
Итак, начнем! Прежде всего, установим библиотеку xLearn с помощью команды pip:
pip install xlearn
Для импорта библиотеки xlearn используем следующую команду:
Если у вас возникнут проблемы при импорте xLearn, попробуйте проделать шаги, приведенные в этом ответе на GitHub.
МО-модели в xLearn
В настоящее время xLearn поддерживает три алгоритма машинного обучения:
- линейную модель (linear model, LR);
- машину факторизации (factorization machine, FM);
- машину факторизации с учетом полей (field-aware factorization machine, FFM).
Рассмотрим каждый из них в отдельности.
Линейная модель
Импортируем линейную модель из xLearn следующим образом:
Линейная модель используется для нахождения той линии, которая идеально определяет отношения между переменными X и Y. Линейные модели можно применять, когда переменная Y является непрерывной, а X — непрерывной/категориальной.
Машина факторизации
Импортируем модель FM из xLearn следующим образом:
Машина факторизации может использоваться для задач регрессии и классификации. Это расширенная версия линейной модели, применяемая для выявления взаимодействия признаков в наборе данных высокой размерности. Она хорошо работает на высокоразмерных наборах данных.
Машина факторизации с учетом полей
Импортируем модель FFM из xLearn следующим образом:
Модель FFM является улучшенной версией модели FM, поскольку в нее внесены определенные исправления.
Ключевой момент, упомянутый на сайте библиотеки: для LR и FM формат входных данных может быть CSV и libsvm. Для FFM входные данные должны быть в формате libffm.
Простой пример
Предположим, вы работаете с проблемой бинарной классификации и хотите предсказать, кликнет ли пользователь на рекламу сайта. Для решения такого типа задач требуется набор данных высокой размерности, который включает множество характеристик пользователя, что позволяет лучше понять события, связанные с его кликами.
В этой статье small_test.txt назовем тестовыми данными, а small_train.txt — обучающими.
Для решения этой задачи мы будем использовать библиотеку xLearn. Сначала импортируем ее.
Затем выберем МО-модель xLearn. Поскольку решается задача классификации, у нас есть два варианта на выбор:
- машина факторизации;
- машина факторизации с учетом полей.
Мы не можем выбрать линейную модель, поскольку она используется для решения задач регрессии. Выбираем второй вариант, т.е. FFM.
Создадим модель с помощью библиотеки xLearn.
Можно было бы использовать функцию sklearn train test split для разделения данных на два типа набора: train (обучающий) и test (тестовый). Поскольку я создал отдельный файл для каждого типа, нам не понадобится прибегать к sklearn.
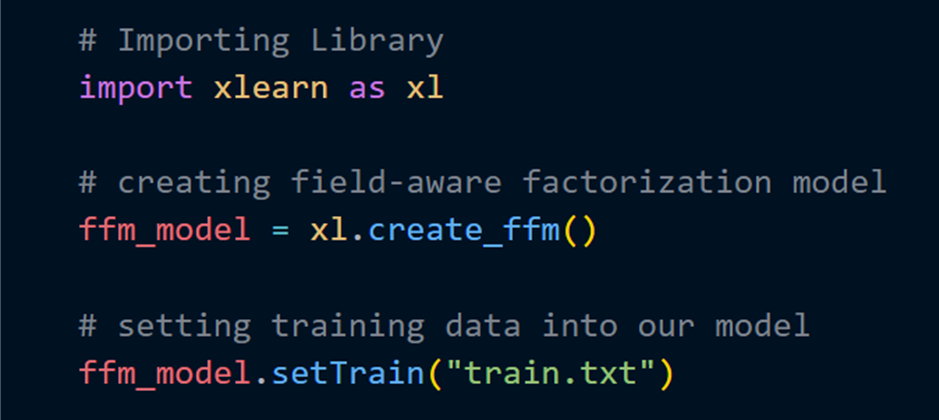
SetTrain сообщает модели FFM о наборе обучающих данных.
Теперь определим параметры для модели FFM.
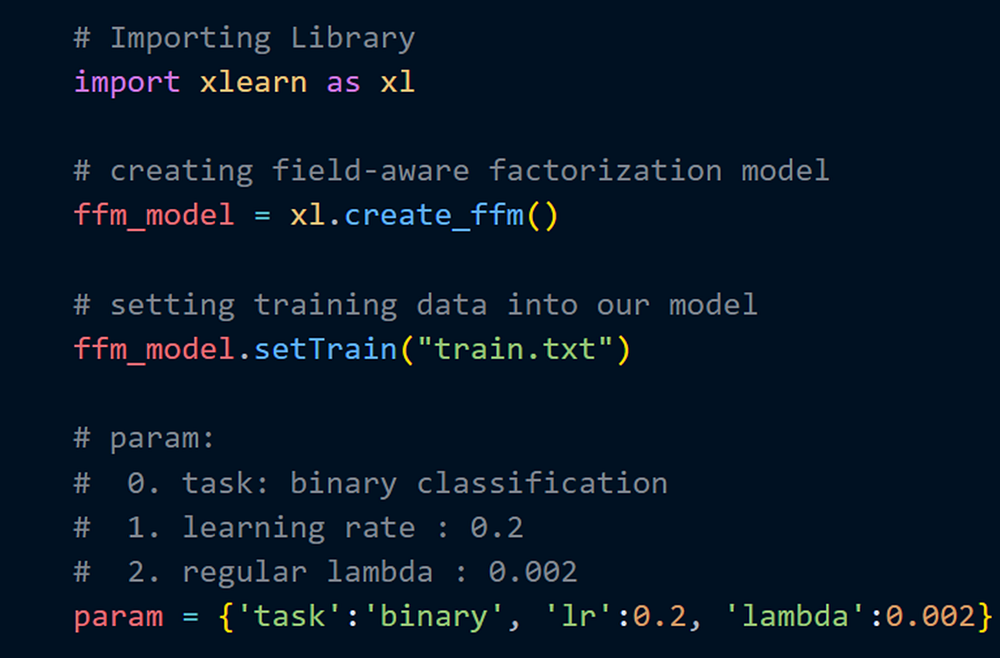
Назначение каждого параметра:
task(тип решаемой задачи). В данном случае решается задача бинарной классификации. Если бы вы работали с задачей регрессии и использовали при этом FFM-модель, нужно было бы передатьregв переменнуюtask.learning rate(скорость обучения). Наверняка вы уже использовали этот параметр ранее. Цель здесь та же — заставить модель обучаться быстрее.- Lambda. Мы работаем с большим набором данных, поэтому лямбда играет здесь важную роль — отбрасывает переменные, которые наименее важны.
При решении задачи регрессии значения параметров должны выглядеть следующим образом:

Теперь нужно подогнать модель к обучающему набору данных.
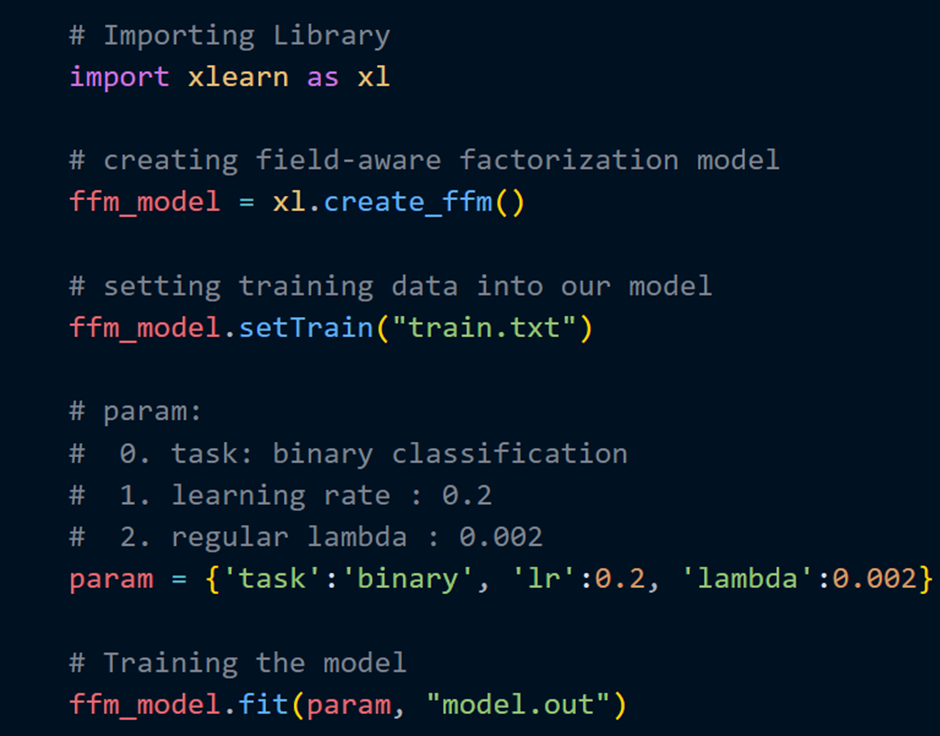
Подгонка модели выполняется с помощью метода .fit(), который передает переменные параметров (param) вместе с именем модели. В текущем каталоге будет создан новый файл с именем model.out. Этот model.out будет использоваться для прогнозирования тестового набора данных.
Запустив код, получим на выходе нечто подобное:
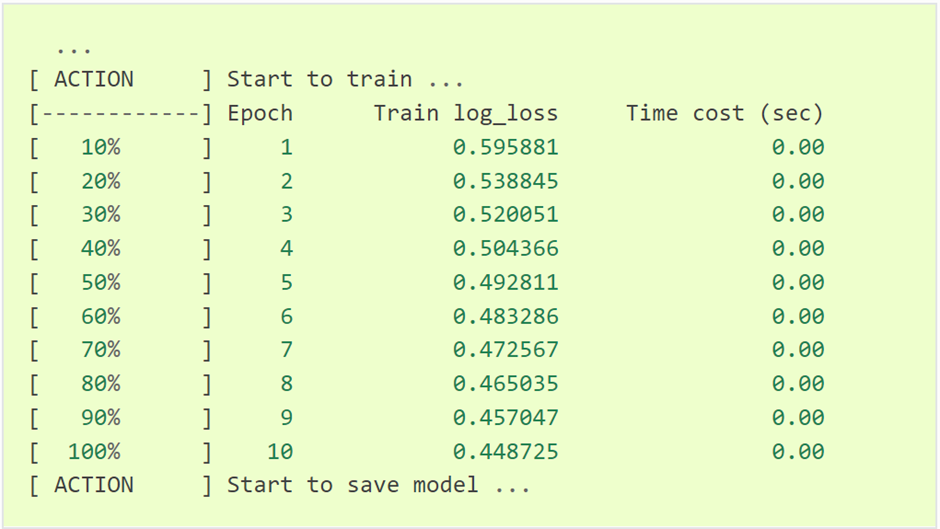
Это обучение модели на обучающем наборе данных. После его завершения модель будет сохранена в текущем каталоге.
Теперь используем файл model.out для прогнозирования тестовых данных:
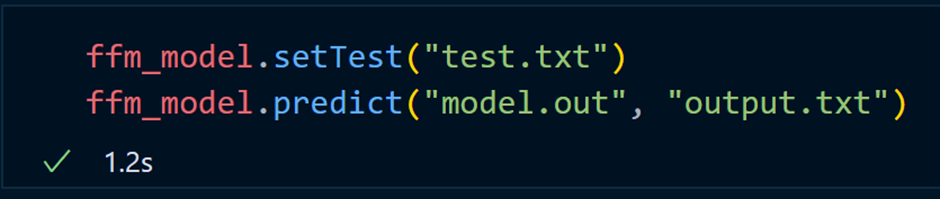
В приведенном выше коде сообщаем модели о тестовом наборе данных, предсказываем его, а затем сохраняем предсказанные значения в файле output.txt.
Вот как выглядит output.txt:
-1.58631
-0.393496
-0.638334
-0.38465
-1.15343
Отрицательные значения показывают, что пользователь не собирается нажимать на рекламное объявление, в то время как положительные значения демонстрировали бы готовность пользователя кликнуть на него. Если хотите, чтобы вывод был 0 или 1, можете использовать метод setSign().
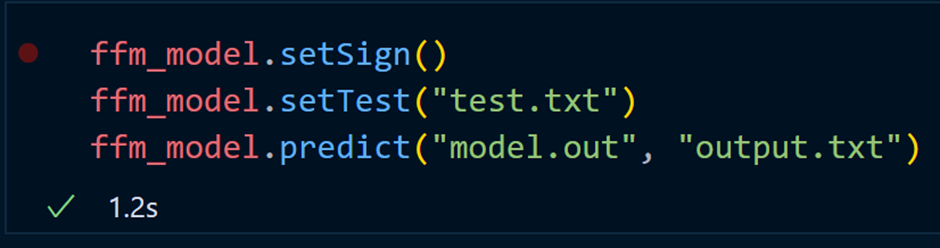
Теперь файл output.txt выглядит следующим образом:
0
0
0
0
Читайте также:
- Обучение Inception в Google распознаванию пользовательских изображений
- Обнаружение фейковых новостей с помощью машинного обучения
- Как обнаружить злые твиты при помощи машинного обучения
Читайте нас в Telegram, VK и Дзен
Перевод статьи Fareed Khan: Solve Large Scale Machine Learning Problem in Python




