
Введение
Вы создали модель машинного обучения. Что делать дальше? Хранить в ноутбуке Jupyter, как ценный актив, чтобы ее никто не видел? Вместо этого лучше самым простым и доступным образом дать возможность другим пользователям экспериментировать с вашей работой и делиться ей. Другими словами, модель необходимо развернуть.
Как это сделать? Просто распространить модель в виде файла? Такой вариант не подойдет.
А может в виде контейнера Docker? Это более удобный способ: пользователь получит необходимые данные для локального запуска модели. Однако делать это все равно придется в среде программирования, что не очень удобно.
А как насчет API? Довольно тяжело объяснить его принцип работы человеку, далекому от программирования.
А если создать веб-приложение? Это самый лучший вариант. Но разве для этого не нужны специальные знания?
К счастью, ничего из вышеперечисленного делать не придется. В этой статье представлен метод развертывания, который позволит представить модель в виде API, контейнера Docker и веб-приложения — и все это за несколько минут с помощью пары коротких скриптов Python.
Задачи
Этот метод развертывания работает с архитектурами всех моделей из любых фреймворков машинного и глубокого обучения. Мы будем использовать датасет Pet Pawpularity.
В Petfinder.my представлен набор изображений кошек и собак, каждому из которых присвоены очки “милоты” с помощью встроенных алгоритмов оценки.

Мы рассмотрим, как развернуть модель регрессии изображений Keras в виде API и веб-приложения, чтобы сделать ее доступной как для программистов, так и для обычных пользователей.
Инструменты для развертывания
Выбрать лучшие инструменты для представления моделей в продакшене довольно трудно, потому что все проблемы уникальны, а их решения имеют различные ограничения.
Поэтому я пытался подобрать решение, которое принесет пользу как можно большему числу людей. Оно должно быть достаточно простым, чтобы на создание рабочего прототипа и представление его в сети ушло всего несколько минут, а при необходимости его можно было бы масштабировать для решения более крупных задач.
Основной компонент этого решения — пакет BentoML, один из последних перспективных игроков на рынке MLOps.
Его цель — представлять модели МО как конечные точки API с минимально возможным количеством строк кода и без недостатков других фреймворков, таких как Flask. Он работает практически с любым фреймворком машинного обучения:


Если вы хотите увидеть готовое решение, перейдите по этой ссылке. Там вы найдете развернутый API, который будет создан в этом руководстве.
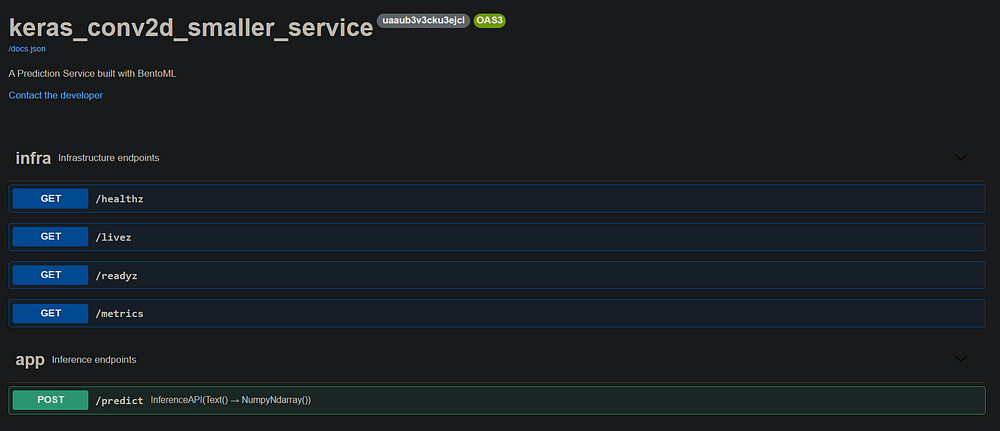
Развертывание не должно ограничиваться только API, поскольку они предназначены лишь для программистов. Нам нужно решение, с которым смогут взаимодействовать люди, не связанные с программированием. И тут на помощь приходит Streamlit.
Streamlit — библиотека для создания минималистичных веб-приложений любого типа на базе машинного обучения.
Поскольку мы создаем интерфейс Streamlit на основе API, то веб-приложение получится еще более простым. Проблем с зависимостями не возникнет, так как нам понадобится только библиотека requests для обработки запросов к API BentoML через приложение Streamlit.
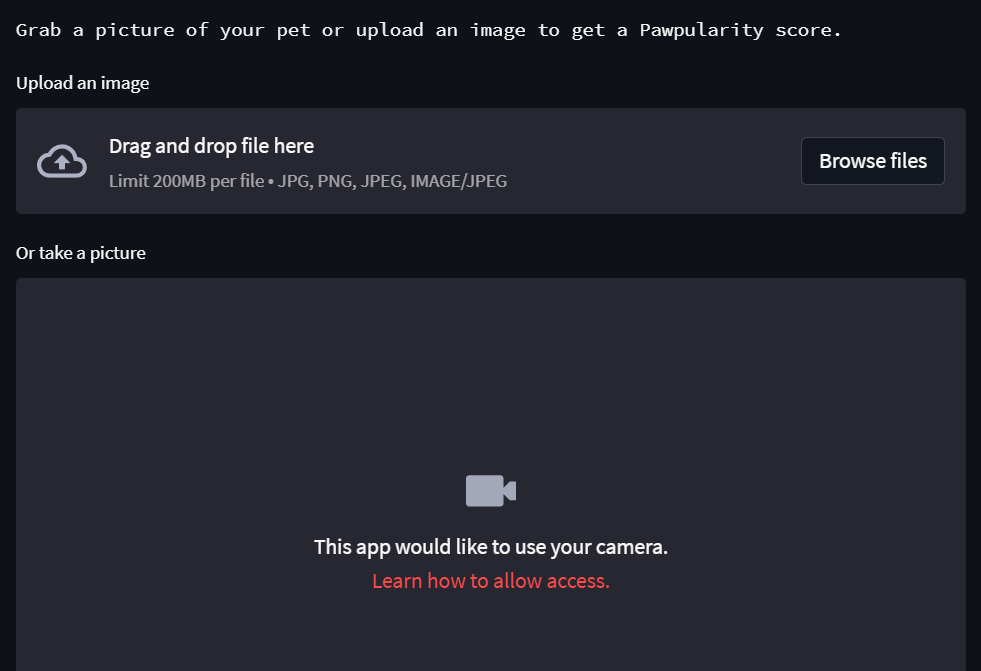
Ниже представлено приложение, которое мы создаем:
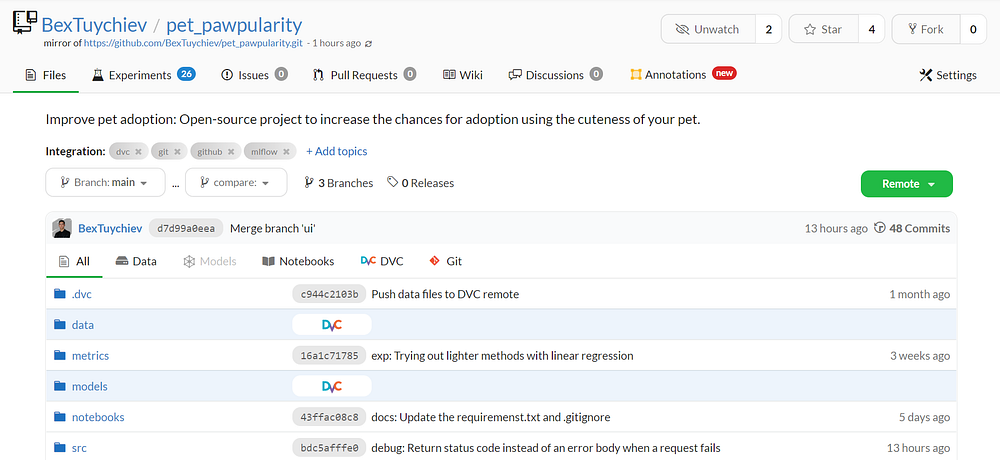
Для управления проектом мы будем использовать DagsHub — GitHub для профессионалов в области данных, позволяющий выполнять всестороннее машинное обучение.
Репозиторий DagsHub используется для многих задач.
- Хостинг кода: имеет полную поддержку Git (как и GitHub).
- Хранение: имеет выделенное хранилище для данных и моделей, управляемое DVC.
- Отслеживание экспериментов: поддерживает MLflow Tracking и Git Tracking.
Жизненный цикл машинного обучения — это не только развертывание. Чтобы модель успешно работала в продакшене, ей необходим прочный фундамент в инфраструктуре, который позволяет создать DagsHub.
Теперь перейдем к основной части статьи и разберемся, как использовать BentoML для создания конечной точки API для сервиса прогнозирования.
Шаг 1. Сохранение лучшей модели в локальном хранилище BentoML
Все фрагменты кода в этом разделе взяты из репозитория проекта training.py.
Начнем с импорта необходимых библиотек:
import logging
import bentoml # pip install bentoml --pre
import joblib
import tensorflow as tf
Убедитесь, что установили bentoml с тэгом --pre, так как он находится на стадии превью.
С помощью кода ниже мы создадим несколько вспомогательных функций для построения и обучения сверточной нейронной сети Keras:
def get_keras_conv2d():
""" Функция для построения экземпляра модели Keras conv2d."""
model = ...
return model
def fit_keras_conv2d():
"""
Функция для обучения модели Keras conv2d.
"""
model = get_keras_conv2d()
#-- Подгонка модели с помощью ранней остановки и 30 эпох на изображениях --#
return model
Здесь опущено тело первой функции, которая создает экземпляр Conv2D с тремя скрытыми слоями и исключаемыми слоями MaxPool между ними. Не будем уделять слишком много внимания архитектуре модели.
fit_keras_conv2d использует первую функцию для обучения полученной модели с помощью метода ранней остановки и 30 эпох.
Далее создаем функцию для сохранения модели в локальном хранилище BentoML:
def save(model, bentoml_name, path):
"""
Функция для сохранения модели в локальном хранилище BentoML с помощью joblib.
"""
bentoml.keras.save(bentoml_name, model, store_as_json_and_weights=True)
joblib.dump(model, path)
Функция keras.save сохраняет модели Keras в формате, подходящем для других операций BentoML.
Выполним эти функции для получения готовой модели:
def main():
model = fit_keras_conv2d()
logging.log(logging.INFO, "Saving...")
save(model,
"keras_conv2d_smaller",
"models/keras_conv2d_smaller.joblib")
logging.log(logging.INFO, "Done!")
if __name__ == "__main__":
main()
Завершив обучение и сохранение, выполните следующую команду, чтобы получить список моделей, находящихся в хранилище BentoML:
$ bentoml models list

В документации BentoML сохраненные модели официально называются тегами. По умолчанию все модели будут сохранены в домашнем каталоге в папке bentoml/models со случайным тегом. Это нужно на случай, если в ней попадутся модели с одинаковым именем.
Пройдя по указанному пути, вы обнаружите подобные файлы:
checkpoint
model.yaml
saved_model_json.json
saved_model_weights.data-00000-of-00001
saved_model_weights.index
Модель всегда можно загрузить обратно с помощью функции load_runner, перед которой нужно поставить имя фреймворка:
model = bentoml.keras.load_runner("keras_conv2d_smaller:latest")
# Загрузка образца изображения из памяти
img = ...
print(model.run(img))
После загрузки модель можно использовать для прогнозирования с помощью метода run, который вызывает метод predict внутреннего объекта модели Keras.
Шаг 2. Создание сервиса
Все фрагменты кода в этом разделе взяты из репозитория проекта service.py.
Теперь необходимо только несколько строк кода для конвертации сохраненной модели в функционирующий API.
Сначала напишем функцию для создания объекта BentoML Service, который отвечает за всю логику API.
После загрузки модели с помощью функции load_runner передаем ее методу Service с произвольным именем.
def create_bento_service_keras(bento_name):
"""
Создание Bento Service для модели Keras.
"""
# Загрузка модели
keras_model = bentoml.keras.load_runner(bento_name)
# Создание Service
service = bentoml.Service(bento_name + "_service", runners=[keras_model])
return keras_model, service
model, service = create_bento_service_keras("conv2d_larger_dropout")
После этого создаем конечную точку API для обработки запросов POST путем определения функции, декорированной с помощью метода api объекта Service:
import numpy as np
import bentoml
from bentoml.io import Text, NumpyNdarray
from skimage.transform import resize
# Создание функции API
@service.api(input=Text(), output=NumpyNdarray())
def predict(image_str) -> np.ndarray:
"""
Прогнозирование популярности животного по изображению с помощью имеющегося Bento.
"""
# Конвертация изображения в массив numpy
image = np.fromstring(image_str, np.uint8)
image = resize(image, (224, 224, 3))
image = image / 255.0
result = model.run(image)
return result
Прежде чем переходить к телу функции, обсудим декоратор service.api, который имеет два необходимых параметра: input и output. Их необходимо определить, основываясь на данных, которые вы отправляете и получаете обратно от конечной точки.
После отправки запроса в виде изображения вышеуказанная конечная точка функции predict возвращает очки “милоты”. Вводные данные определены как Text(), потому что мы будем отправлять массив изображений NumPy в виде строки. На выходе должен быть NumpyNdarray(), так как при вызове model.run(image) возвращаемым типом данных будет массив Numpy.
Для конечной точки очень важно получить верный тип данных. На этой странице документации BentoML указаны типы данных, которые можно обрабатывать.
Что касается тела функции, то всю логику предварительной обработки следует записать в изображение до вызова model.run. Перед обучением размер изображений был изменен на (224, 224, 3). Они также были нормализованы путем разделения значения пикселей на 255. Эти шаги также выполнены внутри функции конечной точки.
Примечание. Если вы используете другие фреймворки для работы с табличными данными, например Sklearn, убедитесь, что все шаги предварительной обработки выполняются внутри конечной точки API. Для этого можно собрать все функции обработки и вызвать их внутри функции
predict. Таким образом не произойдет утечки или отправки некорректно отформатированных данных.
Чтобы запустить отладочный сервер для API, достаточно поместить весь код в один файл Python (обычно называется service.py) в корневом каталоге и выполнить следующую команду:
$ bentoml serve service.py:service --reload
Тэг --reload гарантирует, что локальный сервер заметит изменения в service.py и автоматически обновит логику.
На GIF-изображении видно, что сервер работает по адресу http://127.0.0.1:3000/ с простым интерфейсом:
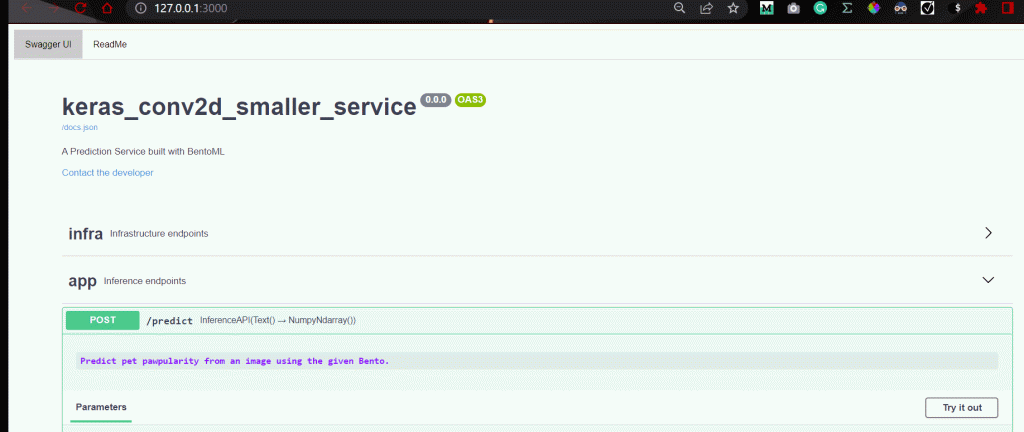
На этом этапе уже можно посылать запросы локальному серверу и получать прогнозы для изображений:
import requests
from skimage.io import imread
endpoint = "http://127.0.0.1:3000/predict"
# Загрузка образца изображения
img = imread("data/raw/train/0a0da090aa9f0342444a7df4dc250c66.jpg")
response = requests.post(endpoint, headers={"content-type": "text/plain"},
Обязательно установите правильные заголовки для типа данных и отправьте изображение, упакованное в функцию str. Примеры запросов с правильными заголовками для каждого типа данных можно найти на этой странице документации.
Посмотрим на текст ответа:
>>> print(response.text)
[35.49753189086914]
А вот изображение, которое мы отправляли:

Шаг 3. Построение Bento
Мы готовы к созданию первого Bento.
Bento — это архив, содержащий все необходимое для запуска сервисов и API в интернете, включая код, модели, информацию о зависимостях, а также конфигурации для настройки.
Его построение начинается с создания файла bentofile.yaml в каталоге того же уровня, что и файл service.py (желательно, чтобы оба находились в корневом каталоге проекта).
service: "service.py:service"
include:
- "service.py"
python:
packages:
- scikit_learn==1.0.2
- numpy==1.22.3
- tensorflow==2.8.0
- scikit_image==0.18.3
Первая строка YAML-файла должна содержать имя файла сервиса, за которым следует суффикс :service. Далее добавляются все файлы, необходимые для безошибочной работы service.py (данные, вспомогательные скрипты и т.д.). Здесь включен только файл сервиса, поскольку мы не использовали никаких дополнительных скриптов внутри него.
Затем в разделе python и packages указываем зависимости и их версии. Я всегда использую этот полезный пакет — pipreqs:
$ pip install pipreqs $ pipreqs .
Вызов pipreqs [path] создает файл requirements.txt, содержащий все импортированные пакеты и их версии по заданному пути, как показано ниже:
bentoml==1.0.0a7
catboost==0.26.1
dagshub==0.1.8
joblib==0.17.0
keras==2.8.0
lightgbm==2.3.1
matplotlib==3.3.1
mlflow==1.24.0
numpy==1.22.3
pandas==1.3.2
scikit_image==0.18.3
scikit_learn==1.0.2
seaborn==0.11.0
skimage==0.0
tensorflow==2.8.0
tqdm==4.50.0
xgboost==1.4.2
После отображения зависимостей остается только вызвать bentoml build:
$ bentoml build
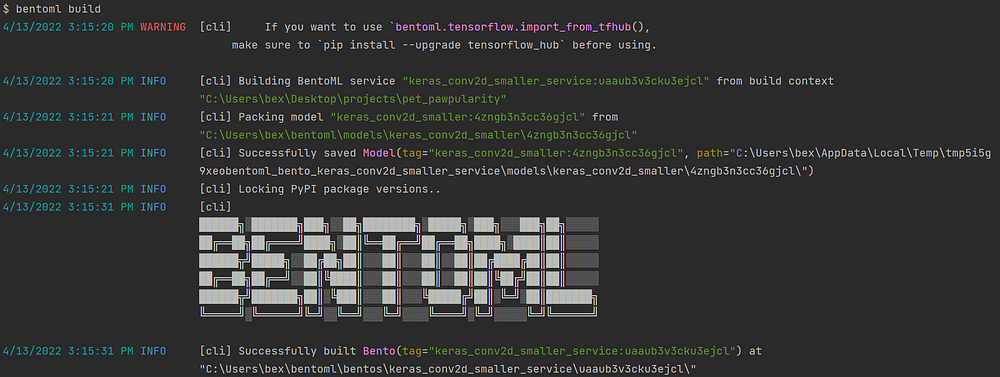
Чтобы увидеть список всех имеющихся Bentos, вызовите bentoml list:
$ bentoml list

Шаг 4. Развертывание в Heroku
Команда build сохраняет новый Bento в локальном хранилище со следующей древовидной структурой:
├───apis
│ openapi.yaml
├───env
│ ├───conda
│ ├───docker
│ │ Dockerfile
│ │ entrypoint.sh
│ │ init.sh
│ └───python
│ requirements.lock.txt
│ requirements.txt
├───models
│ └───keras_conv2d
│ │ latest
│ │
│ └───b52h7x5xpk2bejcl
│ checkpoint
│ model.yaml
│ saved_model_json.json
│ saved_model_weights.data-00000-of-00001
│ saved_model_weights.index
└───src
│ service.py
│ bento.yaml
│ README.md
Рассмотрим env/docker. Она содержит все необходимое для создания полнофункционального контейнера Docker, и мы будем использовать ее для развертывания API в сети.
Для этого существует множество вариантов, например Amazon EC и Google Cloud, но наиболее удобная платформа — это Heroku.
Heroku — популярная платформа, которая позволяет разработчикам на любом языке создавать и поддерживать облачные приложения. Создайте учетную запись и загрузите CLI, который можно использовать для создания и управления приложениями Heroku.
После установки выполните команду login для аутентификации терминальной сессии:
$ heroku login
Откроется вкладка в браузере, где можно войти в систему, используя свои учетные данные. Далее войдите в реестр контейнеров:
$ heroku container:login
Создадим приложение с именем pat-pawpularity:
$ heroku create pet-pawpularity
После этого приложение должно отобразиться на этом сайте.
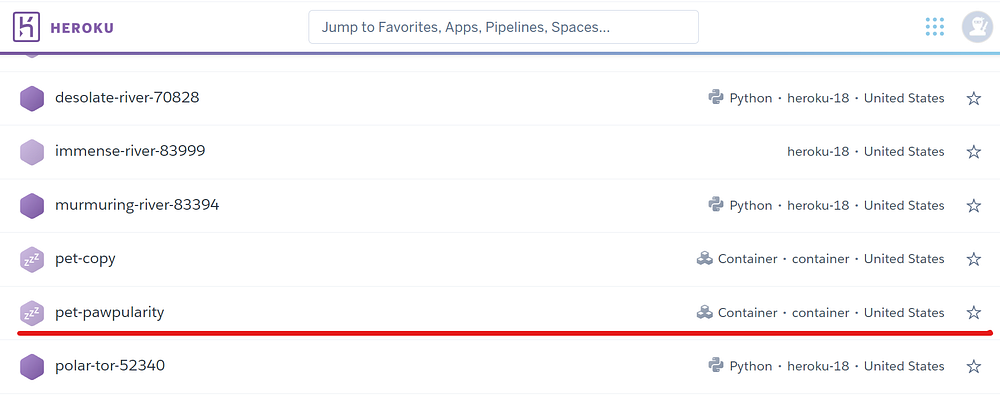
Теперь необходимо перенести Bento в созданное приложение и произвести развертывание онлайн. Для этого нужно перейти в каталог bento (который можно найти с помощью bentoml list) и войти в папку docker:
$ cd ~/bentoml/bentos/keras_conv2d_smaller_service/uaaub3v3cku3ejcl
$ cd env/docker
Далее выполняем команду:
$ heroku container:push web --app pet-pawpularity --context-path=../..
В зависимости от размера архива может потребоваться несколько минут для завершения команды.
Наконец, можно запустить приложение с помощью следующей команды:
$ heroku container:release web --app pet-pawpularity
Теперь на этом сайте можно увидеть API онлайн или перейти на страницу приложения на контрольной панели, чтобы открыть его:

Каждый может отправлять запросы к этому API. Попробуем:
import requests
from skimage.io import imread
endpoint = "https://pet-pawpularity.herokuapp.com/predict"
# Загрузка образца изображения
img = imread("data/raw/train/0a4f658ae77b7e4209e22b79fe1c28cb.jpg")
response = requests.post(
endpoint, headers={"content-type": "text/plain"}, data=str(img)
)
>>> print(response.text)
[27.414047241210938]
Шаг 5. Создание простого пользовательского интерфейса с помощью Streamlit
Все фрагменты кода в этом разделе взяты из репозитория проекта ui.py.
Теперь построим упрощенный интерфейс вокруг этого API. Начнем с написания простого заголовка секции для приложения с произвольным изображением на обложке:
import io
import numpy as np
import requests
import streamlit as st
API_ENDPOINT = "https://pet-pawpularity.herokuapp.com/predict"
# Создание заголовка страницы
st.title("Pet Pawpularity Prediction App")
st.markdown(
"### Прогнозирование популярности кошки или собаки с помощью МО",
unsafe_allow_html=True,
)
# Загрузка простого изображения для обложки
with open("data/app_image.jpg", "rb") as f:
st.image(f.read(), use_column_width=True)
st.text("Grab a picture of your pet or upload an image to get a Pawpularity score.")
Далее определим основную функциональность. Создадим функцию, которая выдает оценку “милоты” путем отправки запроса к API:
from PIL import Image
def predict(img):
"""
Функция, отправляющая запрос прогноза в API и возвращающая очки "милоты".
"""
# Конвертация изображения из байтов в массив NumPy
bytes_image = img.getvalue()
numpy_image_array = np.array(Image.open(io.BytesIO(bytes_image)))
# Отправка изображения в API
response = requests.post(
API_ENDPOINT,
headers={"content-type": "text/plain"},
data=str(numpy_image_array),
)
if response.status_code == 200:
return response.text
else:
raise Exception("Status: {}".format(response.status_code))
Изображения, загружаемые в приложения Streamlit, имеют формат BytesIO, поэтому сначала нужно конвертировать их в массив NumPy — это делается в строках 6–7. Остальной код довольно простой и не требует пояснений.
Далее создадим два компонента ввода изображения — для загрузки файлов и для ввода данных с веб-камеры:
def main():
img_file = st.file_uploader("Upload an image", type=["jpg", "png"])
if img_file is not None:
with st.spinner("Predicting..."):
prediction = float(predict(img_file).strip("[").strip("]"))
st.success(f"Your pet's cuteness score is {prediction:.3f}")
camera_input = st.camera_input("Or take a picture")
if camera_input is not None:
with st.spinner("Predicting..."):
prediction = float(predict(camera_input).strip("[").strip("]"))
st.success(f"Your pet's cuteness score is {prediction:.3f}")
if __name__ == "__main__":
main()
При использовании оба компонента отображают простую анимацию в режиме ожидания, а затем возвращают очки “милоты”.
После переноса всех этих изменений на GitHub, приложение можно развернуть онлайн, перейдя по ссылке.
Вот ссылка на развернутое приложение.
Заключение
Вы создали полноценное приложение для работы с изображениями с интерфейсом, доступным для обычных пользователей, и собственным API для друзей-программистов и товарищей по команде. Теперь у вас есть надежный способ делиться моделями, не беспокоясь о настройке среды и коде.
Читайте также:
- Как быстро создать и развернуть веб-приложение на Python
- Простое развёртывание графовой базы данных: JanusGraph
- Автоматический анализ текста с использованием Streamlit
Читайте нас в Telegram, VK и Дзен
Перевод статьи Bex T.: The Easiest Way to Deploy Your Machine Learning Models in 2022: Streamlit + BentoML + DagsHub

")



