
В этой короткой статье рассказывается про методику вэб-скрэпинга (англ. web scraping) — набор инструментов по извлечению данных с сайтов. Если вы сталкивались с проблемами экспорта нужных данных — прочитав эту статью вы научитесь извлекать любые данные с любых сайтов. Вэб-скрэпинг скоро станет обязательным навыком любого профессионального вэб-разработчика и фронтенд-программиста.
Как извлечь нужные данные?
Знакома ситуация: крайне необходимая информация недоступна — опции сохранения или экспорта на сайте отсутствуют?
Одна моя клиентка хотела получить список адресов электронной почты, но вэб-платформа не позволяла сделать экспорт этих данных — они были скрыты пользовательским интерфейсом. Клиентка уже собралась заплатить за копирование адресов вручную, но к счастью я вовремя вспомнила о вэб-скрэпинге – пока еще малоизвестном способе, который теперь уже стал одним из моих любимых средств борьбы с гнетом «большого брата». Я быстро (в течение 15 минут) взломала этот сайт и сэкономила своей клиентке много денег. Подобные проблемы не так уж и редки, поэтому я хотела бы поделиться своим опытом написания программы, которая через веб-браузер позволяет извлечь с любого сайта нужные вам данные!
Практиковаться будем на простом примере: извлечем результаты выполнения поискового запроса Google. Возможно, этот пример не так уж креативен, но зато он удобен для понимания и освоения методики.
Технические требования
1. Python (я использую версию 2.7):
— Splinter (основанный на Selenium)
— Pandas
2. Браузер Chrome
3. Chromedriver
Если у вас нет Pandas и вам лень в нем разбираться, рекомендую дистрибутив Anaconda, который наряду с Python содержит важные и полезные библиотеки.
В любом случае, скачайте полную версию, например, через pip с помощью терминала/командной строки:
pip install pandas
Если у вас не установлен Splinter (и вы не воспользовались дистрибутивом Anaconda), просто установите его через pip терминала:
pip install splinter
Если вы хотите установить виртуальное окружение (которое также обладает дополнительными преимуществами), но не знаете с чего начать, почитайте наш blog post about virtual environments.
Шаг 1: Библиотеки и браузер
Сначала мы будем импортировать все необходимые библиотеки и настраивать вэб-браузер. Итак:
from splinter import Browser
import pandas as pd
# open a browser
browser = Browser('chrome')
Если страница реагирует на ваши действия, воспользуйтесь set_window_size, чтобы убедиться, что отображаются все необходимые вам элементы.
# Width, Height browser.driver.set_window_size(640, 480)
Приведенный выше код запустит браузер Chrome. После того, как необходимые настройки браузера выполнены, давайте зайдет на вэб-страницу Google.
browser.visit('https://www.google.com')
Шаг 2: Изучим сайт
Прекрасно, мы зашли на главную страницу. Сосредоточимся на навигации по сайту — выполним два действия:
1. Найти нечто (некий HTML-элемент на странице).
2. Выполнить с этим элементом нужное действие.
Найти HTML-элемент можно воспользовавшись имеющимися в браузере Chrome инструментами раз-работчика – Web Inspector. Для этого кликните правой кнопкой мыши на вэб-странице и выберете пункт «Inspect», после чего откроется окно с правой стороны браузера. Затем кликните по иконке инспектора (она выделена красным кружком на рисунке ниже).
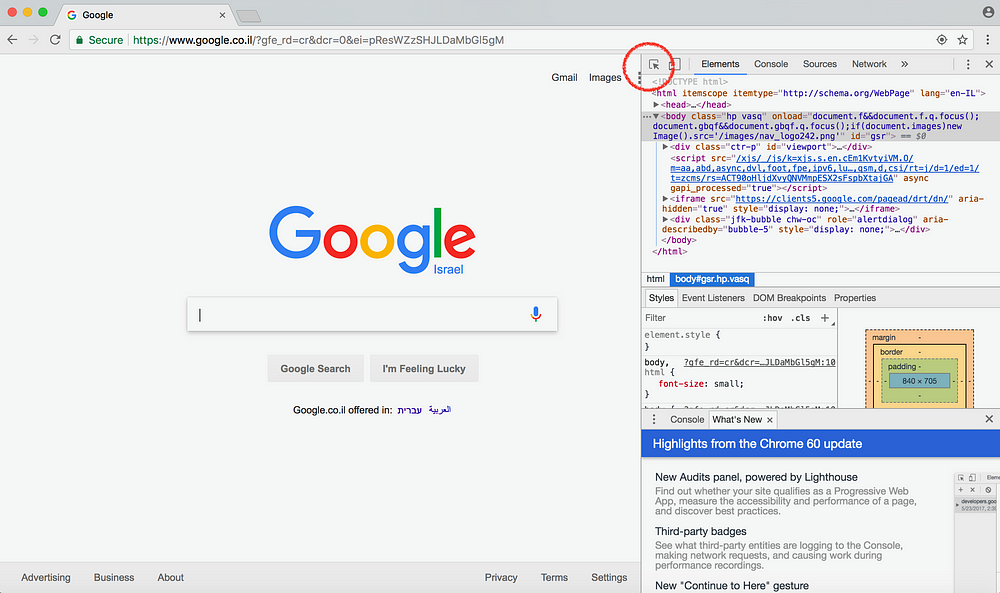
Теперь используйте курсор инспектора – кликните на раздел веб-сайта, которым вы хотите управлять. После того, как вы выделили нужный раздел курсором, HTML-код этого раздела подсветится в окне инспектора справа. Для примера я выделила панель поиска:
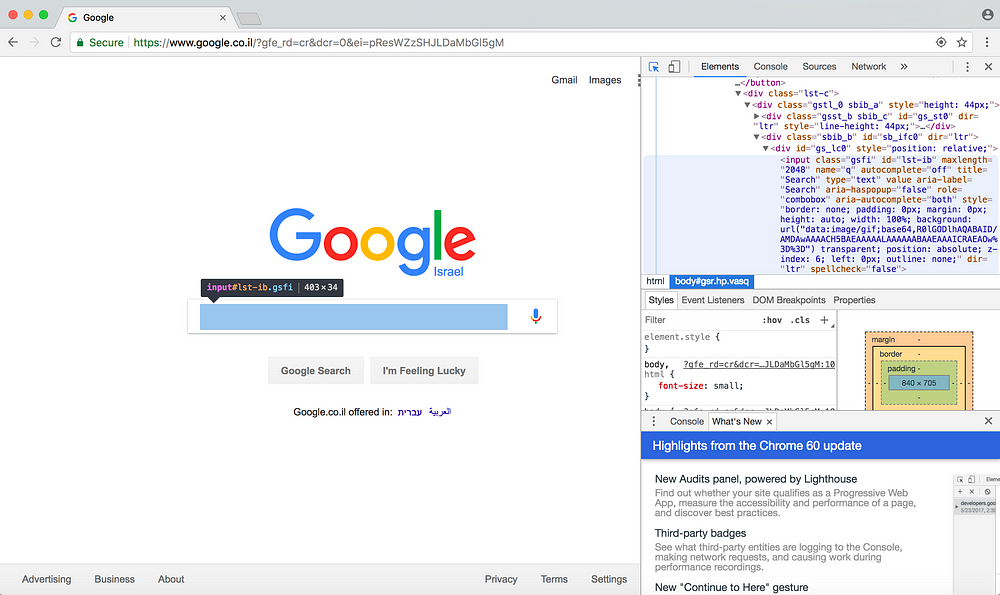
Затем по правому клику мыши на HTML-элементе выберите следующий пункт меню: «Copy»->«Copy XPath».
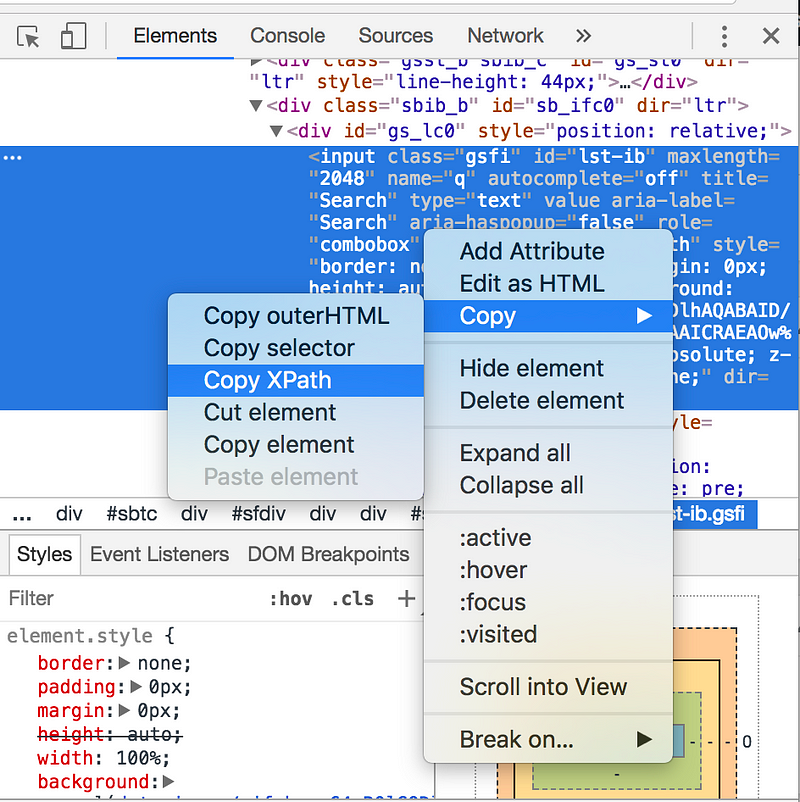
Поздравляю! Теперь у вас есть ключ от виртуального королевства! Давайте научимся пользоваться Splinter’ом, чтобы управлять этим HTML-элементом с помощью Python.
Шаг 3: Управление вэб-сайтом
Полученный только что XPath — крайне важная информация! Поэтому для начала сохраните ее в переменной Python.
# I recommend using single quotes search_bar_xpath = '//*[@id="lst-ib"]
Теперь передадим этот XPath замечательному методу объекта Splinter Browser: find_by_xpath (). Этот метод будет извлекать все элементы, соответствующие нашему XPath и вернет список объектов в Element. Если вдруг нужный элемент окажется единственным – вернется список, единичной длины. Имеются и другие аналогичные методы, например find_by_tag(), find_by_name(), find_by_text() и т. д.
# I recommend using single quotes search_bar_xpath = '//*[@id="lst-ib"]' # index 0 to select from the list search_bar = browser.find_by_xpath(search_bar_xpath)[0]
Приведенный выше код предоставляет навигацию по этому отдельному HTML-элементу. А чтобы со-брать нужные данные, можно воспользоваться двумя полезными методами: fill() и click()
# Now let's set up code to click the search button! search_button_xpath = '//*[@id="tsf"]/div[2]/div[3]/center/input[1]' search_button = browser.find_by_xpath(search_button_xpath)[0] search_button.click()
Приведенный выше код вносит в поисковую строку браузера запись «CodingStartups.com» и нажимает на кнопку поиска. После выполнения последней строки нашего кода вы получите страницу результатов выполнения поискового запроса!
Подсказка: Используйте fill() и click() для навигации по страницам авторизации 😉
Шаг 4: Собираем данные методом скрэйпинга!
Давайте теперь соберем все заголовки и ссылки, полученные в результате выполнения нашего поискового запроса.
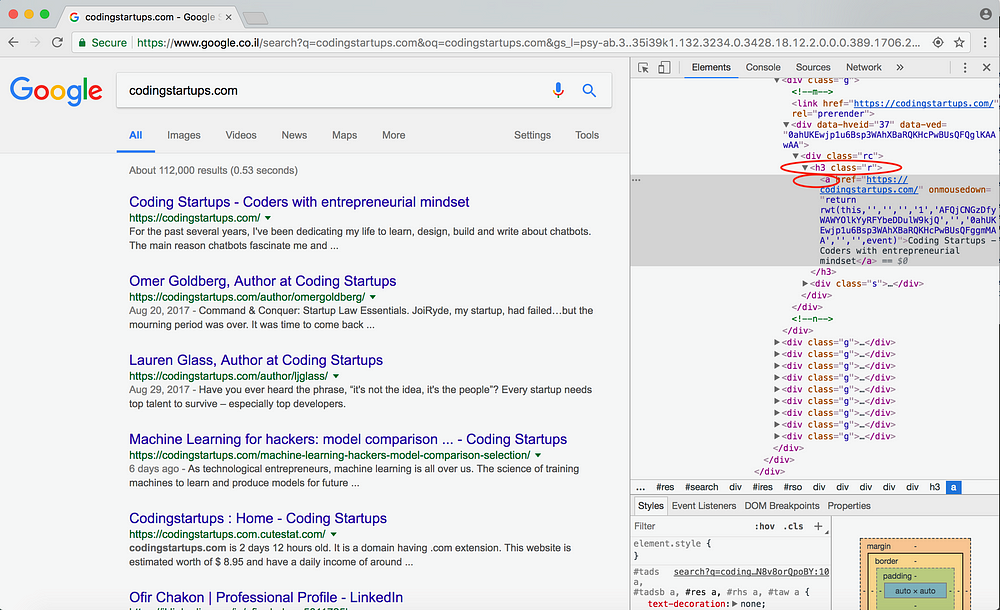
Обратите внимание – каждый результат поиска сохраняется в h3-теге с классом «r». Также обратите внимание на то, что и заголовок, и ссылка хранятся в а-тэге.
XPath этого выделенного тега следующий:
//*[@id=”rso”]/div/div/div[1]/div/div/h3/a
Но это только первая ссылка, а нам нужны все ссылки со страницы результатов поискового запроса. Поэтому внесем некоторые изменения в код, чтобы убедиться, что наш метод find_by_xpath возвращает все результаты поиска. Вот как можно это сделать (см. код ниже):
search_results_xpath = '//h3[@class="r"]/a' # simple, right? search_results = browser.find_by_xpath(search_results_xpath)
Этот XPath просит Python поискать все h3-теги класса «r». Затем внутри каждого из найденных тэгов извлечь a-тэг и все данные этого тэга.
Теперь последовательно переберем все элементы ссылки результата поиска, возвращенные методом find_by_xpath, извлечем заголовок и ссылку из каждого результата выполнения поискового запроса. Это очень просто:
scraped_data = []
for search_result in search_results:
title = search_result.text.encode('utf8') # trust me
link = search_result["href"]
scraped_data.append((title, link)) # put in tuples
Необходимость очистки данных в search_result.text иногда может сильно раздражать. Действительно, текст из Интернета выходит крайне небрежным и запутанным. На помощь здесь могут прийти несколько полезных методов очистки:
Теперь все заголовки и ссылки в виде списка записаны в scraped_data. Экспортируем наши данные в файл csv. Вместо библиотечного хаоса csv мне нравится использовать структуру данных pandas. Это две строки:
Приведенный выше код создает файл csv с заголовками Title и Link, за которыми следуют все данные из списка scraped_data. Мои поздравления – вы получили нужные данные!
Перевод статьи: Lauren Glass Mastering Python Web Scraping: Get Your Data Back
")




