]
# ## Фильтрация по марке автомобиля (для BMW)
@repeat_executor(times=5)
def test_filter():
return df[df['Vehicle Make'] == 'BMW']['Summons Number']
# # ## Группировка по марке автомобиля и подсчет
@repeat_executor(times=5)
def test_groupby():
return df.groupby("Vehicle Make").agg({"Summons Number":'count'})
# # ## SELF join
@repeat_executor(times=5)
def test_self_join():
return df.set_index("Summons Number").join(df.set_index("Summons Number"), how="inner", rsuffix='_other').reset_index()['Summons Number']
## оконная функция
@repeat_executor(times=5)
def test_window_function():
df['summon_rank'] = df.sort_values("Issue Date",ascending=False) \
.groupby("Vehicle Make") \
.cumcount() + 1
return df
test_filter()
# # Время медианы - 0.416 с
test_groupby()
# # Время медианы - 0.600 с
test_self_join()
# # Время медианы - 4.159 с
test_window_function()
# # Время медианы - 17.465 с
DuckDb: эффективная OLAP-база данных в процессе работы
DuckDB набирает популярность, поскольку столбцово-векторный механизм этой базы данных позволяет выполнять аналитические типы запросов. Это аналитическая или OLAP-версия SQLite, широко распространенной встроенной СУБД.
Хотя DuckDB — это СУБД, ее установка проще по сравнению с Microsoft SQL Server и Postgres. Кроме того, для выполнения запроса не требуется никаких внешних зависимостей. Выполнить SQL-запрос можно с помощью DuckDb CLI.
Если вы предпочитаете интерфейс SQL, DuckDb может стать для вас лучшей альтернативой анализу данных непосредственно в CSV или Parquet-файлах. Продолжим с примерами кода и одновременно покажем, насколько просто работать с SQL в DuckDb.
В DuckDb есть функция read_csv_auto для вывода CSV-файла и загрузки этих данных в память. Во время выполнения было обнаружено, что нужно изменить SAMPLE_SIZE=-1, чтобы пропустить выборку, так как некоторые поля в наборе данных не были выведены правильно, а выборка по умолчанию составляет 1000 строк.
import duckdb
from repeat_helper import repeat_executor
con = duckdb.connect(database=':memory:')
con.execute("""CREATE TABLE parking_violations AS SELECT "Summons Number", "Vehicle Make", "Issue Date" FROM read_csv_auto('/Users/chengzhizhao/projects/pandas_alternatives/Parking_Violations_Issued_-_Fiscal_Year_2017.csv', delim=',', SAMPLE_SIZE=-1);""")
con.execute("""SELECT COUNT(1) FROM parking_violations""")
print(con.fetchall())
# ## Фильтрация по марке автомобиля (для BMW)
@repeat_executor(times=5)
def test_filter():
con.execute("""
SELECT * FROM parking_violations WHERE "Vehicle Make" = 'BMW'
""")
return con.fetchall()
# # ## Группировка по марке автомобиля и подсчет
@repeat_executor(times=5)
def test_groupby():
con.execute("""
SELECT COUNT("Summons Number") FROM parking_violations GROUP BY "Vehicle Make"
""")
return con.fetchall()
# # # ## SELF join
@repeat_executor(times=5)
def test_self_join():
con.execute("""
SELECT a."Summons Number"
FROM parking_violations a
INNER JOIN parking_violations b on a."Summons Number" = b."Summons Number"
""")
return con.fetchall()
# ## оконная функция
@repeat_executor(times=5)
def test_window_function():
con.execute("""
SELECT *, ROW_NUMBER() OVER (PARTITION BY "Vehicle Make" ORDER BY "Issue Date")
FROM parking_violations
""")
return con.fetchall()
test_filter()
# Время медианы - 0.410 с
test_groupby()
# # Время медианы - 0.122 с
test_self_join()
# # Время медианы - 3.364 с
test_window_function()
# # Время медианы - 6.466 с
Тест фильтрации показал достижение паритета, а в остальных трех тестах производительность намного выше по сравнению с Pandas.
Чтобы не писать на Python, можно использовать DuckDb CLI с SQL-интерфейсом в командной строке или TAD.
Polars: быстрая сборка на Rust + Arrow
Ричи Винк, разработчик Polars, писал в своем блоге: “Я создал одну из самых быстрых DataFrame-библиотек”. И она была оценена по достоинству.
Вот основные причины, по которым Polars может заменить Pandas.
- Polars с самого начала приступает к распараллеливанию DataFrame. Эта библиотека не ограничивается одноядерными операциями.
- PyPolars основан на языке Rust с привязкой к Python. Он обладает выдающейся производительностью, сравнимой с C, а “Arrow Columnar Format” — отличный выбор для аналитических запросов типа OLAP.
- Ленивая оценка: планирование (невыполнение) запроса до тех пор, пока он не сработает. Это может быть использовано для оптимизации запросов, таких как дополнительный pushdown.
import polars as pl
from repeat_helper import repeat_executor
df = pl.read_csv("./Parking_Violations_Issued_-_Fiscal_Year_2017.csv")
df = df.select(['Summons Number', 'Vehicle Make', 'Issue Date'])
# ## Фильтрация по марке автомобиля (для BMW)
@repeat_executor(times=5)
def test_filter():
return df.filter(pl.col('Vehicle Make') == 'BMW').select('Summons Number')
# # ## Группировка по марке автомобиля и подсчет
@repeat_executor(times=5)
def test_groupby():
return df.groupby("Vehicle Make").agg(pl.col("Summons Number").count())
# # # ## SELF join
@repeat_executor(times=5)
def test_self_join():
return df.join(df, on="Summons Number", how="inner").select('Summons Number')
# ## оконная функция
@repeat_executor(times=5)
def test_window_function():
return df.select(
[
'Summons Number',
'Vehicle Make',
'Issue Date',
pl.col(['Issue Date']).sort(reverse=True).cumcount().over("Vehicle Make").alias("summon_rank")
]
)
test_filter()
# # Время медианы - 0.0523 с
test_groupby()
# # # Время медианы - 0.0808 с
test_self_join()
# # # Время медианы - 1.343 с
test_window_function()
# # Время медианы - 2.705 с
Написание кода в Polars создает ощущение микса pySpark и Pandas, но интерфейс настолько знаком, что потребуется менее 15 минут, чтобы написать вышеуказанный запрос, не имея опыта работы с API Polars. Быстро освоить библиотеку поможет документация на Python.
Vaex: датафреймы, использующие внешнюю память
Vaex — еще одна альтернатива Pandas, которая выполняет ленивую оценку, избегая дополнительной траты памяти в ущерб производительности. Он использует распределенную память и будет выполняться только при явном запросе. Vaex имеет набор удобных визуализаций данных, облегчающих изучение датасета.
В Vaex реализованы распараллеленное группирование и эффективное соединение.
import vaex
from repeat_helper import repeat_executor
vaex.settings.main.thread_count = 4 # столько ядер подходит макбука
df = vaex.open('./Parking_Violations_Issued_-_Fiscal_Year_2017.csv')
df = df[['Summons Number', 'Vehicle Make', 'Issue Date']]
# ## Фильтрация по марке автомобиля (для BMW)
@repeat_executor(times=5)
def test_filter():
return df[df['Vehicle Make'] == 'BMW']['Summons Number']
# # ## Группировка по марке автомобиля и подсчет
@repeat_executor(times=5)
def test_groupby():
return df.groupby("Vehicle Make").agg({"Summons Number":'count'})
# # ## SELF join
@repeat_executor(times=5)
def test_self_join():
return df.join(df, how="inner", rsuffix='_other', left_on='Summons Number', right_on='Summons Number')['Summons Number']
test_filter()
# # Время медианы - 0.006 с
test_groupby()
# # Время медианы - 2.987 с
test_self_join()
# # Время медианы - 4.224 с
# ококнная функция https://github.com/vaexio/vaex/issues/804
Однако я обнаружил, что оконная функция не реализована, и открыл ветку обсуждения по этой проблеме. Мы можем выполнить итерацию по каждой группе и присвоить каждой строке значене, используя предложения, упомянутое в этой ветке обсуждения. Похоже, что оконная функция не реализована для Vaex “из коробки”.
vf['rownr`] = vaex.vrange(0, len(vf))
Modin: масштабирование Pandas путем изменения одной строки кода
Как с помощью изменения одной строки кода Modin позволяет достичь более высокой производительности, чем Pandas? В Modin нужно сделать следующее изменение, заменив библиотеку Pandas на Modin.
## импорт pandas как pd
import modin.pandas as pd
Однако есть еще целый список реализаций, которые необходимо выполнить в Modin. Помимо изменения кода, также потребуется настроить его бэкенд для планирования. В этом примере я попытался использовать Ray.
import os
os.environ["MODIN_ENGINE"] = "ray" # Modin will use Ray
#########################
####### То же, что в Pandas #######
#########################
test_filter()
# # Время медианы - 0.828 с
test_groupby()
# # Время медианы - 1.211 с
test_self_join()
# # Время медианы - 1.389 с
test_window_function()
# # Время медианы - 15.635 с,
# `DataFrame.groupby_on_multiple_columns` в настоящее время не поддерживается PandasOnRay, по умолчанию используется реализация pandas.
Оконная функция в Modin не поддерживается в Ray, поэтому здесь по-прежнему используется реализация Pandas. По затраченному времени оконная функция ближе к Pandas.
(py)datatable
Если вы являетесь членом сообщества R, то должны быть знакомы с пакетом data.table. По мере того, как любой пакет становится популярным, его основная идея привносится в другие языки. (py)datatable — одна из попыток имитировать основные алгоритмы и API data.table языка R.
Хотя во время тестирования оказалось, что он не работает быстрее, чем pandas, учитывая, что синтаксис похож на data.table из R, думаю, что его стоит упомянуть здесь как альтернативу Pandas.
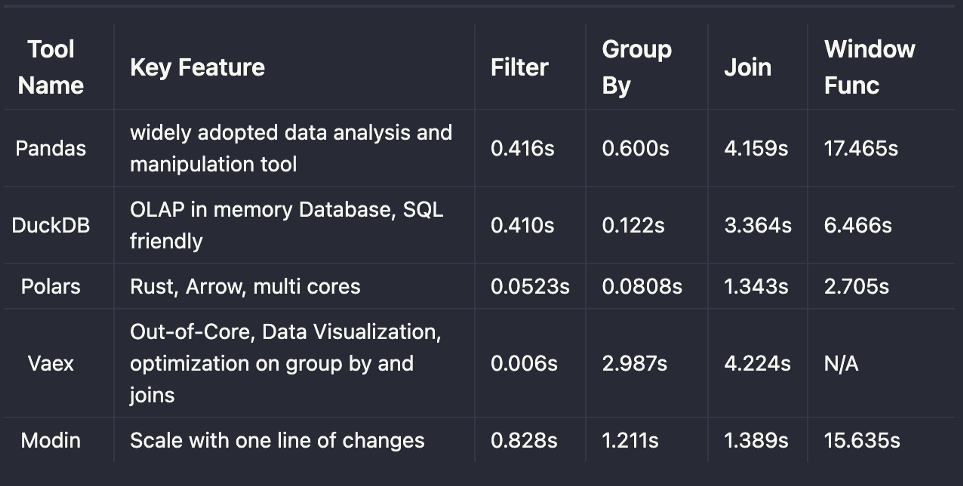
Результаты
Заключение
Эти 4 альтернативных инструмента Pandas обеспечивают пользователям более высокую производительность в протестированных случаях. В то же время изменение API не является значительным для Pandas. Переход на любую из этих библиотек должен быть плавным. С другой стороны, Pandas по-прежнему обладает максимальным охватом функциональности в отношении API. Альтернативные решения могут не предоставить расширенную поддержку API, например оконные функции.
Запуск Pandas на одной машине по-прежнему является лучшим вариантом для анализа данных и запросов ad-hoc. Альтернативные библиотеки могут повысить производительность в некоторых случаях, но только на одной машине.
Читайте также:
- Откажитесь от SQLite в пользу DuckDB
- Bamboolib — изучайте и используйте Pandas без написания кода
- Внимание: работает пакет Python Tweepy!
Читайте нас в Telegram, VK и Дзен
Перевод статьи Chengzhi Zhao: 4 Faster Pandas Alternatives for Data Analysis





