
Почему иногда люди пишут подобный код?
var = float(str(alist[::-1][0]).split()[1:4])/3+float(alist[4:])
Ответ прост: чтобы сэкономить вычислительное время. Стоит только написать это в четыре строки…
var = alist[::-1][0]
var = str(var).split()[1:4]
var = float(var)/3
var += float(alist[4:]…составители бюджета вычислительной стоимости качают головами и выбирают однострочный вариант.
По их словам, множественное присвоение переменной занимает так много вычислительного пространства, что количество итераций в коде имеет существенное значение.
В этой статье я измерю истинную вычислительную стоимость написания чистого кода с множественным присвоением переменных и несколькими тестами.
Первое — преимущества множественного присвоения переменной
Разработчики часто помещают несколько операций в одну строку, особенно в таких языках, как Python, в которых существует как минимум десяток способов написать что-либо.
Множественное присвоение переменных позволяет читателю воспринимать функции маленькими группами. Кроме того, оно упрощает ориентирование в скобках при применении более трёх функций Python:
list(str(int(x)+1)+'1') # это невероятно трудно читать.
Более того, сложно отследить состояние переменной, когда все состояния записаны в одну строку. Это как преподавание математики — преподаватель начинает с арифметики и только потом переходит к дифференциальному исчислению, вместо того, чтобы проходить их одновременно.
Множественное присвоение переменных означает, что читателю значительно проще отслеживать состояние и статус переменной в коде, состоящем из четырёх строк, а не из одной.
Во множестве случаев, множественное присвоение переменных экономит вычислительное время. Возьмём, к примеру:
a = (b+5)*5 + (b+5)/4
что можно записать так:
c = b+5
a = c*5 + c/4(b+5) присваивается только одной переменной, значит, её вычисление производится только один раз.
Тестирование на списках Python и встроенных функциях
Вот тест вычислительного времени, который использует несколько типовых встроенных функций Python, таких как str(), индексация списка и математические операции:
float(int(str(alist[::-1][0]).split()[::-1][0])/int(alist[:4][0]))/3
что можно записать так:
var = str(alist[::-1][0]).split()
var = int(var[::-1][0])
var /= int(alist[:4][0])
var = float(var)/3“alist” генерируется как:
alist = [random.randint(1,10) for j in range(100)]
Время, использованное для генерации списка, не включается в общее время. Единственная синхронизированная операция — строки кода, выполняющие тестовые операции.
Эта операция выполнялась 5,000,000 раз с разными сгенерированными alist для каждого запуска.
Среднее значение взято каждые 100,000 раз и нанесено на график; словом “cleaned” обозначена четырёхстрочная версия, а “shortened” — однострочная:
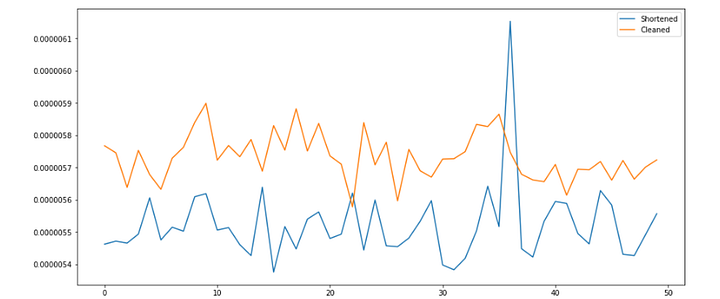
Укороченная версия очевидно работает почти всегда быстрее, но на таком небольшом масштабе выгоды почти нет.
Среднее время выполнения укороченной версии — 0.000005521, а чистой версии — 0.000005733. Разница составляет 0.000005521.
То есть, чтобы увидеть разницу в 1 минуту, процесс должен выполниться не менее 10,867,596 раз, а чтобы увидеть разницу в 1 час — не менее 652,055,786 раз.
Тестирование на Pandas DataFrames
Дополнительным тестом будет выполнение операций над Python Pandas DataFrames. Это основной тип данных в машинном обучении и науке о данных в Python, напоминающий электронные таблицы Excel.
Тестовая операция:
df.loc[1:100][df.loc[1:100] > 5][‘b’].dropna().std() — df.loc[1:100][df.loc[1:100] < 5][‘a’].dropna().mean()
Где df — это DataFrame. Документация:
data.loc[x:y]выделяет строки данных с индексами от x до y включительно;data[data[‘column’] > 5]выделяет строки данных, чьи столбцы больше пяти (или любые другие условия), и возвращаетnanдля строк, не соответствующих критериям;data.dropna()удаляет любые строки, имеющие значениеnan;column.std()принимает стандартное отклонение столбца или числовой последовательности;column.mean()принимает среднее значение столбца или числовой последовательности.
Тестовую операцию разделим на шесть строк с тремя переменными:
result0 = df.loc[1:100]
result = result0[result0 > 5][‘b’]
result = result.dropna().std()
result2 = result0[result0 < 5][‘a’]
result2 = result2.dropna().mean()
result = result — result2Тестовая операция производилась на случайно сгенерированном DataFrame с двумя столбцами — a и b — и 200 строками. Все значения случайно выбраны из диапазона от 1 до 10 включительно.
В обеих версиях — и в укороченной, и в чистой — тестовая операция была запущена 50,000 раз со средним значением, взятым каждые 1,000 раз. Каждое повторение производилось на новом случайно сгенерированном DataFrame.
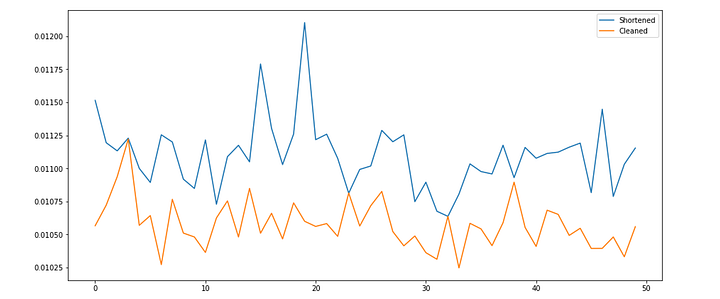
Интересно! Чистый код в среднем справляется лучше укороченного.
В среднем укороченный код выполнялся за 0.0111 за итерацию, а средний чистый — за 0.0106.
Разница в 0.0005 означает, что написание чистого кода при работе с операциями DataFrame сэкономит 1 минуту вычислительного времени за 120,000 итераций и 1 час за 7,200,000 итераций.
Заключение
Важный урок — пишите чистый код! Не бойтесь роста вычислительного времени из-за множественного присвоения переменной.
Не бойтесь использовать множественное присвоение! Не только потому, что оно увеличивает читаемость кода, но в некоторых случаях, что демонстрирует наш эксперимент с Pandas DataFrame, улучшает производительность вычислений.
Если вы хотите повторить эти эксперименты, исходный код и выводы доступны на Kaggle по ссылкам ниже:
Читайте также:
- Максимальная производительность Pandas Python
- 3 функции Pandas, которые стоит использовать чаще
- Вы умеете говорить на Python?
Перевод статьи Andre Ye: The Computational Cost of Writing Clean Code





