
Регулярные выражения представляют собой последовательность знаков и символов, которые в глазах неподготовленного человека выглядят также устрашающе, как и уличные вывески на иностранном языке. С этой точки зрения, нельзя не заметить иронию в самом термине “регулярные выражения”.
Любой ценой я избегал с ними встречи, и эта игра в прятки затянулась намного дольше, чем можно себе представить. Но однажды я решил, что пора с ними подружиться.
Регулярные выражения — это чрезвычайно важная часть деятельности программиста и полезный инструмент в рабочем арсенале. Они избавляют от необходимости часами сидеть за написанием неоправданно длинного кода.
Вот почему я погрузился в волшебный мир регулярных выражений в ожидании сложных испытаний, но стоило лишь разобраться с базовыми принципами, как дальнейший путь по дороге из желтого кирпича стал вполне приемлемым.
Работа с регулярными выражениями напоминает изучение иностранного языка: как только приходит понимание слов и грамматики — начинаешь без труда составлять предложения.
В самом общем смысле регулярные выражения — это последовательности символов для поиска соответствий шаблону. Они являются экземплярами регулярного языка и широко применяются для парсинга текста или валидации входных строк.
Представьте лист картона, в котором вырезаны определенные фигуры. И только фигуры, точь-в-точь соответствующие вырезам, смогут через них пройти. В данном случае лист картона аналогичен строке регулярного выражения.
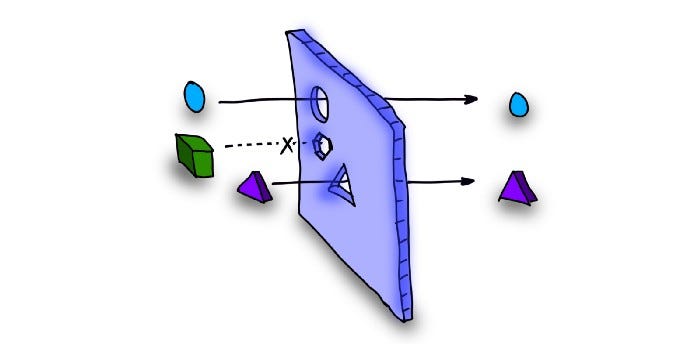
Как выглядел бы поисковый шаблон с регулярным выражением для рассмотренного примера?
Regex: circle|triangle|hexagonИнструкция ввода задает три входящие фигуры: круг, треугольник и прямоугольник.
Движок регулярного выражения обнаружит совпадения только слов circle и triangle. На сервисе Regex101 вы можете сами в этом убедиться.
Все просто!
Сами по себе регулярные выражения являются неотъемлемой частью регулярного языка. Однако их поддерживают большинство актуальных языков программирования, которые располагают встроенными (или доступными для скачивания) модулями.
Таким образом, появляется возможность использовать их в наших рабочих языках. Помимо ссылок на regex101, встречающихся по ходу статьи, во всех примерах кода будет применяться модуль регулярных выражений Python re.
Как же переложить на код этот метафорический образ листа картона? Обратимся к примеру.
Дана строка “Sylvie is 20 years old” (“Сильвии 20 лет”), и нужно извлечь из предложения только возраст, т.е. исключительно число. Для этой цели существует шаблон регулярного выражения \d — специальный символ, который соответствует только шаблонам, содержащим цифры (подробным разбором займемся позже).
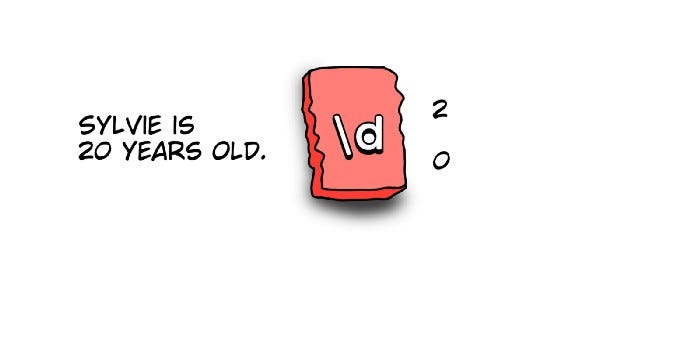
# Импортируем библиотеки
import re
txt = "Sylvie is 20 years old."
# Регулярное выражение для извлечения чисел из строки
age = re.findall(r'\d', txt)
print(age)Вывод:

Не совсем то, что нужно, но первый шаг навстречу цели уже сделан. По крайней мере, цифры обнаружены! Их распознал блок, вырезанный из красного картона.
В зависимости от условия он может в буквальном смысле варьироваться от одного буквенного символа алфавита (например, регулярное выражение a что ни на есть верное и предназначено для поиска a внутри строкового ввода) до группы специальных символов. Как мы увидим далее, они представлены в большом разнообразии.
Однако требуется получить не отдельные цифры, а целое число. Немного преобразуем используемый идентификатор с помощью другого блока.

# Импортируем библиотеки
import re
txt = "Sylvie is 20 years old."
# Получаем только двузначные числа
age = re.findall(r'\d{2}', txt)
print(age)Вывод:

Отлично! Мы получили возраст Сильвии из строки! Стоп, а если бы в ней также был указан год рождения? При использовании вышеприведенного выражения результатом стали бы все двузначные варианты чисел в предложении.

Поскольку это не входит в наши планы, то подумаем о внесении дальнейших изменений.
Добавляем граничное выражение, поскольку требуемое двузначное число окружено с обеих сторон пробелами.
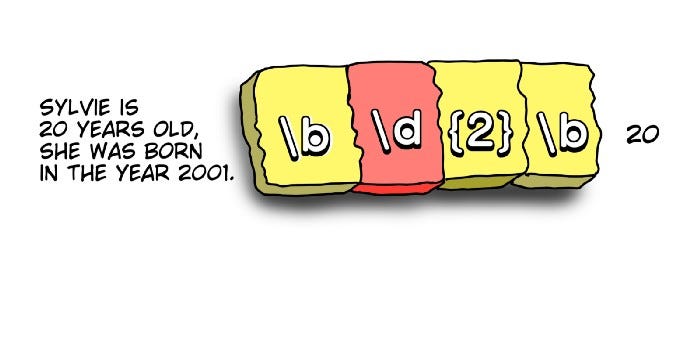
# Импортируем библиотеки
import re
txt = "Sylvie is 20 years old, she was born in the year 2001"
# Получаем только числа
age = re.findall(r'\b\d{2}\b', txt)
print(age)Бинго:

Мы получаем нужный результат, даже при наличии в строке четырехзначного числа. Ради интереса можете проверить действие ранее рассмотренных строк регулярных выражений:
Довольно аккуратно, не так ли? С помощью минимального однострочного кода мы извлекли число из строки.
Как уже ранее упоминалось, существует множество символов для создания в коде виртуальных аналогов таких вырезанных блоков. Пора с ними познакомиться.
Символы
- \d: цифровой символ от 0 до 9;
- \D: любой нецифровой символ;
- \s: пробельный символ;
- \S: любой непробельный символ;
- \w: любой символ;
- \W: любой не цифро-буквенный символ;
- \b: определяет границы слова;
- . : обозначает любой символ; (пример)
- \. : соответствует точке.
Модификаторы
- {}: группировка числовых значений. Например,
\d{3}дает совпадения, включающие 3 цифры, а\d{3,5}— совпадения, содержащие от 3 до 5 цифр. По сути, это{min, max}. - []: группировка символов. Соответствует одному из символов в скобках. Например,
[a-z]выдаст совпадения с каждым символом алфавита в нижнем регистре. - +: соответствует предыдущему элементу один или более раз. Например,
[a-z]+aсгруппирует результат совпадений, как показано в примере. - ?: соответствует предыдущему элементу 0 или один раз. Здесь можно посмотреть принцип действия
[a-z]?a. - *: соответствует предыдущему элементу 0 или множество раз. Обратимся к примеру
[a-z]*a. - $: означает конец строки.
- ^: указывает на начало строки.
- |: оператор или. Например, col(o|u)r соответствует и американскому, и британскому вариантам написания слова color.
Это был перечень самых распространенных модификаторов. Они понадобятся как для изучения данной статьи, так и в большинстве практических случаев. Однако расширенная шпаргалка с указанием других классов символов никогда не помешает.
Помимо знания символов также следует разобраться в основных принципах работы движка регулярных выражений. Тогда столкнувшись с непредвиденным результатом сложных случаев, вы уже не будете бесконечно долго теряться в догадках.
Принцип работы регулярных выражений
Существует 2 типа движков regex: первые ориентированы на текст, а вторые, наиболее распространенные, — на регулярные выражения. Вполне возможно, что вы с ними то как раз и работаете. Проведем простой тест с помощью Python для проверки используемого типа:
import re
pattern = "regex|regex not"
output = re.findall(pattern, "regex not")
print(output)
Полученный результат regex говорит о том, что вы используете движок, ориентированный на регулярные выражения. Почему это имеет значение? Потому что в нем реализуются такие важные функциональности, как ленивые квантификаторы и обратные ссылки.
Кроме того, есть еще один существенный момент касательно этого движка: он работает слева направо (такой же принцип действия характерен для предыдущего случая). Поясним на примере:
import re
pattern = r"dragon|fly|ing"
output = re.findall(pattern, "The dragonfly became friends with the flying dragon")
print(output)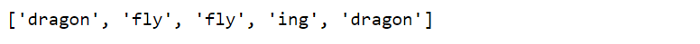
Как видим, поиск совпадений происходит слева направо. Освоение этих азов определенно поможет в дальнейшей работе.
А теперь, вооружившись новыми знаниями, применим их на практике. Перечислим несколько случаев применения регулярных выражений:
- парсинг входных данных, например текста, логов, веб-информации и т.д.;
- валидация пользовательского ввода;
- тестирование результатов вывода;
- поиск текста;
- реструктуризация данных.
Однако учиться лучше всего на примерах. Теперь, когда мы знаем принципы действия регулярных выражений и значения символов рассекречены, рассмотрим 3 конкретных ситуации их использования с помощью нескольких строк кода.
Пример 1. Валидация адресов электронной почты
В любом руководстве по регулярным выражениям данный пример встречается по умолчанию. Он представляет собой аналог “Hello World”, поэтому ему суждено быть в этом разделе. Его задача — проверять форматы вводимых адресов электронной почты.
Пошагово рассмотрим решение задачи. Во-первых, мы (зачастую) знаем, как выглядят корректные адреса e-mail:
someone@mailservice.domainИмя пользователя или someone обычно состоит из букв алфавита или комбинации цифр. Иногда могут встречаться и специальные символы, но новичкам в мире регулярных выражений лучше начать с простого примера.
Итак, у нас есть символы от a до z, цифры от 0 до 9, а также заглавные буквы в диапазоне A-Z. Регулярное выражение данной группы выглядит следующим образом:
[a-zA-Z0–9]
Аналогично, служба электронной почты обычно имеет буквенное обозначение, например Gmail, gmx, Hotmail, и следует за знаком @. Следовательно:
@[a-zA-Z]
На завершающем этапе рассмотрим наиболее известные домены — com, net, edu и org — которые указываются после знака точки вслед за провайдером службы электронной почты.
\.(com|net|edu|org)Объединяя все вместе, получаем регулярное выражение:
[a-zA-Z0–9]+@[a-zA-Z]+\.(com|net|org|edu)Теперь применим его в скрипте Python, который принимает на входе id электронной почты и проверяет его на соответствие требованиям формата.
# Импортируем библиотеки
import re
'''
В данном примере рассматривается обобщенный шаблон e-mail:
someone@mailservice.domain
'''
# Определяем допустимые шаблоны ввода электронной почты
pattern_email = r"[a-zA-Z0-9]+@[a-zA-Z]+\.(com|net|org|edu)"
#Создаем поле для ввода адреса электронной почты
user_input = input()
if (re.search(pattern_email, user_input)):
print(f"{user_input} is a valid email.")
else:
print(f"{user_input} is invalid.")Полученный результат выглядит следующим образом:

Теперь вы стали обладателем своего собственного валидатора id электронной почты.
Пример 2. Извлечение имен и значений возраста из текста
Ранее уже был рассмотрен упрощенный пример получения возраста из строки. В этом разделе научимся извлекать имена/текст и вносить их в словарь.
Нам уже известно, как с помощью регулярного выражения \b\d{2}\b извлечь двузначное число из строки. В случае с текстом в данном примере поработаем с 2 или 3 цифрами (из-за присутствия величины, обозначающей столетие).
Что касается процедуры получения имен из текста, то, как видим, каждое из них состоит из более 3 букв. В связи с этим, с задачей должны справиться группы строк с заглавными буквами длиной в 3 и более символов:
\b[A-z][a-z]{3,}\bДля итоговой операции по составлению словаря, в котором имена людей соответствуют их возрастам, как нельзя кстати подойдет простое грамматическое правило английского языка: в структуре предложения возраст всегда следует за именем.
# Импортируем библиотеки
import re
txt = "Sylvie is 20 years old, her father, Christoph, is 55.\
Her grandfather Johannes was born at the end of WW-1 in 1918.\
He was 100 years old when he died in 2018"
'''
Поскольку указанный в тексте возраст состоит из 2 или 3 цифр, то используется регулярное выражение \d{2,3}. Оно с двух сторон ограничено \b, поскольку нам не нужны группы из 2 или 3 цифр, полученные из числа 1918.
С именами в данном тексте все просто. Вполне сработает поиск всех слов, начинающихся с заглавных букв и содержащих более 3 символов. Делаем это также с границами.
'''
ages = re.findall(r'\b\d{2,3}\b', txt)
names = re.findall (r'\b[A-Z][a-z]{3,}\b',txt)
print(dict(zip(names, ages)))Результат:

Конечно же, по мере усложнения входного текста и необходимости извлечения большего объема информации более рациональным путем, придется прибегать к дополнительным средствам помимо регулярных выражений. Однако могу вас заверить, что даже в сложных случаях этот инструмент обязательно пригодится в той или иной степени для упрощения.
Пример 3. Сопоставление пароля с шаблоном
Большинство из вас наверняка встречали такое предложение при создании нового пароля:
“Для гарантии надежности пароль должен состоять как минимум из 8 символов, в число которых должны входить, по крайней мере, по одной заглавной и строчной букве, цифре и одному специальному символу”.
Когда-нибудь интересовались, как это сделать? Конечно, с помощью регулярных выражений. Данный пример немного посложнее, чем предыдущие, и включает ряд понятий, с которыми будем знакомиться в процессе. А затем, вооружившись ими, вы сами сможете создать простую версию.
Одна из частей задачи не вызывает сложности, так как основана на ранее изученном материале. Потребуются символы (верхнего и нижнего регистров) — A-Z и a-z, цифры — \d и специальные символы — _@$!%*?&, которые в сумме составляют строку длинной более 8 единиц:
[A-Za-z\d_@$!%*?&]{8,}Это гарантирует совпадения со всеми вариантами, включающими любые из перечисленных выше символов.
Например, asdf@1234 станет верным паролем даже без заглавной буквы. Пример.
Нужен метод, предварительно сопоставляющий и выявляющий хотя бы одно соответствие из каждой группы. Речь идет о позиционной проверке в регулярных выражениях. Она сопоставляет символы без указания конкретных совпадений. Вместо этого возвращается двоичный результат о наличии или отсутствии совпадение. Следовательно, по факту они являются утверждениями.
Позиционная проверка бывает двух типов:
Опережающая
- Позитивная опережающая проверка. Она проводится с использованием в строке символов
?=. Например,xyz(?=abc)предварительно просматривает всеxyz, проверяя наличиеabcи выявляя соответствия только при его обнаружении (Пример). - Негативная опережающая проверка. Аналогична предыдущей, но с помощью утверждения
?!выполняющая противоположную задачу. В этом случаеxyz(?!abc)предварительно просматривает всеxyz, проверяя отсутствиеabc, и выдает совпадения соответственно результатам (Пример).
Ретроспективная
- Позитивная ретроспективная проверка. В данной ситуации движок регулярных выражений временно работает в обратном направлении.
(?<=abc)xyzищет всеxyz, которым предшествуетabc, а именно справа налево (Пример). - Негативная ретроспективная проверка похожа на предыдущий вариант, но
(?<!abc)xyzуже ищет всеxyz, которым не предшествуетabc, а именно справа налево (Пример).
С учетом изученных понятий мы можем создать регулярное выражение для второй части задачи с паролем, и лучше всего подойдет позитивная опережающая проверка.
Рассмотрим все поэтапно. Для соответствия опережающей проверке необходимы заглавные буквы.
(?=[A-Z]) соотнесет заглавные буквы при предварительном просмотре и выдаст многочисленные совпадения по мере их обнаружения. Поскольку такие совпадения должны быть в любом месте строки, то преобразуем регулярное выражение в (?=.*[A-Z]).
Таким же образом поступим со
- строчными буквами:
(?=.*[a-z]); - цифрами:
(?=.*\d); - специальными символами:
(?=.*_@$!%*?&).
Объединяем все вместе между начальным и конечным идентификаторами строки (соответственно ^ и $):
^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[@$!%*?&])[A-Za-z\d@$!%*?&]{8,}$Согласитесь, что сейчас все становится намного понятнее. Теперь реализуем простой инструмент проверки надежности пароля с помощью данного регулярного выражения:
# Импортируем библиотеки
import getpass
import re
pattern_password =\
r"^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[@$!%*?&])[A-Za-z\d@$!%*?&]{8,}$"
# Используем getpass вместо стандартной функции ввода
# Это позволит скрыть запись как в реальной жизни
user_input = getpass.getpass()
invalid_pass_text = \
"Your password must have at least 8 characters,\
at least an upper case letter,\
a lowercase letter, a number, \
and a symbol so as to be secure"
if (re.search(pattern_password, user_input)):
print("Strong Password Set")
else:
print(invalid_pass_text)Результат выглядит следующим образом (с паролями abcABC@1234 и abcABC1234):

Читайте также:
- Шпаргалка по регулярным выражениям. В примерах
- Python. Пять уловок, которые нужно знать, уже сегодня
- Почему не стоит использовать or для проверки нескольких условий в Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи Krupesh Raikar: Everything You Need To Know About Regular Expressions in Python





