
Какое чудесное платье! Стоит только поискать платья в веб-пространстве, как потом практически невозможно избежать интернет-рекламы с новыми моделями. Что же происходит при нажатии на такие коммерческие предложения? Мы попадаем на сайт магазина, где представлена подробная информация о товаре. Но вот вопрос: эти данные поступают из одного и того же сервиса или собираются из разных сервисов и отправляются пользователям? В статье мы рассмотрим второй вариант, а именно шлюз API.
Что такое шлюз API?
Шлюз API обрабатывает все API-вызовы от клиентов, направляя их к соответствующим микросервисам. Он вызывает эти микросервисы и агрегирует результаты. Шлюз API скрывает внутренние API от своих клиентов. В случае сбоя в работе микросервисов он может замаскировать их, возвращая кэшированные данные или данные по умолчанию. Он упрощает как реализацию клиента, так и приложение микросервисов, поскольку является точкой входа для каждого запроса от клиента.
Обзор проекта
Клиенты нажимают на красивое платье, чтобы получить о нем подробную информацию: id, название, описание, наличие на складе и стоимость. Однако у нас нет сервиса, предоставляющего все эти данные. Они поступают из разных источников. Мы должны агрегировать все фрагменты информации и отправить их клиентам. И здесь не обойтись без помощи супергероя, роль которого берет на себя шлюз API.
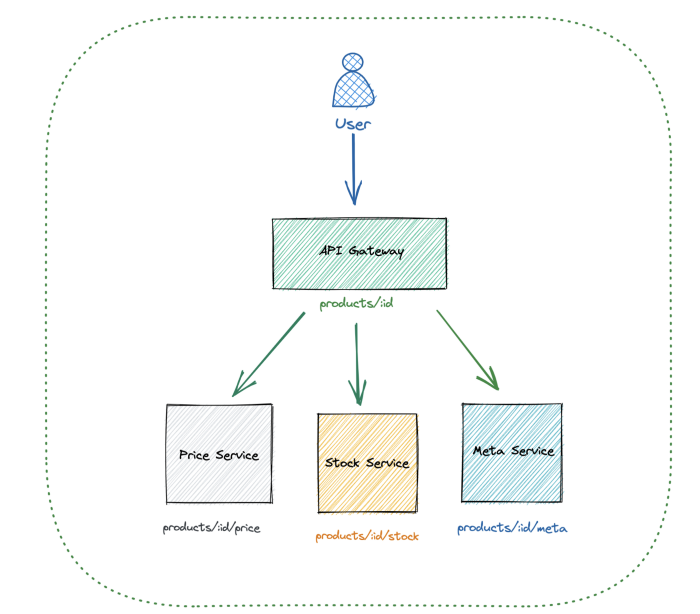
Когда клиенты хотят посмотреть платье, они отправляют запрос на шлюз с конечной точкой products/:id. Для агрегирования всех данных он передает этот запрос бэкенд-микросервисам с разными конечными точками. Если бы не было шлюза, клиенту пришлось бы направлять запрос ко всем этим микросервисам.
Принцип работы шлюза API
Шлюз должен сделать три API-вызова для агрегирования фрагментарной информации. С точки зрения производительности целесообразнее одновременно выполнять как можно больше вызовов. Шлюз намерен ответить всем клиентам, запросившим подробные сведения о платье. Не имея возможности быть повсюду в одно и то же время, он действует очень быстро, чтобы собрать воедино все необходимые данные. Шлюз должен сократить общее время ожидания. В этом деле мы помогаем ему посредством горутин:
func getProductConcurrently(c echo.Context) error {
id := c.Param("id")
p := model.Product{}
var wg sync.WaitGroup
wg.Add(3)
go getPriceFromApi(id, &p, &wg)
go getStockFromApi(id, &p, &wg)
go getMetaFromApi(id, &p, &wg)
wg.Wait()
return c.JSON(http.StatusOK, p)
}
У нас больше одной горутины по причине трех API-вызовов. Поскольку шлюз загружен, он должен узнать об окончании работы. Поэтому мы ждем выполнения трех горутин, после чего отправляем агрегированные данные клиенту.
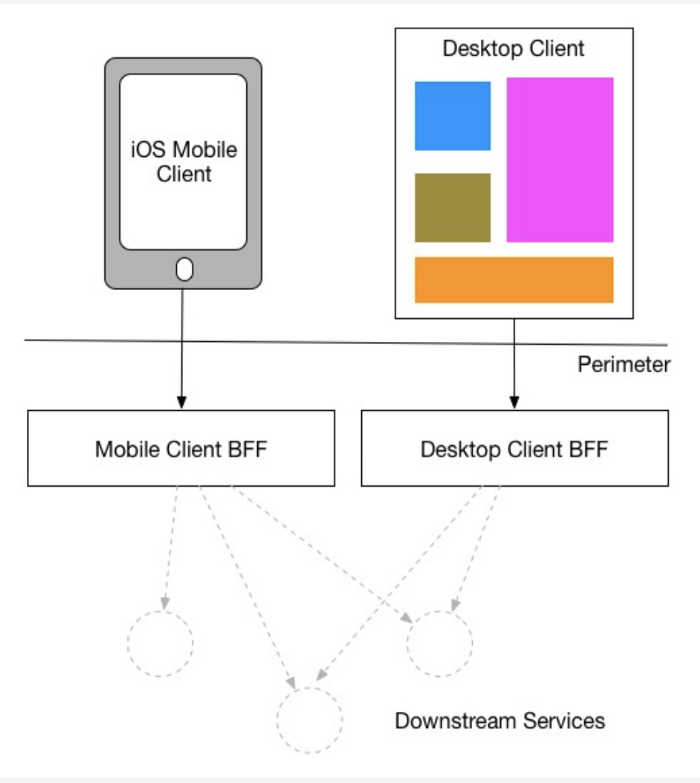
Дополнительный раздел: шаблон BFF (Backend-for-Frontend)
Предположим, у вас есть и мобильный сервис, и веб-сервис, что означает наличие разных UI. Вы знаете, что характер работы с мобильными приложениями сильно отличается от работы с настольными веб-приложениями. Что вы выберите: предоставить единый API для каждого типа клиента или по одному API для каждого клиента?
Поясним, о каких различиях идет речь. По сравнению с настольными аналогами мобильные устройства должны совершать меньше вызовов ради экономии заряда батареи и отображать разные данные. Следовательно, вместо одного общего API оба UI должны поддерживаться разными API с уникальным функционалом.
Возможно, вы уже слышали о нисходящих и восходящих сервисах. Эти термины используются для описания направления цепочки зависимых запросов к сервисам.
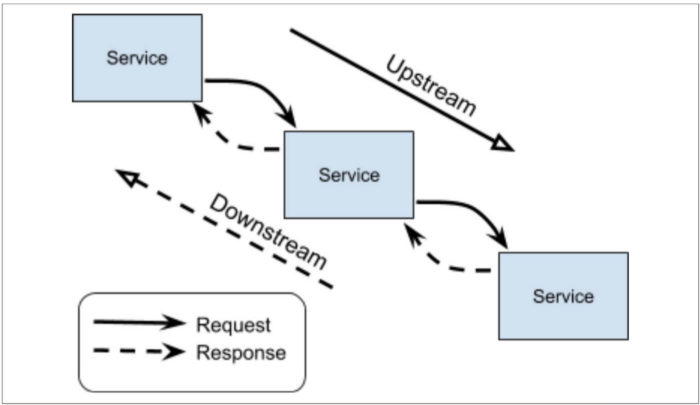
Сервис нисходящего направления инициирует запросы и получает ответы. Сервис восходящего направления получает запросы и возвращает ответы.
Исходный код можно найти здесь.
Читайте также:
- Шаблон Flyweight (Приспособленец) на Go
- Создай приложение Go и соревнуйся в реальном времени
- Отладка Go для профессионалов
Читайте нас в Telegram, VK и Дзен
Перевод статьи Dilara Görüm: Here’s a Lovely Dress to Understand API Gateway With Golang





