
Когда речь заходит о веб-сайтах, кэширование становится ключевым фактором всех действий по оптимизации. Простое и эффективное решение большинства подобных проблем состоит в том, чтобы сохранить ранее вычисленные данные и избежать повторных вычислений.
В случае с веб-приложениями целесообразно кэшировать весь ответ сервера. Тогда каждый раз, когда пользователь делает один и тот же запрос, сервер предлагает уже готовый результат.
Этот подход прекрасно работает для простых страниц с небольшим объемом динамической информации. А теперь представьте информационную панель с множеством независимых друг от друга виджетов. Как убедиться, что при каждом запросе одна и та же информация остается актуальной для всех из них ? Никак.
Кэширование SQL-запросов
В поисках выхода мы не собираемся отказываться от кэширования — просто сосредоточимся на кэшировании нужных данных. Нет смысла использовать для веб-страницы единый кэш, полностью состоящий из динамических данных. Зато стоит попробовать сохранять отдельные результаты и параллельно их кэшировать.
В первом варианте при каждом изменении одного из виджетов возникает необходимость аннулировать кэш, который отныне становится недействительным, а следовательно, и бесполезным.
А вот второй подразумевает сохранение в кэше редко меняющихся виджетов при параллельном обновлении часто меняющихся в каждый момент их изменения.
Кэширование запроса с помощью Redis
Первый признак хорошего кэша — быстрый ввод/вывод. В этом случае он не тормозит производительность, а наоборот помогает решать выявленные проблемы.
Второй признак — способность кэша сразу аннулировать данные, как только они становятся недействительными. Такого результата сложно добиться с помощью кода. Ведь подразумевается, что вы должны знать, в какой момент тот или иной набор данных перестает быть достоверным. И при каждом его запросе логика должна проверять, действителен ли он или нет.
Однако хранилище Redis решает все эти проблемы и предоставляет множество дополнительных встроенных функциональностей. По этой причине Redis — одно из ключевых решений для кэширования, применяемых в индустрии.
- Redis отличается скоростью. Это размещаемое в памяти хранилище обрабатывает операции чтения и записи в среднем менее чем за 10 мс. Такая способность объясняется отсутствием необходимости работать с дисковым вводом\выводом, который увеличивает задержки.
- Redis автоматически аннулирует кэш. Функциональность TTL в Redis позволяет переустанавливать дату истечения срока действия для всех кэшируемых записей. Это значит, что пока кэш нужен или пока вы его обновляете, он будет доступен. Если он обновляться не будет или будет использоваться редко, память освобождается, и кэш создается заново.
- Redis сообщает о том, когда кэш становится недействительным. Это позволяет заблаговременно обновить его, чтобы продлить использование.
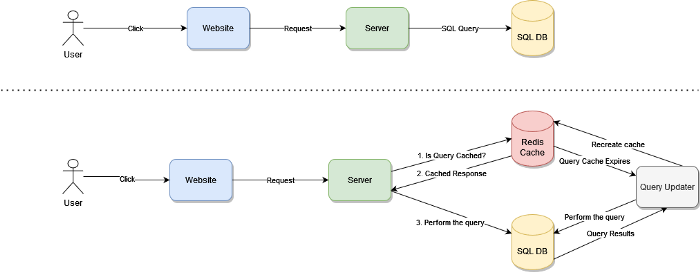
Рассмотрим представленную выше схему. В верхней части показан пример стандартного веб-приложения, применяемого обычным пользователем. Одним кликом он делает запрос, который преобразуется в SQL-запрос. В данном случае выполняется один запрос. А представьте, что произойдет, если их число возрастет до двух или даже 10.
В нижней части тот же самый пользователь работает с приложением, которое фоном реализует кэширование запроса. Мы видим более сложную архитектуру, но если присмотреться, то поток очень простой:
- Перед выполнением запроса проверяем, кэширован ли он.
- Если да, используем эти результаты.
- Если нет, запрашиваем базу данных.
В результате данной логики мы можем потенциально хранить результаты в кэше при переходе на 3-й этап.
Если кэш существует, но срок его действия истекает, можно его обновить, не дожидаясь следующего выполнения запроса пользователем. Для этого применяются уведомления пространства ключей в сочетании с параллельным процессом, предназначенным только для данной цели.
Благодаря всему вышеперечисленному Redis считается отличным инструментом для кэширования. Он поддерживает разные типы данных, что значительно упрощает хранение в нем результатов. Если кэшированию подлежат простые данные, например отдельные записи, то в Redis они хранятся как строка внутри ключа. Однако в случае с более усложненными записями лучше воспользоваться хешами Redis для хранения в них сложных структур данных.
Как кэшировать результаты SQL-запроса в Redis?
Определившись со стратегией для кэширования результатов запроса в Redis, стоит уделить внимание двум главным моментам:
#1 Правильное наименование ключей
Это важно, поскольку они будут работать как идентификаторы кэшированных данных внутри гигантской хеш-таблицы, размещенной в памяти. Из этого следует, что коллизии имен не допустимы. Как вариант, можно выполнить операцию хеширования для актуальной строки запроса. Если запрос каждый раз генерируется автоматически, то хеш-код с большой вероятностью будет иметь для одинакового запроса правильное значение вне зависимости от того, какой клиент его отправил. Хотя, если строка может изменяться, то вам скорее понадобится парсить ее и генерировать хеш на основе полученных данных. Если параметры в условии WHERE располагаются в другом порядке, то после извлечения их можно разместить по вашему усмотрению.
Приведем пример запроса:
SELECT name, address, birthdate FROM Users where birthdate > '2012-02-23';Генерируем хеш MD5: b88b231e77449e3cd97f71b07695b8dd. Затем создаем ключ с именем query-cache:b88b231e77449e3cd97f71b07695b8dd и задействуем его для хранения данных. Например, результаты могут храниться внутри ключа в течение 24 часов TTL. Это значит, что если вы не делаете чего-либо другого, то срок действия кэша истекает через 24 часа. Как только это происходит, вы решаете, заполнять ли его автоматически самому или позволить логике кэшировать его в следующий раз, когда потребуется запрос.
Фактически вы также можете обновлять кэш из другого процесса при каждом добавлении нового пользователя в таблицу. Обновляя существующий ключ, вы сбрасываете TTL, что позволяет работать с ним, не беспокоясь об устаревших данных.
#2 Принцип хранения данных
Простые записи можно сериализовать и хранить в ключе кэша в виде строки. В конце концов информация не будет использоваться и запрашиваться внутри Redis, поэтому формат хранения не имеет особого значения. А главное преимущество состоит в том, что вы получаете результаты намного быстрее, чем при SQL-запросе.
Строку можно разобрать и преобразовать в любой тип данных, необходимый для кода.
Сохраним сериализованные данные в ключ Redis и установим TTL на 24 часа:
SET query-cache:b88b231e77449e3cd97f71b07695b8dd 'a:1:{s:7:"results";a:2:{i:0;a:3:{s:4:"name";s:15:"Fernando Doglio";s:9:"birthdate";s:10:"2014-10-24";s:7:"address";s:13:"Madrid, Spain";}i:1;a:3:{s:4:"name";s:8:"John Doe";s:9:"birthdate";s:10:"2020-10-24";s:7:"address";s:13:"New York, USA";}}}' EX 86400Кэширование запроса к базе данных в архитектуре
Чтобы реализовать данный способ кэширования в существующей архитектуре необходимо абстрагировать доступ к базе данных в отдельный слой. Это может быть отдельный класс, модуль или даже полноценный микросервис. Суть в том, чтобы избежать применения драйверов базы данных непосредственно из бизнес-логики. Таким образом вы сможете добавлять код для каждого запроса, который будет:
- Перехватывать запрос и вычислять для него хеш MD5.
- Запрашивать Redis в поисках существующего кэша.
- В случае совпадения использовать эти результаты, проводить парсинг и возвращать их в логику.
- При отсутствии совпадения непосредственно запрашивать базу данных, кэшировать результаты с установленным на 24 часа TTL и возвращать записи в логику.
Это все, что нужно для реализации обозначенного способа кэширования SQL-запроса с помощью Redis.
Реализация кэширования SQL-запроса в Windows
Как мы уже выяснили, Redis — это отличный инструмент для надежного и эффективного кэширования. Однако могут возникнуть сложности с обеспечением его корректной работы в Windows. В связи с этим рекомендую воспользоваться хранилищем данных Memurai, совместимым с Redis и нативным для Windows. Этот инструмент ни в чем не уступает оригиналу, а в некоторых случаях даже превосходит его в скорости.
Memurai поможет создать собственное решение. И поскольку оно полностью совместимо с API Redis, то вы сможете задействовать в работу любую поддерживаемую им библиотеку на любом языке программирования.
Читайте также:
- Сравниваем эффективность Redis, Kafka и RabbitMQ
- Введение в потоки Redis
- Как сделать сайт в 25 раз быстрее с помощью нескольких строк кода
Читайте нас в Telegram, VK и Дзен
Перевод статьи Fernando Doglio: Using In-Memory Databases in Windows — SQL Query Caching





