
Введение
Одна из самых распространенных задач электронной коммерции — создание хорошо работающей модели рекомендаций и категоризации товаров. Рекомендательная система товаров используется для предоставления пользователям аналогичных предложений. Она позволяет увеличить общее время пребывания на платформе и сумму, потраченную в расчете на одного пользователя.
Кроме того, на платформах электронной коммерции, особенно тех, где большая часть контента создается пользователями (например, на сайтах объявлений), необходима модель категоризации продуктов. Она используется для “отлова” неправильно категорированных продуктов и размещения их по соответствующим категориям. Это способствует улучшению общего пользовательского опыта на платформе.
Данная статья состоит из двух основных частей. В первой поговорим о том, как построить систему рекомендаций товаров для электронной коммерции и провести категоризацию товаров (примеры кода помогут продемонстрировать эти процессы). Во второй обсудим, как реализовать этот проект в несколько шагов с помощью MLOps-платформы под названием Layer.
Методология в двух словах
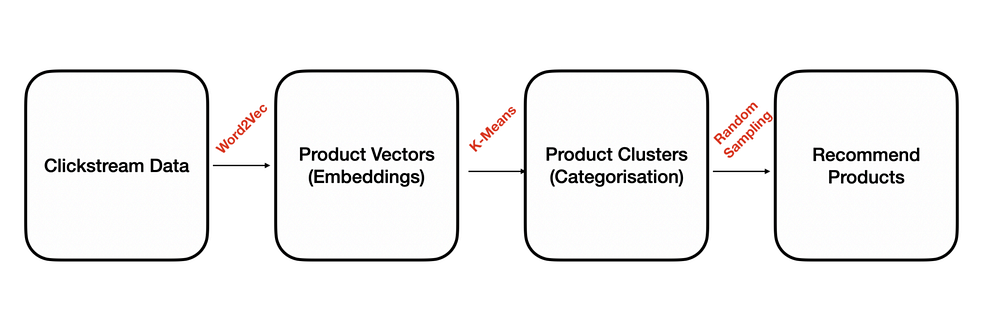
Вероятно, большинство платформ электронной коммерции собирают данные о посещениях пользователей. Эта информация собирается в простую таблицу, состоящую из 3 столбцов: session_id, product_id и timestamp. Данных из этой таблицы будет достаточно для создания описанной здесь модели рекомендации товаров.
В данном руководстве будет использован публичный набор данных Kaggle (CC0: Public Domain), который представляет собой сведения о посещениях онлайн-магазина.
В основу этой методологии положен алгоритм Word2Vec, служащий для встраивания продуктов. Word2Vec используется в основном в NLP и при работе с текстами. По аналогии World2Vec используется и в контексте электронной коммерции. Продукт будет рассматриваться как одно слово, а последовательность просмотров продукта (сессий) — как предложение. Выходными данными алгоритма Word2Vec будут числовые репрезентативные векторы продуктов.
На следующем этапе эти векторы продуктов подаются на вход алгоритма K-Means для создания произвольного количества кластеров продуктов. Эти кластеры представляют собой группы (категоризацию) похожих продуктов.
На последнем этапе создадим несколько рекомендаций по продуктам, выбирая их случайным образом из соответствующих кластеров.
Оглавление
Часть I. Пример из практики
- Шаг I. Загрузка csv-файла в датафрейм Pandas
- Шаг II. Преобразование данных о посещениях в последовательности просмотров продуктов
- Шаг III. Создание векторов продуктов (встраиваний) с помощью алгоритма Word2Vec
- Шаг IV. Подгонка модели K-Means к векторам продуктов (встраиваниям).
- Шаг V. Сохранение кластеров в виде датафрейма
- Шаг VI. Получение рекомендаций по аналогичным продуктам для данного продукта
Часть II. MLOPS
- Установка и вход в систему Layer
- Декоратор набора данных Layer
- Декоратор моделей Layer
- Режимы среды выполнения Layer
- Полный ноутбук, интегрированный с Layer
Часть I. Пример из практики
Шаг I. Загрузка csv-файла в датафрейм Pandas
Определите простую функцию с именем raw_session_based_clickstream_data, которая считывает csv-файл из его местоположения и возвращает датафрейм Pandas.
import pandas as pd
def raw_session_based_clickstream_data():
data = pd.read_csv("examples/recommendation-system/e-shop clothing 2008.csv",delimiter = ';')
return data
raw_clickstream = raw_session_based_clickstream_data() raw_clickstream.head(5)

Шаг II. Преобразование данных о посещениях в последовательности просмотров продуктов
Определите функцию generate_sequential_products, которая берет датафрейм raw_clickstream из вывода предыдущей функции. Затем примените такие методы очистки данных, как переименование столбцов и удаление сессий, в которых есть только один просмотр продукта. После этого она группирует данные по столбцу session_id и создает списки продуктов для каждой сессии.
Важно использовать столбец order при группировке просмотров продуктов по сессиям, поскольку последовательность просмотров должна быть в хронологическом порядке. Если в данных есть только временные метки просмотров продуктов, следует сначала создать отдельный столбец order, используя столбец timestamp (временная метка).
Существует также вспомогательная функция remove_consec_duplicates, которая удаляет все следующие друг за другом дубликаты продуктов из последовательностей просмотров продуктов. Это особенно важно, поскольку в следующей части будет использоваться алгоритм Word2Vec для генерирования встраивания продуктов. Вполне вероятно, что в данных будет много таких дублированных просмотров, которые могут исказить алгоритм.
# удаление последовательных дубликатов из списка
def remove_consec_duplicates(raw_lst):
previous_value = None
new_lst = []
for elem in raw_lst:
if elem != previous_value:
new_lst.append(elem)
previous_value = elem
return new_lst
def generate_sequential_products():
# Переименование столбцов
data = raw_clickstream.rename(columns={"session ID": "session_id", "page 2 (clothing model)": "product_id"})
# Удаление сессий, в которых просматривается только один продукт
data = data.groupby("session_id").filter(lambda x: len(x) > 1)
# Группировка последовательностей просмотров продукта по порядку по идентификатору сессии
data = data.sort_values("order").groupby("session_id")["product_id"].apply(list)
# Удаление последовательных дублирующихся просмотров продуктов из последовательностей, созданных на предыдущем этапе
data = data.apply(remove_consec_duplicates)
# Преобразование серии в датафрейм
data = data.to_frame().reset_index().rename(columns={"product_id": "chronological_product_sequence"})
return data
session_based_product_sequences = generate_sequential_products() session_based_product_sequences.head(5)

Шаг III. Генерирование векторов продуктов (встраиваний) с помощью алгоритма Word2Vec
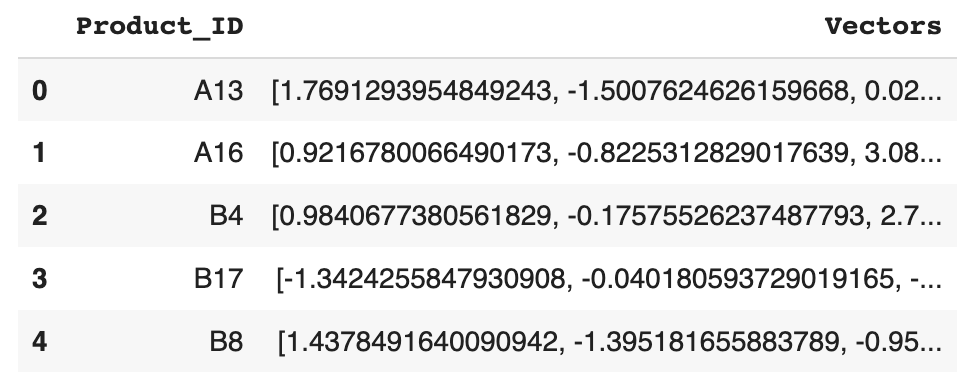
Определите функцию create_product_embeddings, которая берет датафрейм session_based_product_sequences из выхода предыдущей функции и обучает модель Word2vec библиотеки Gensim, задавая размер окна 5 и размер встраивания 10. Эта функция возвращает набор данных с двумя столбцами, где первый столбец — идентификатор продукта, а второй — его репрезентативный 10-мерный числовой вектор, полученный из модели Word2Vec.
def create_product_embeddings():
import gensim
from gensim.models import Word2Vec
# Создание модели Gensim CBOW
session_product_sequences = session_based_product_sequences['chronological_product_sequence'].apply(list)
word2vec_model = gensim.models.Word2Vec(session_product_sequences, min_count = 1, size = 10, window = 5)
# numpy.ndarrays векторов продукта
product_vectors = word2vec_model.wv.vectors
productID_list = word2vec_model.wv.vocab.keys()
vector_list = word2vec_model.wv.vectors.tolist()
data_tuples = list(zip(productID_list,vector_list))
product_ids_and_vectors = pd.DataFrame(data_tuples, columns=['Product_ID','Vectors'])
return product_ids_and_vectors
product_ids_and_vectors = create_product_embeddings() product_ids_and_vectors.head(5)
Шаг IV. Подгонка модели K-Means под векторы продуктов (встраиваний)
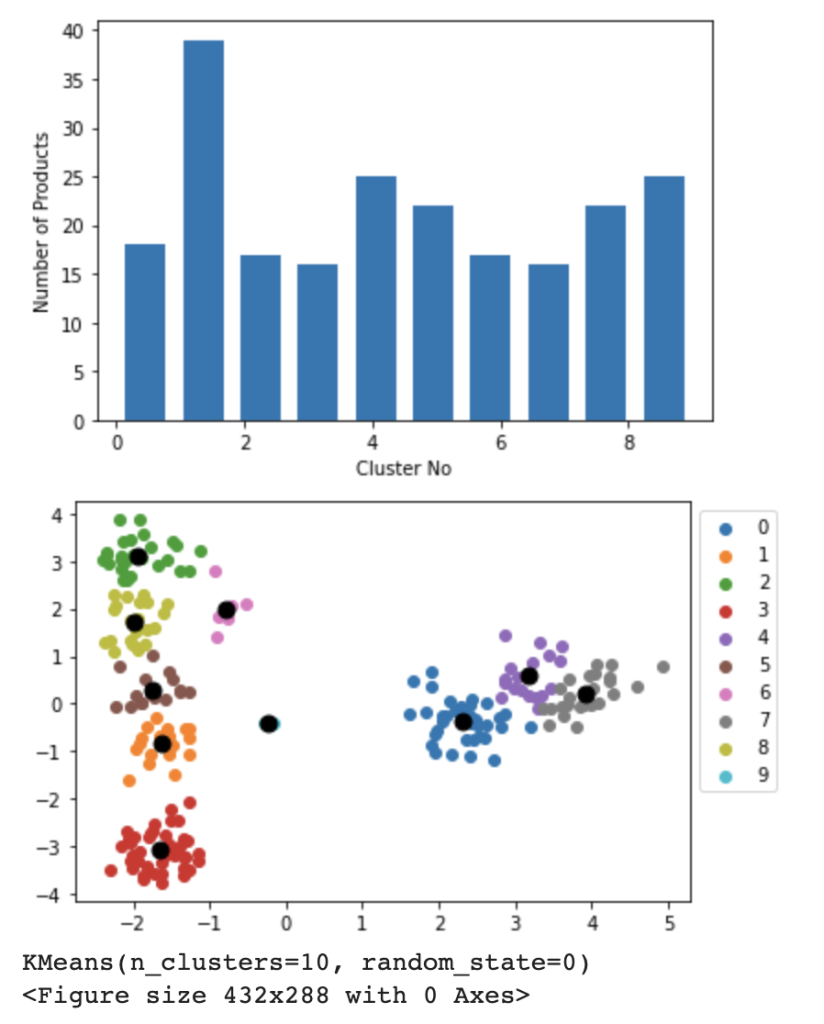
Определите функцию fit_kmeans, которая обучает модель k-means, используя датафрейм векторов продуктов product_id_and_vectors, созданный на предыдущем шаге. В приведенном ниже фрагменте кода было задано число кластеров, равное 10. Однако вы можете выбрать количество кластеров в зависимости от общего количества категорий, предусмотренных на вашей платформе.
Мы также создали два различных графа в результате работы двух других вспомогательных функций: plot_cluster_distribution и plot_cluster_scatter. Первая создает визуализацию, которая показывает распределение количества членов по кластерам в виде гистограммы, а вторая — диаграмму рассеяния, чтобы показать, как кластеры формируются в двумерном пространстве, и отметить их центроиды черными точками.
def fit_kmeans():
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
# Получение векторов продуктов из Word2Vec
array_product_vectors = np.array(product_ids_and_vectors["Vectors"].values.tolist())
# Подгонка алгоритма K-Means к этим встраиваниям
kmeans_model = KMeans(n_clusters=10, random_state=0).fit(array_product_vectors)
# График распределения кластеров
plot_cluster_distribution(kmeans_model)
# Диаграмма рассеяния кластеров
plot_cluster_scatter(array_product_vectors)
return kmeans_model
def plot_cluster_distribution(kmeans_model):
import matplotlib.pyplot as plt
plt.hist(kmeans_model.labels_, rwidth=0.7)
plt.ylabel("Number of Products")
plt.xlabel("Cluster No")
plt.show()
# Удаление всех графиков и рисунков из памяти
plt.figure().clear()
plt.close()
plt.cla()
plt.clf()
def plot_cluster_scatter(product_vectors):
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import numpy as np
pca = PCA(n_components=2)
two_dimensions_vectors = pca.fit_transform(product_vectors)
kmeans_model = KMeans(n_clusters=10, random_state=0).fit(two_dimensions_vectors)
label = kmeans_model.fit_predict(two_dimensions_vectors)
# Получение центроидов
centroids = kmeans_model.cluster_centers_
u_labels = np.unique(kmeans_model.labels_)
# Построение графиков результатов
for i in u_labels:
plt.scatter(two_dimensions_vectors[label == i , 0] , two_dimensions_vectors[label == i , 1] , label = i)
plt.scatter(centroids[:,0] , centroids[:,1] , s = 80, color = 'k')
plt.legend(bbox_to_anchor =(1, 1))
plt.show()
# Удаление всех графиков и рисунков из памяти
plt.figure().clear()
plt.close()
plt.cla()
model = fit_kmeans()
Шаг V. Сохранение кластеров в виде датафрейма
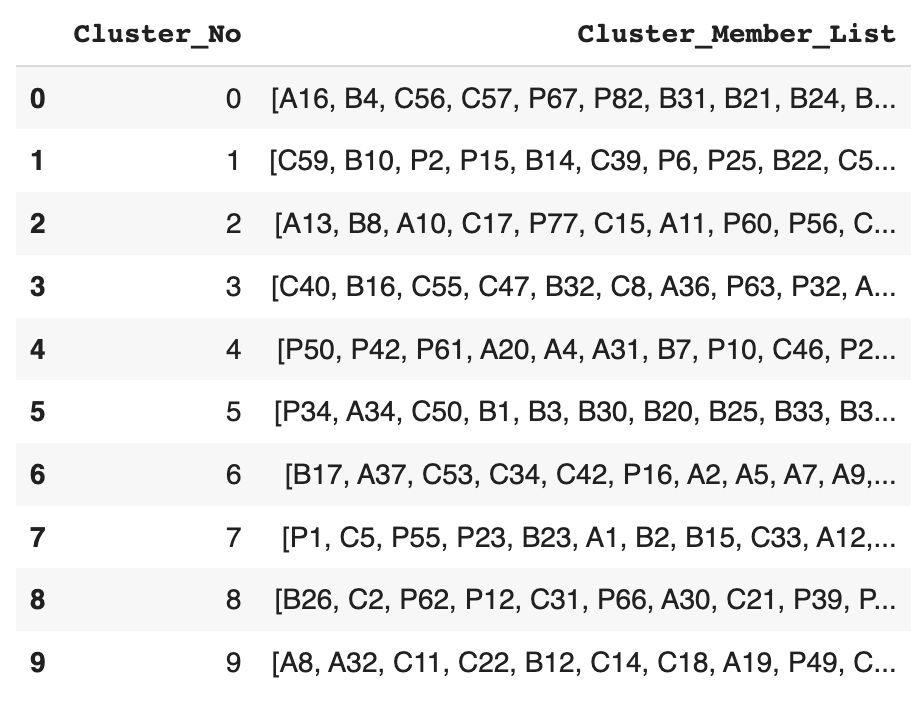
Определите функцию save_final_product_clusters, которая создает датафрейм, хранящий список членов каждого кластера. Эта функция использует модель (model) из предыдущей функции и датафрейм product_ids_and_vectors из вывода функции create_product_embeddings. Поскольку ранее было задано число кластеров, равное 10, в наборе данных будет всего 10 строк. Членом кластера в данном случае является идентификатор продукта.
def save_final_product_clusters():
import numpy as np
array_product_vectors = np.array(product_ids_and_vectors["Vectors"].values.tolist())
assigned_cluster_no = model.fit_predict(array_product_vectors).tolist()
product_ids_and_vectors["Cluster_No"] = assigned_cluster_no
cluster_members_df = product_ids_and_vectors[["Product_ID","Cluster_No"]].groupby("Cluster_No")['Product_ID'].apply(list).to_frame().reset_index().rename(columns={'Product_ID': 'Cluster_Member_List'})
return cluster_members_df
cluster_members_df = save_final_product_clusters() cluster_members_df.head(10)
Шаг VI. Получение рекомендаций аналогичных продуктов для заданного продукта
Теперь напишем блок кода для получения рекомендаций по аналогичным продуктам для конкретного продукта с идентификатором A13.
Для этого сначала нужно получить репрезентативный числовой вектор этого продукта из датафрейма product_ids_and_vectors и передать его модели, чтобы она получила номер кластера. Затем получим список членов кластера, к которому принадлежит продукт A13. На последнем этапе случайным образом выберем 5 аналогичных продуктов из этого кластера.
import numpy as np
# ID продукта для генерации рекомендаций. Вы можете попробовать различные ID продукта, например A16, C17, P12 и т. д.
product_id = "A13"
# Получение массива векторов (встраиваний) заданного продукта
vector_array = np.array(product_ids_and_vectors[product_ids_and_vectors["Product_ID"]==product_id]["Vectors"].tolist())
# Получение номера кластера для данного продукта, присвоенного моделью
cluster_no = model.predict(vector_array)[0]
# Получение списка членов кластера, к которому относится данный продукт
cluster_members_list = cluster_members_df[cluster_members_df['Cluster_No']==cluster_no]['Cluster_Member_List'].iloc[0]
# Случайный выбор 5 рекомендаций по продуктам из членов кластера, за исключением данного продукта
from random import sample
cluster_members_list.remove(product_id)
five_product_recommendations = sample(cluster_members_list, 5)
print("5 Similar Product Recommendations for {}: ".format(product_id),five_product_recommendations)
Выходные данные будут выглядеть следующим образом:
5 Similar Product Recommendations for A13: ['C17', 'P60', 'C44', 'P56', 'A6']
Часть II. MLOPS
Layer — это платформа для совместной работы над МО-проектами, которая поставляется с предопределенными декораторами функций. Все, что нужно сделать, — обернуть функции Python одним из декораторов Layer (dataset и model) в зависимости от типа возвращаемых данных функции.
Например, если функция возвращает набор данных, и нужно, чтобы Layer отслеживал его, оберните ее декоратором dataset. Layer автоматически запустит версионирование набора данных. Описанная процедура аналогична и для моделей. Если функция возвращает МО-модель, оберните ее декоратором model, и Layer начнет автоматически выполнять версионирование модели при каждом запуске одного и того же ноутбука.
Установка и вход в Layer
Начните с установки и входа в Layer с помощью нескольких строк кода. Затем инициализируйте проект на Layer с помощью команды layer.init(имя_вашего_проекта).
!pip install layer
import layer
from layer.decorators import dataset, model
layer.login()
layer.init("Ecommerce_Recommendation_System")
Декоратор набора данных Layer
Оберните первую функцию raw_session_based_clickstream_data декоратором набора данных Layer @dataset(dataset_name)] и дайте набору данных Layer имя raw_session_based_clickstream_data. Можно также логировать другие типы данных вместе с набором данных. Например, его описание, используя layer.log(), как показано во фрагменте кода ниже.
@dataset("raw_session_based_clickstream_data")
def raw_session_based_clickstream_data():
data = pd.read_csv("examples/recommendation-system/e-shop clothing 2008.csv",delimiter = ';')
layer.log({"Dataset Description": "Raw clickstream data of an e-commerce clothing company"})
return data
С этого момента Layer будет отслеживать набор данных, возвращаемый функцией, логировать другие типы данных вместе с набором данных и автоматически версионировать его. Это означает, что каждый раз при запуске этой функции будет создаваться новая версия набора данных. Таким образом, Layer позволит увидеть весь путь одного и того же набора данных в веб-интерфейсе Layer, как показано на рисунке ниже.
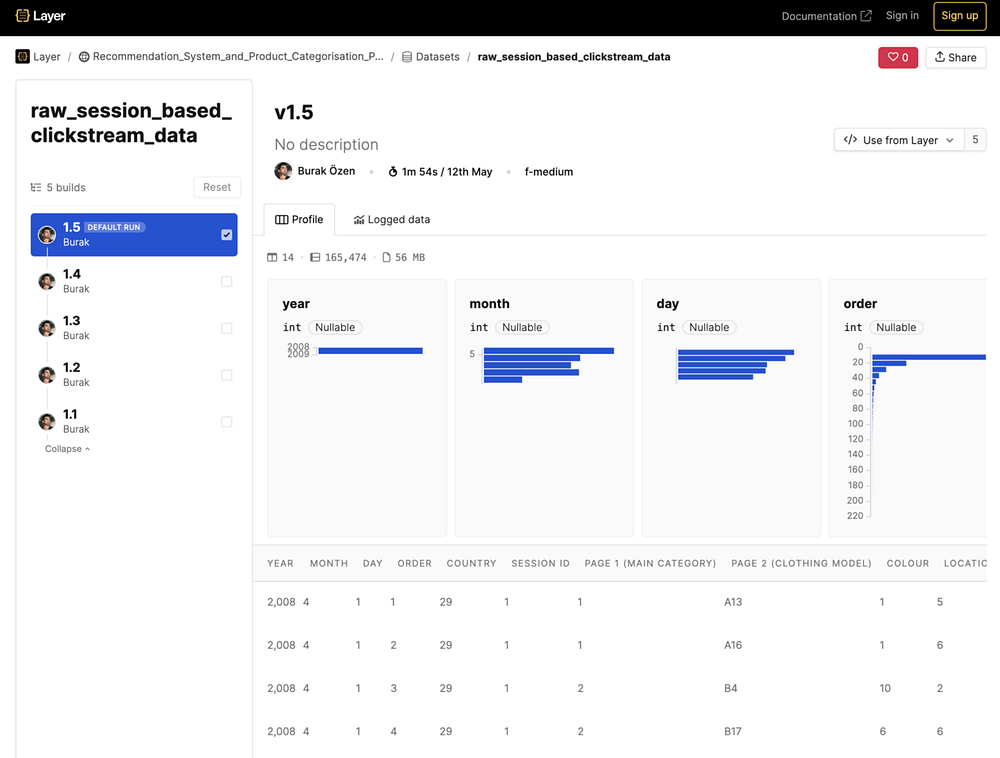
Перед вами список версий набора данных и информация о профиле данных. Остальные данные, залогированные вместе с набором данных, можно увидеть на вкладке Logged data.
Декоратор модели Layer
Теперь проделаем тот же процесс для моделей. На этот раз нужно обернуть функцию модели fit_kmeans() декоратором модели Layer @model(имя_модели)] и дать модели Layer имя clustering_model. Можно также логировать другие типы данных вместе с моделью. Например, некоторые графы, используя layer.log(), как показано во фрагменте кода ниже.
Единственная разница между блоком кода из предыдущего раздела и приведенным ниже — это 3 дополнительные строки, специфичные для Layer.
@model("clustering_model")
def fit_kmeans():
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
# Получение векторов продуктов из Word2Vec
array_product_vectors = np.array(product_ids_and_vectors["Vectors"].values.tolist())
# Подгонка алгоритма K-Means к этим встраиваниям
kmeans_model = KMeans(n_clusters=10, random_state=0).fit(array_product_vectors)
# График распределения кластеров
plot_cluster_distribution(kmeans_model)
# Диаграмма рассеяния кластеров
plot_cluster_scatter(array_product_vectors)
return kmeans_model
def plot_cluster_distribution(kmeans_model):
import matplotlib.pyplot as plt
plt.hist(kmeans_model.labels_, rwidth=0.7)
plt.ylabel("Number of Products")
plt.xlabel("Cluster No")
# Layer логирует график (рисунок)
fig = plt.gcf()
layer.log({"Clusters Formation Scatter Plot": fig})
# Удаление всех графиков и рисунков из памяти
plt.figure().clear()
plt.close()
plt.cla()
plt.clf()
def plot_cluster_scatter(product_vectors):
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import numpy as np
pca = PCA(n_components=2)
two_dimensions_vectors = pca.fit_transform(product_vectors)
kmeans_model = KMeans(n_clusters=10, random_state=0).fit(two_dimensions_vectors)
label = kmeans_model.fit_predict(two_dimensions_vectors)
# Получение центроидов
centroids = kmeans_model.cluster_centers_
u_labels = np.unique(kmeans_model.labels_)
# Построение результатов в графическом виде
for i in u_labels:
plt.scatter(two_dimensions_vectors[label == i , 0] , two_dimensions_vectors[label == i , 1] , label = i)
plt.scatter(centroids[:,0] , centroids[:,1] , s = 80, color = 'k')
plt.legend(bbox_to_anchor =(1, 1))
# Layer логирует график (рисунок)
fig = plt.gcf()
layer.log({"Clusters Formation Scatter Plot": fig})
# Удаление всех графиков и рисунков из памяти
plt.figure().clear()
plt.close()
plt.cla()
plt.clf()
С этого момента Layer будет отслеживать и версионировать модель наряду с логированием всех остальных данных. Это позволит сравнивать различные версии модели, возвращаться к любой предыдущей версии в случае сбоя и постоянно отслеживать производительность модели. Вот скриншот, сделанный со страницы модели в интерфейсе Layer.
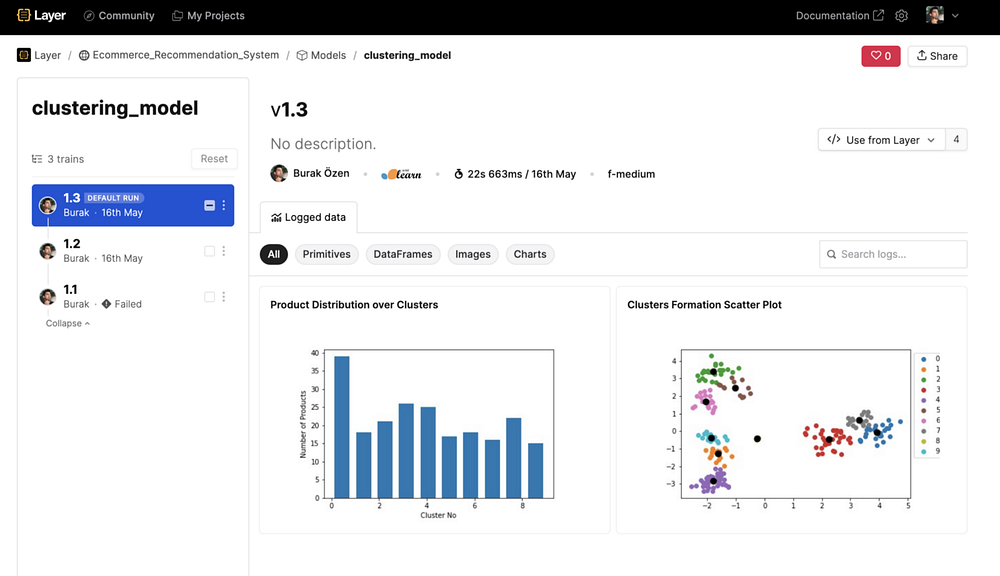
Режимы среды выполнения Layer
В Layer созданы 2 режима среды выполнения: локальный и удаленный.
Локальный режим. В локальном режиме можно вызывать функции в любом порядке, а код будет выполняться на локальном компьютере, используя ваши вычислительные мощности. В этом режиме все данные, такие как наборы данных и модели, созданные в процессе работы, по-прежнему записываются на удаленный хост Layer.
# ЛОКАЛЬНЫЙ РЕЖИМ LAYER raw_session_based_clickstream_data() generate_sequential_products() create_product_embeddings() fit_kmeans() save_final_product_clusters()
Удаленный режим. В удаленном режиме нужно поместить все имена функций Python в layer.run(). Это позволит удаленно запустить код на Layer Infra, используя ресурсы Layer. Таким образом, можно использовать огромную вычислительную мощность машин и GPU Layer для запуска проектов глубокого обучения.
# УДАЛЕННЫЙ РЕЖИМ LAYER
layer.run([raw_session_based_clickstream_data,
generate_sequential_products,
create_product_embeddings,
fit_kmeans,
save_final_product_clusters],debug=True)
При использовании Layer в удаленном режиме рекомендуется показывать зависимости между наборами данных или моделями в сигнатурах декораторов. Так, в приведенном ниже примере кода модель clustering_model зависит от набора данных product_ids_and_vectors, а набор данных final_product_clusters зависит от набора данных product_ids_and_vectors и модели clustering_model.
# ДЕКОРАТОР МОДЕЛИ С ЗАВИСИМОСТЯМИ
@model("clustering_model",dependencies=[Dataset("product_ids_and_vectors")])
# ДЕКОРАТОР ДАТАСЕТА С ЗАВИСИМОСТЯМИ
@dataset("final_product_clusters", dependencies=[Model("clustering_model"), Dataset("product_ids_and_vectors")])
Это лишь краткое введение в Layer. Дополнительную информацию о Layer SDK и других возможностях можно найти здесь.
Полный ноутбук, интегрированный с Layer
Соберем все блоки кода в единый ноутбук Python. Здесь представлена полная версия ноутбука системы рекомендаций товаров для электронной коммерции с интеграцией Layer.
А по этой ссылке можно увидеть, как этот проект выглядит на Layer.
Читайте также:
- Добыча данных: анализ рыночной корзины с помощью алгоритма Apriori
- Наука о данных в “царстве” Web3
- 25 прикольных вопросов для собеседования по машинному обучению
Читайте нас в Telegram, VK и Дзен
Перевод статьи Burak Özen: MLOps: How to Operationalise E-Commerce Product Recommendation System





