
Однажды летом мама угостила меня горячей содовой с лаймом. Зачем же подогревать охлаждающий напиток? Мама объяснила, что лайм, соединяясь с горячей водой, превращается из кислоты в основание. По ее словам, такой напиток может убивать раковые клетки — она узнала это из социальных сетей.
Удивительный факт! А что если это просто обман? Оказалось, что так и есть.
Люди верят тому, во что хотят верить, даже в полную бессмыслицу
Уверенность в том, что содовая с лаймом может убивать раковые клетки и другие болезни, до сих пор широко распространена в социальных сетях Таиланда. Этот слух возник семь лет назад и продолжает распространяться по сей день. Тем самым подтверждаются выводы исследования, показавшего, что люди плохо распознают фальшивые новости.
Только 17% участников смогли определить фальшивые новости с вероятностью выше обычной случайности, и лишь один из них выявлял их более чем в 60% случаев. Другими словами, большинство пользователей социальных сетей вынесли бы более верные суждения, подбросив монетку.
Как решить эту проблему?
Чтобы решить проблему фейковых новостей, важно сначала понять, что это такое.
Фейковые новости — это контент, созданный с целью ввести читателей в заблуждение. Одной из важнейших характеристик фейковых новостей является то, что в них часто используются эмоционально окрашенные слова и сатира, а также допускаются опечатки. Иногда фальшивые новости используются для того, чтобы подтолкнуть к покупке товаров и услуг.
Что общего у фейковых новостей?
Все они манипулируют эмоциями людей. Именно поэтому модели обработки естественного языка (NLP) и машинного обучения могут выявлять закономерности в них.
Посмотрим, чего достигли МО-специалисты в решении задачи классификации фейковых новостей в Таиланде. В ходе исследования в области здравоохранения предварительно обученная модель BERT смогла определять фейковые новости с точностью 94,1%, а модель WangchanBERTa — с точностью 89,5%.
Это впечатляет. Посмотрим, можно ли добиться большего.
Примечание. Поскольку мы будем классифицировать текст, в качестве метрик будут использоваться правильность, отклик, точность и F1.
Наборы данных
Начнем с данных. Мы будем использовать набор LimeSoda. В нем собраны фейковые новости из области здравоохранения, составляющие большинство фейковых новостей в Таиланде. Из 7191 новостной статьи 2570 — фейковые, 2081 — реальные, 2540 — неидентифицированные.
Проблема с классом “неидентифицированные”
Первые два класса — фейковые и реальные — не вызывают трудностей в отличие от неидентифицированных. Проведя проверку фактов в этом классе, я обнаружил комбинацию фальшивых новостей и новостей, которые не проверялись и не могут быть проверены. Поэтому данный класс не будет использоваться для обучения модели.
Я также собрал фейковые новости из государственных источников и страниц для проверки фактов. Проблема в том, что новости представляют собой картинку с мелким текстом. С помощью распознавания текста не удалось добиться хорошего качества на этих изображениях. Так что эти данные также не будут привлечены к обучению модели.

Распределение классов
На диаграмме ниже представлено распределение новостных документов. Были удалены неидентифицированные элементы, немаркированные данные и элементы-дубликаты.
Голубым отмечены фейковые новости, синим — реальные.
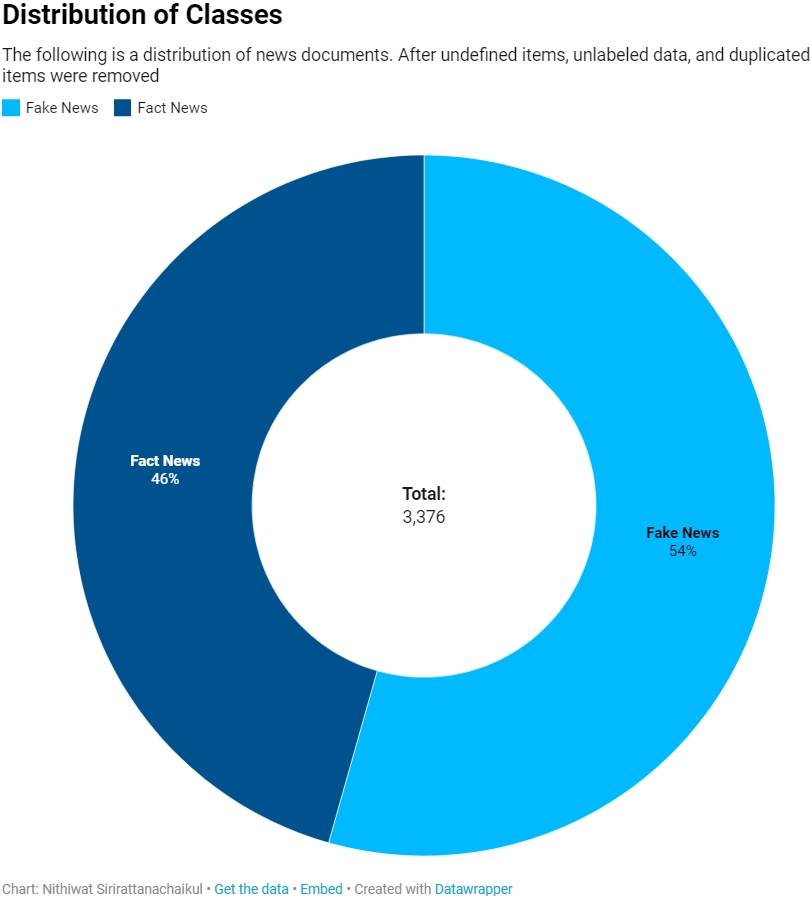
В целом, в итоговых данных медианное значение по количеству слов составляет 366 слов, а мода — 20 слов. Среднее количество слов — 419.

Разделим данные на три части: обучающий набор для обучения модели (темно-синий цвет), валидационное множество для проверки (светло-синий цвет) и тестовый набор для тестирования (голубой цвет).
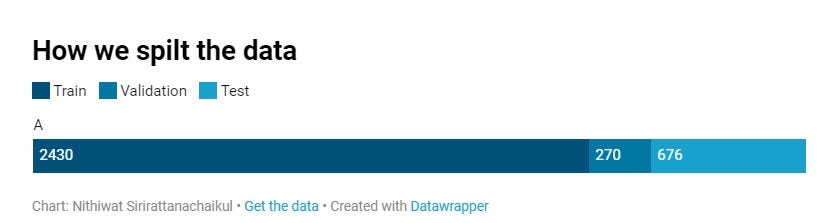
В качестве дополнения к обучающему набору данных выполним обратное преобразование. При этом изменяются некоторые собственные существительные и имена, но тексты по-прежнему имеют характерные черты фейковых новостей.
Моделирование
После получения данных переходим к обучению модели. Мы передаем набор данных алгоритму машинного обучения, чтобы он научился предсказывать и классифицировать данные. Существует множество различных алгоритмов МО, каждый из которых имеет свои сильные и слабые стороны. Поэтому важно выбрать подходящий для решения поставленной задачи, и таковым не является модель, подобная BERT.
Начинаем с настройки простой модели BERT&Linear на наборе данных (добавим обратный вызов ранней остановки, чтобы предотвратить чрезмерное обучение). В результате модель показала результат 89,67% на тестовой выборке, что соответствует результатам, представленным в статье по датасету LimeSoda.
В ходе тестирования модели также использовались триплетные потери, осуществлялась замена классификационной головки модели BERT на LSTM. Кроме того, обучение модели проводилось на расширенном наборе данных, что немного улучшило результаты тестирования.
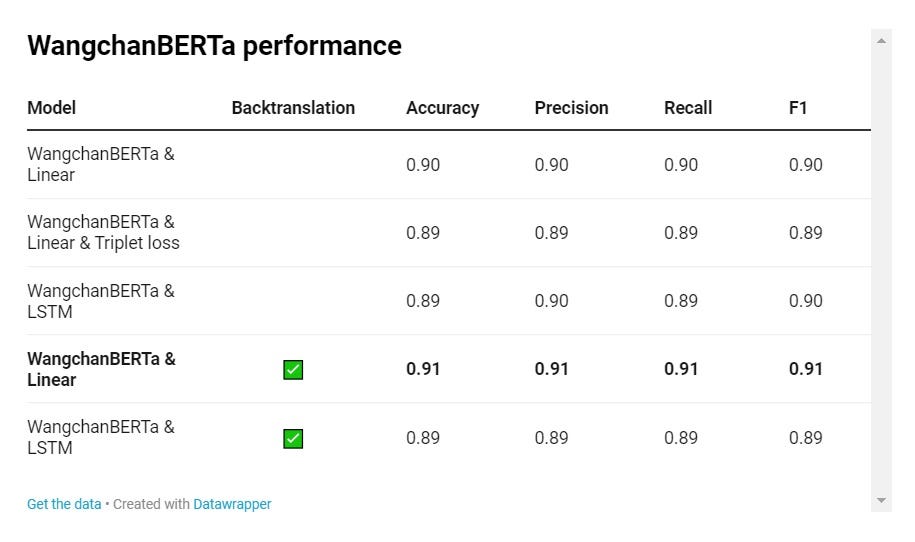
После настройки BERT стало понятно, что простая МО-модель не справилась с обучением. Поэтому я попробовал реализовать извлечение признаков TF-IDF с помощью нескольких известных моделей машинного обучения: KNN, LR, SVM и XGB. Результаты оказались удивительными: эти модели показали себя наравне с WangchanBERTa. А при обучении на расширенном наборе данных результаты были даже немного выше.
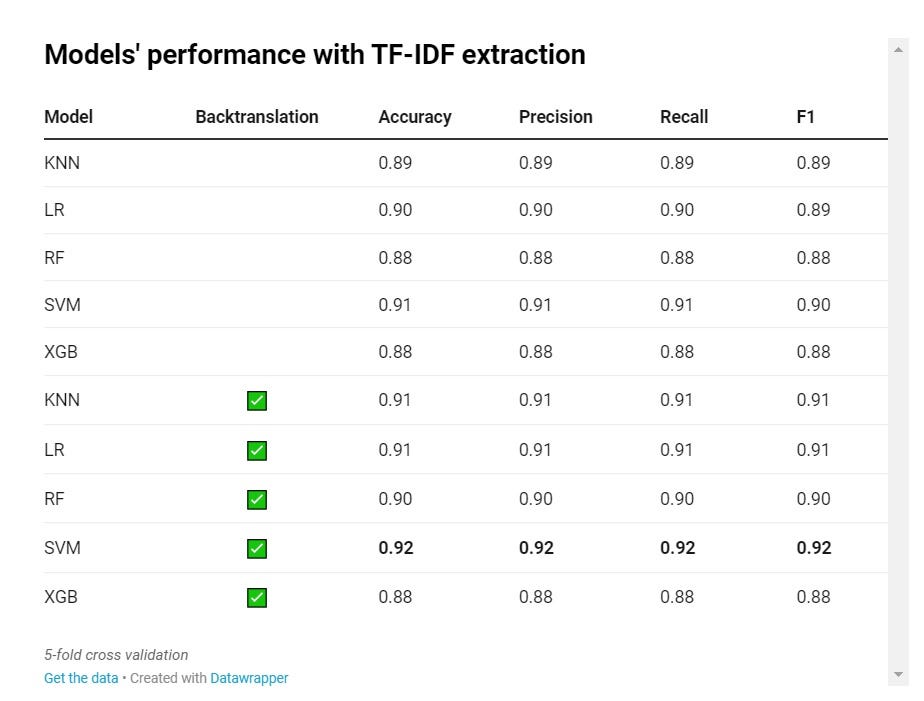
Я усвоил урок, связанный с небольшим набором данных: задача классификации фейковых новостей требует модели, которая способна обнаруживать специфические слова и паттерны — и BERT не всегда для этого годится.
Анализ ошибок
Довольно хвастаться результатами работы моделей — проведем анализ ошибок. Нам нужно понять, как модель воспринимает новости, и определить, почему она дала именно такие результаты.
Одним из распространенных способов анализа ошибок является построение матрицы неточностей. Она показывает, как часто модель предсказывала каждый класс, и помогает увидеть, где модель наиболее точна, а где справляется хуже всего.
В данном случае лучшая модель (TFIDF & SVM) работает немного хуже в классе “реальные новости”. Однако матрица не объясняет, почему она допустила эти ошибки. Поэтому нужно исследовать, как модель видит данные, чтобы понять, почему она дала такие результаты.
Для объяснения прогноза модели машинного обучения используем Python-библиотеку Lime, которая позволяет получать объяснения для моделей “черного ящика”. Lime можно использовать для различных моделей, включая все описанные выше.
На скриншоте ниже представлено одно из объяснений Lime того, как модель может путать реальные новости с фейковыми. По заключению Lime, некоторые фактические новости содержат внутри себя фейковые новости и обладают многими характеристиками фейковых новостей, что приводит модель в замешательство. Это может служить причиной неточных прогнозов и более высокой вероятности ложноположительных срабатываний.

Развертывание
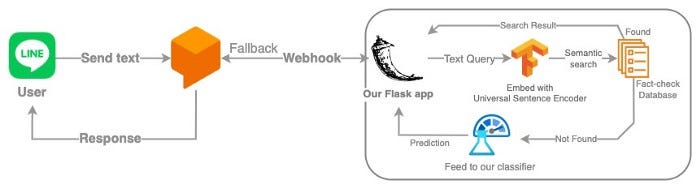
Я создал чат-бота с помощью Dialogflow. Когда пользователь отправляет данные, он классифицирует намерения. Предположим, что сообщение, которое принял чат-бот, является не приветствием и репликой, приглашающей к беседе, а фейковой или реальной новостью, которую необходимо классифицировать. Он вернет намерение Fallback и веб-хук для приложения Flask (которое работает на Google Compute Engine).
Сначала приложение сопоставляет текст запроса с базой данных для проверки фактов (контент из надежных источников и от независимых фактчекеров). Universal Sentence Encoder (универсальный кодировщик предложений), используемый для проведения семантического поиска, позволяет избежать неэффективных предсказаний в отношении новостей с проверенными фактами. При несоответствии запроса новости будут переданы классификатору, и прогноз будет отправлен обратно пользователю.
Вот скриншот такого чат-бота.

Более подробную информацию можно найти в GitHub-репозитории проекта.
Читайте также:
- #04TheNotSoToughML | “Давай, минимизируй ошибки” — Но достаточно ли этого?
- Как легко развертывать модели МО в 2022 году с помощью Streamlit, BentoML и DagsHub
- Исследование операций: что, когда и как
Читайте нас в Telegram, VK и Дзен
Перевод статьи Nithiwat Sir: Detecting Thai Fake News with Machine Learning





