
Twitter — это превосходная среда для изучения разных типов пользователей, взаимоотношений и информации. Данный сервис в изобилии предоставляет материал для многочисленных исследований.
Кто-то может поинтересоваться: “А зачем извлекать информацию из потока данных в Twitter, если можно воспользоваться уже имеющимися датасетами от ранее проведенных исследований?” Дело в том, что ситуации бывают разными и существующие наборы данных могут не соответствовать целям и масштабам исследования.
В данной статье мы научимся создавать датасет, у которого будет как минимум в два раза больше функциональностей по сравнению с известными мне датасетами и руководствами. Вы в праве использовать их как угодно. Моя задача — показать все возможности. Настоятельно рекомендую заранее извлекать все имеющиеся данные для исследования, поскольку в дальнейшем они могут стать недоступны по причине удаления твитов.
В конце статьи прилагается полный вариант рассмотренного кода. Весь рабочий материал и ссылка на видео размещены в данном репозитории GitHub.
1. С чего начать?
Первый этап — создание аккаунта в Twitter.
Для подключения к API Twitter потребуется аккаунт разработчика и учетные данные. Доступ к ключам и токенам предоставляется через Apps и App Details, где вы также при необходимости сможете их восстановить. В процессе работы на экране появятся следующие сообщения:
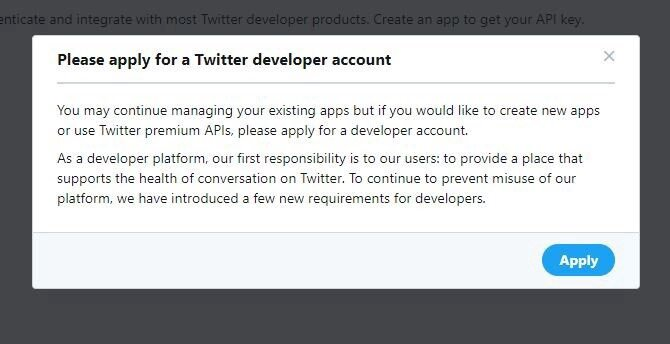
Подать заявку на получение аккаунта разработчика. Помимо работы с уже имеющимися приложениями вам предоставляется возможность создавать новые или воспользоваться Premium API Twitter. Для этого необходимо подать заявку на получение аккаунта разработчика. Наша платформа разработчиков несет перед пользователями ответственность за предоставление пространства, которое поддерживает безопасное общение в Twitter. Во избежание злонамеренного использования платформы были введены новые требования для разработчиков.
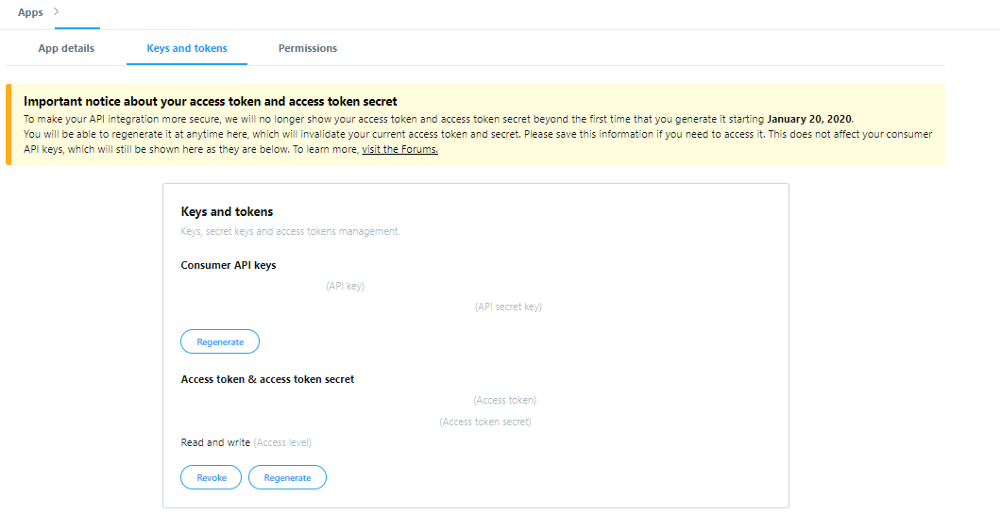
Потребуется сохранить учетные данные для последующего их размещения в соответствующем месте кода, как показано на скриншоте:
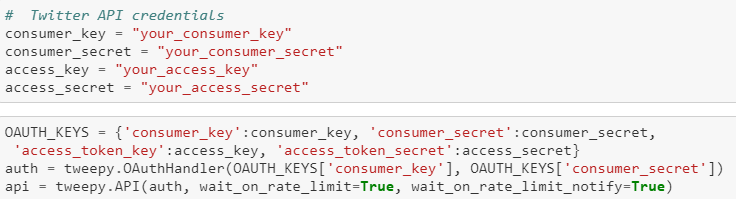
Обеспечьте сохранность учетных данных! Не делитесь ими! Это доступ к потоку данных Twitter через ваш аккаунт. Пусть мы всего лишь извлекаем твиты для изучения и анализа. Но если ваши ключи и учетные данные попадут к злоумышленникам, их могут использовать в противоправных действиях.
2. Установка и импорт
Второй этап — установка и импорт пакетов.
Один из важнейших — пакет Python Tweepy для подключения к потоку данных Twitter посредством учетных данных через API Twitter. Импорт JSON также представляется не менее важным, так как структура твита является объектом JSON. Pandas помогает парсить строку JSON в более удобный табличный датасет. Поскольку API Twitter ограничен по времени, потребуется пакет Python Time для вставки 15-минутного перерыва между партиями извлекаемых твитов.
3. Знакомство с API поиском
Рассмотрим синтаксис для применения tweepy.Cursor с целью подключения к API Twitter:
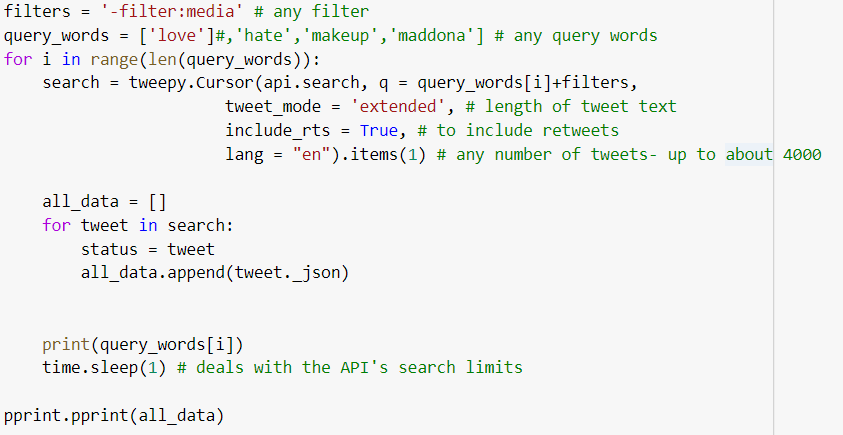
Tweepy получает несколько аргументов в каждом поиске:
Queries(запросы) — слова для поиска;Filters(фильтры) — термины, исключенные из поиска;Tweet_mode— длина текста твита в 140 или 280 символов;Include_rts— включение ретвитов;lang Items— язык для поиска.
Кроме того, имеются ограничения по времени: примерно 4000 твитов за 15 минут. Это значит, что следует учитывать 15-минутный перерыв в функции, извлекающей твиты с помощью time.sleep(900).
4. Данные твита
Расширенный твит:
“text”: “Не можете уместить твит в 140 символов? \n\nМы апробируем новое решение совместно с небольшой группой и увеличиваем симв… https://t.co/y1rJlHsVB5″,
“text”: “Can’t fit your Tweet into 140 characters? 🤔\n\nWe’re trying something new with a small group, and increasing the char… https://t.co/y1rJlHsVB5″,
“extended_tweet”: {
“full_text”: “Не можете уместить твит в 140 символов? \n\nМы апробируем новое решение совместно с небольшой группой и увеличиваем лимит символов до 280! Если вы в восторге от возможностей, то узнавайте в нашем блоге все необходимые подробности. 👇\nhttps://t.co/C6hjsB9nbL»,
“full_text”: “Can’t fit your Tweet into 140 characters? 🤔\n\nWe’re trying something new with a small group, and increasing the character limit to 280! Excited about the possibilities? Read our blog to find out how it all adds up. 👇\nhttps://t.co/C6hjsB9nbL»,
Пример твита из моей ветки:
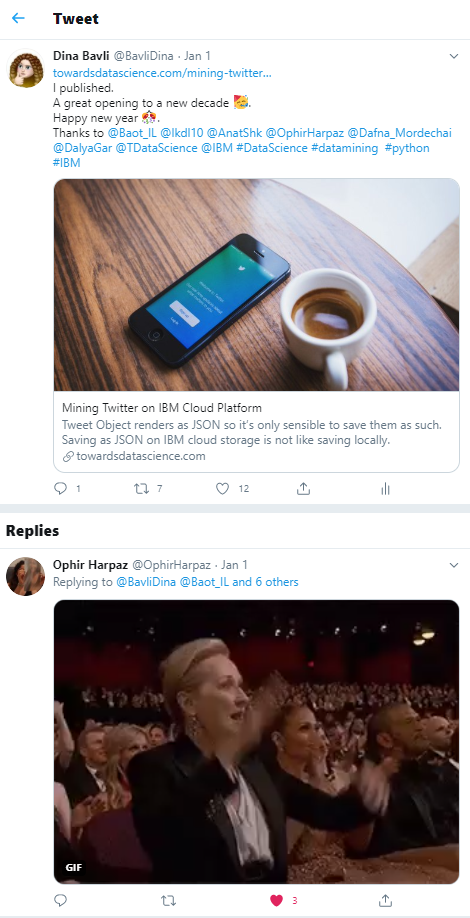
Из данной ветки твитов можно извлечь:
- текст;
- эмодзи;
- даты;
- ретвиты;
- упоминания;
- пользователей;
- хэштеги;
- ответные сообщения;
- лайки;
- URL;
- изображения.
5. Пользовательские данные
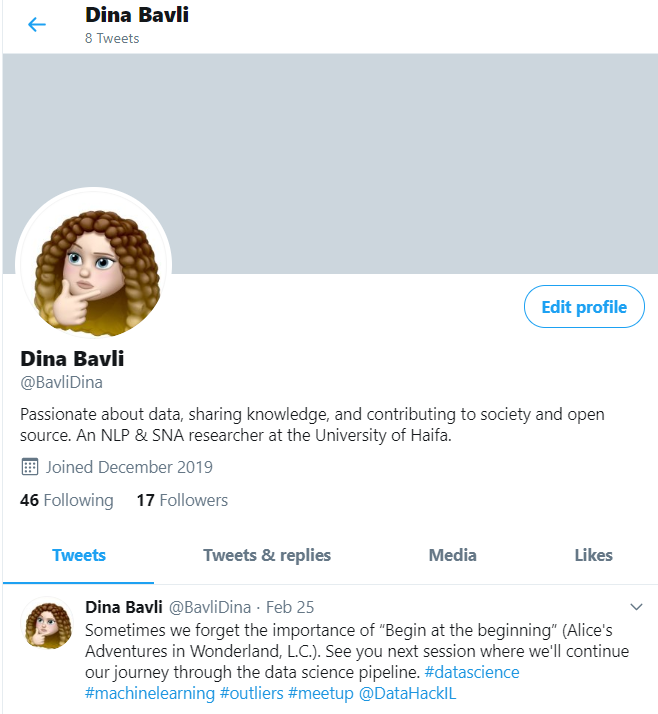
Из данного профиля можно извлечь следующие поля:
- имя;
- имя пользователя;
- подписчики;
- подписки;
- дата регистрации;
- лайки;
- твиты.
Ниже представлен список полей из объекта tweet, который создает требуемый датафрейм (полный код в конце статьи):
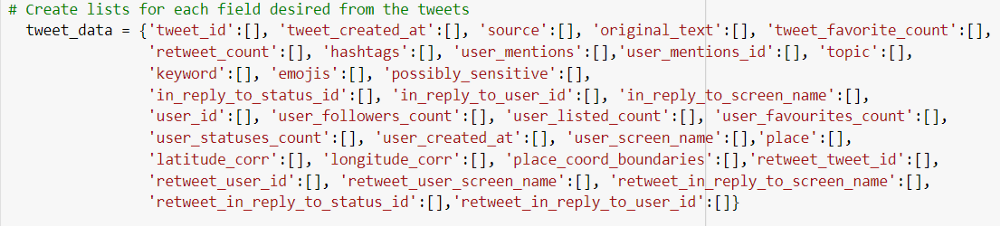
6. Подробно о твитах

Перед вами скриншот полученных метаданных твита. И выглядит он жутковато. Несмотря на небольшой размер, тут и там заметны маленькие эмодзи. Это значит, что полный текст твита может появляться в разных местах строки JSON. Кроме того, это говорит о том, что мы не можем обойтись только применением tweet_mode=’extended’, text.append(tweet.full_text) или text в качестве запасного варианта. Рассмотрим решение этой проблемы:
{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "tweet_text.ipynb",
"provenance": [],
"authorship_tag": "ABX9TyPc++N10Hea3dEDNTxQql/Y",
"include_colab_link": true
},
"kernelspec": {
"name": "python3",
"display_name": "Python 3"
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "view-in-github",
"colab_type": "text"
},
"source": [
"<a href=\"https://colab.research.google.com/gist/dinbav/08715a19459b6e35eb4133784d36621e/tweet_text.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
]
},
{
"cell_type": "code",
"metadata": {
"id": "xYJuypfsVZXP",
"colab_type": "code",
"colab": {}
},
"source": [
" for tweet in search:\n",
" status = tweet\n",
" if 'extended_tweet' in status._json: status_json = status._json['extended_tweet']['full_text']\n",
" elif 'retweeted_status' in status._json and 'extended_tweet' in status._json['retweeted_status']: status_json = status._json['retweeted_status']['extended_tweet']['full_text'] \n",
" elif 'retweeted_status' in status._json: status_json = status._json['retweeted_status']['full_text']\n",
" else: status_json = status._json['full_text']\n",
" status = status._json\n",
" tweet_data['original_text'].append(status_json) "
],
"execution_count": null,
"outputs": []
}
]
}С полным текстом проводятся разные виды анализа с применением методологий НЛП, например анализ тональности текста или линейный дискриминантный анализ ЛДА (тематический анализ). Вы можете разбить его на части в зависимости от пользователей, обсуждающих тему.
Извлечем информацию о самом твите следующим образом:
{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "tweet_status.ipynb",
"provenance": [],
"authorship_tag": "ABX9TyOrjTdgUIc5+0ylM8xi3bGR",
"include_colab_link": true
},
"kernelspec": {
"name": "python3",
"display_name": "Python 3"
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "view-in-github",
"colab_type": "text"
},
"source": [
"<a href=\"https://colab.research.google.com/gist/dinbav/1f77f75b65296b8d912c4fcbd21438d1/tweet_status.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
]
},
{
"cell_type": "code",
"metadata": {
"id": "hx2r41HO7v0e",
"colab_type": "code",
"colab": {}
},
"source": [
" tweet_data['tweet_id'].append(status['id'])\n",
" tweet_data['tweet_created_at'].append(status['created_at'])\n",
" tweet_data['source'].append(status['source'])\n",
" tweet_data['tweet_favorite_count'].append(status['favorite_count'])\n",
" tweet_data['retweet_count'].append(status['retweet_count'])"
],
"execution_count": null,
"outputs": []
}
]
}Теперь получим информацию о пользователе:
{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "user_data.ipynb",
"provenance": [],
"authorship_tag": "ABX9TyMGD+sc8cqrOSS9aZ8js7cH",
"include_colab_link": true
},
"kernelspec": {
"name": "python3",
"display_name": "Python 3"
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "view-in-github",
"colab_type": "text"
},
"source": [
"<a href=\"https://colab.research.google.com/gist/dinbav/de6806510dbba7bafe45ebda2a452ce6/user_data.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
]
},
{
"cell_type": "code",
"metadata": {
"id": "UHkWiu-C4-Iy",
"colab_type": "code",
"colab": {}
},
"source": [
"\n",
" tweet_data['user_screen_name'].append(status['user']['screen_name'])#\n",
" tweet_data['user_id'].append(status['user']['id'])\n",
" tweet_data['user_followers_count'].append(status['user']['followers_count'])\n",
" tweet_data['user_listed_count'].append(status['user']['listed_count'])\n",
" tweet_data['user_favourites_count'].append(status['user']['favourites_count'])\n",
" tweet_data['user_statuses_count'].append(status['user']['statuses_count'])\n",
" tweet_data['user_created_at'].append(status['user']['created_at'])\n"
],
"execution_count": null,
"outputs": []
}
]
}И теперь очередь упоминаний и хэштегов:
{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "tweet_entities.ipynb",
"provenance": [],
"authorship_tag": "ABX9TyOx026g/t+/ZkP9aoTWo7xE",
"include_colab_link": true
},
"kernelspec": {
"name": "python3",
"display_name": "Python 3"
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "view-in-github",
"colab_type": "text"
},
"source": [
"<a href=\"https://colab.research.google.com/gist/dinbav/50d3fe5af4943323e199c944e1c9bbfa/tweet_entities.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
]
},
{
"cell_type": "code",
"metadata": {
"id": "20m7AZdg8qkA",
"colab_type": "code",
"colab": {}
},
"source": [
""
],
"execution_count": null,
"outputs": []
},
{
"cell_type": "code",
"metadata": {
"id": "GxrzMmG18fHS",
"colab_type": "code",
"colab": {}
},
"source": [
" mentions = status[\"entities\"][\"user_mentions\"]\n",
" mentioned_users = \", \".join([mention['screen_name'] for mention in mentions])\n",
" tweet_data['user_mentions'].append(mentioned_users ) \n",
" mentions_id =[mention['id'] for mention in mentions]\n",
" tweet_data['user_mentions_id'].append(mentions_id)\n",
" \n",
" hashtags = \", \".join([hashtag_item['text'] for hashtag_item in status['entities']['hashtags']])\n",
" tweet_data['hashtags'].append(hashtags)\n",
" \n",
"\n",
" \n"
],
"execution_count": null,
"outputs": []
}
]
}Ответные сообщения:
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "tweet_in_reply_to.ipynb",
"provenance": [],
"authorship_tag": "ABX9TyMPuGZm5QyDZRxrial52a24",
"include_colab_link": true
},
"kernelspec": {
"name": "python3",
"display_name": "Python 3"
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "view-in-github",
"colab_type": "text"
},
"source": [
"<a href=\"https://colab.research.google.com/gist/dinbav/eb2e5922f36bee0632cf879cfd3bd370/tweet_in_reply_to.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
]
},
{
"cell_type": "code",
"metadata": {
"id": "20m7AZdg8qkA",
"colab_type": "code",
"colab": {}
},
"source": [
"\n",
"\n",
" tweet_data['in_reply_to_status_id'].append(tweet.in_reply_to_status_id)\n",
" tweet_data['in_reply_to_user_id'].append(tweet.in_reply_to_user_id)\n",
" tweet_data['in_reply_to_screen_name'].append(tweet.in_reply_to_screen_name)\n"
],
"execution_count": null,
"outputs": []
}
]
}Извлечение данных о сторонах общения позволяет задействовать в анализе данных методологии графов и SNA, использующих такие пакеты Python, как NetworkX.
Для географического анализа, например построения графика твитов на основе их местоположения, соответствующие данные извлекаются так:
{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "tweet_location.ipynb",
"provenance": [],
"authorship_tag": "ABX9TyN59F1394DgmJfm77gL83IV",
"include_colab_link": true
},
"kernelspec": {
"name": "python3",
"display_name": "Python 3"
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "view-in-github",
"colab_type": "text"
},
"source": [
"<a href=\"https://colab.research.google.com/gist/dinbav/d89bf1d62a04a63c9782e244790c8c9f/tweet_location.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
]
},
{
"cell_type": "code",
"metadata": {
"id": "-ityLiv62Oii",
"colab_type": "code",
"colab": {}
},
"source": [
"#get location of the tweet if possible\n",
" try:\n",
" location = status['user']['location']\n",
" user_loc=geolocator.geocode(location)\n",
"\n",
" if user_loc: \n",
" \n",
" lat=user_loc.latitude\n",
" lon=user_loc.longitude\n",
" else:\n",
" lat=''\n",
" lon='' \n",
"\n",
"\n",
" except TypeError:\n",
" location = ''\n",
" \n",
" tweet_data['latitude_corr'].append(lat)\n",
" tweet_data['longitude_corr'].append(lon)\n",
" tweet_data['place'].append(location)\n",
"\n",
" try:\n",
" coordinates = [coord for loc in status['place']['bounding_box']['coordinates'] for coord in loc]\n",
" except TypeError:\n",
" coordinates = None\n",
" tweet_data['place_coord_boundaries'].append(coordinates)"
],
"execution_count": null,
"outputs": []
}
]
}Некоторые твиты носят конфиденциальный характер. Twitter отмечает их тегами, особенно при наличии деликатного и неоднозначного контента. Рассмотрим способ извлечения “деликатных” тегов:
{
"nbformat": 4,
"nbformat_minor": 0,
"metadata": {
"colab": {
"name": "tweet_sensitive.ipynb",
"provenance": [],
"authorship_tag": "ABX9TyPmv/N8SYO6Rbfmi049jSlX",
"include_colab_link": true
},
"kernelspec": {
"name": "python3",
"display_name": "Python 3"
}
},
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "view-in-github",
"colab_type": "text"
},
"source": [
"<a href=\"https://colab.research.google.com/gist/dinbav/9ece8d19dc2f8668ce1fbabd0d1163fa/tweet_sensitive.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
]
},
{
"cell_type": "code",
"metadata": {
"id": "20m7AZdg8qkA",
"colab_type": "code",
"colab": {}
},
"source": [
" try:\n",
" is_sensitive = status['possibly_sensitive']\n",
" except KeyError:\n",
" is_sensitive = None\n",
" tweet_data['possibly_sensitive'].append(is_sensitive)"
],
"execution_count": null,
"outputs": []
}
]
}7. Работа с эмодзи
Кодировка может искажать данные.
Одна из проблем, обнаруженных после извлечения 8 Гб твитов заключалась в том, что где-то между кодировками записи были нечитаемые, содержали странные символы и непонятные знаки. На мой взгляд, возможной причиной этого стали эмодзи. Обратимся за примером на StackOverflow:
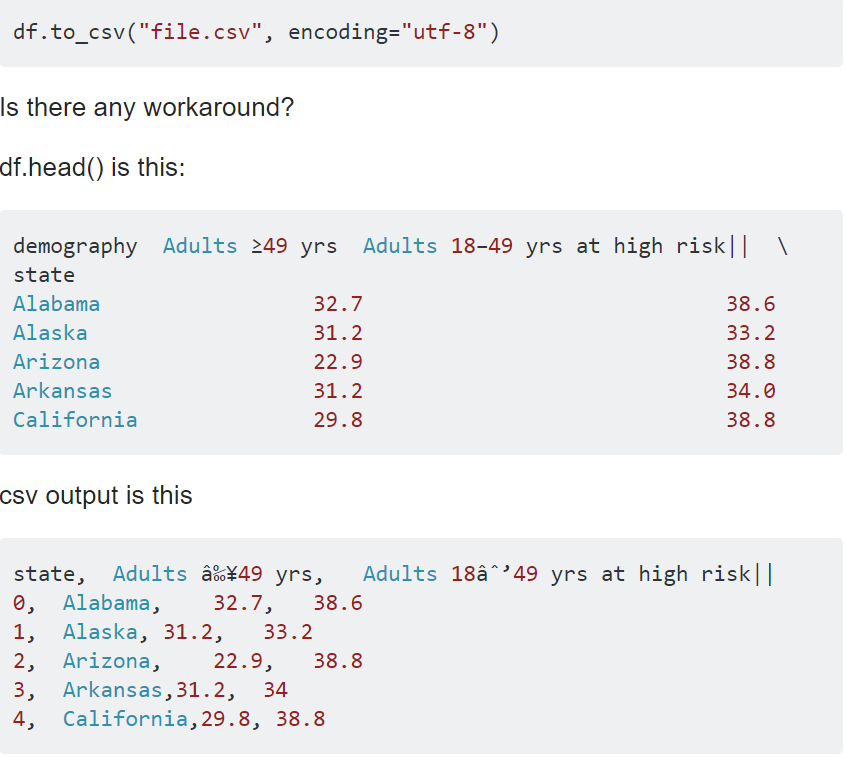
Для решения проблем с кодировкой эмодзи были сохранены как еще один элемент датафрейма. Ниже представлен полный вариант кода, включающий пакет Python demoji, который интерпретирует эмодзи.
С полным вариантом кода можно ознакомиться по ссылке.
Читайте также:
- Как создать и развернуть бота для Twitter при помощи Python, Tweepy и PythonAnywhere
- Как использовать ИИ и Python для распознавания речи
- Pydantic — гарантия надежного и безошибочного кода Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи Dina Bavli: How to Use the Tweepy Python Package





