
Библиотека Python Pandas и язык структурированных запросов (SQL) — основные инструменты в арсенале специалиста по анализу данных. Хотя Pandas — мощный инструмент для работы с данными, многие специалисты с той же целью предпочитают использовать SQL. В этой статье будет рассказано, как выполнять манипуляции с данными в Pandas Dataframe, используя SQL с применением библиотеки pandasql.
Что такое Pandasql?
Pandasql — это библиотека Python, которая позволяет обрабатывать датафреймы Pandas с помощью SQL. С точки зрения внутреннего устройства, Pandasql создает таблицу SQLite из интересующего вас датафрейма Pandas и позволяет пользователям делать запросы к таблице SQLite с помощью SQL.
Как работает Pandasql?
Устанавливаем пакет Pandasql.
!pip install -U pandasqlИмпортируем необходимые пакеты.
from pandasql import sqldf
import pandas as pd
from sklearn import datasetsВ качестве примера будем использовать датасет iris. df_feature — датафрейм, содержащий основные характеристики, а df_target — серии, содержащие целевые объекты. Pandasql может работать как с DataFrame Pandas, так и с Series.
df_feature = datasets.load_iris(as_frame = True)['data']
df_target = datasets.load_iris(as_frame = True)['target']
print (type(df_feature))
print (type(df_target))
>> <class 'pandas.core.frame.DataFrame'>
>> <class 'pandas.core.series.Series'>Метод sqldf используется для запроса датафреймов и требует 2 вида входных данных:
- строка запроса SQL;
- функция
globals()илиlocals().
Типичный запрос выглядит следующим образом, где q — это строка SQL-запроса. sqldf возвращает результат в виде датафрейма.
q = "SELECT * FROM df_target LIMIT 3"
sqldf(q, globals())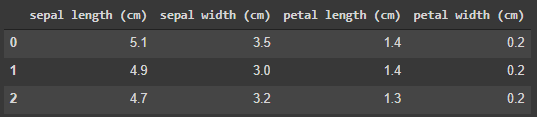
globals() и locals() — встроенные в python методы, в которых хранятся функции и переменные. Посмотрим, что делает метод globals().
globals()
Функция globals() возвращает словарь переменных, созданных в данной сессии, таких как df_feature и df_target. Ключом словаря является имя переменной, а значение словаря содержит фактическое значение переменной.
print (globals().keys())
>> dict_keys(['__name__', '__doc__', '__package__', '__loader__', '__spec__', '__builtin__', '__builtins__', '_ih', '_oh', '_dh', '_sh', 'In', 'Out', 'get_ipython', 'exit', 'quit', '_', '__', '___', '_i', '_ii', '_iii', '_i1', '_exit_code', '_i2', 'sqldf', 'pd', 'datasets', '_i3', 'df_feature', 'df_target', '_i4', '_4', '_i5', '_5', '_i6'])Поскольку функция globals() выводит словарь, то можно получить доступ к значениям переменных с помощью функции globals() следующим образом:
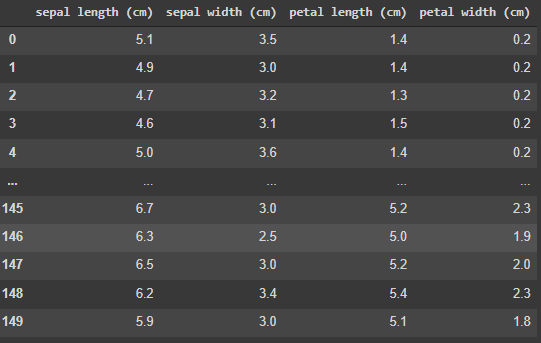
globals()['df_feature']Это вернет датафрейм df_feature.
Примеры
Мы узнали, как функции globals() и locals() работают с Pandasql. Теперь рассмотрим несколько примеров. Создадим новую функцию pysqldf, чтобы избежать передачи globals() и locals() для каждого запроса.
pysqldf = lambda q: sqldf(q, globals())Запросить датафреймы можно следующим образом:
query = 'SELECT * FROM df_feature LIMIT 3'
pysqldf(query)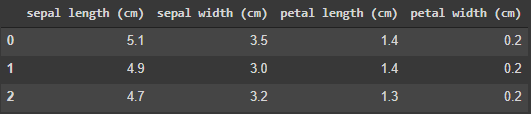
query = 'SELECT * FROM df_target LIMIT 3'
pysqldf(query)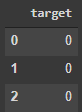
Объединим два датафрейма df_feature и df_target. В Pandas это можно сделать с помощью метода pd.concat.
pd.concat([df_feature, df_target], axis = 1).head()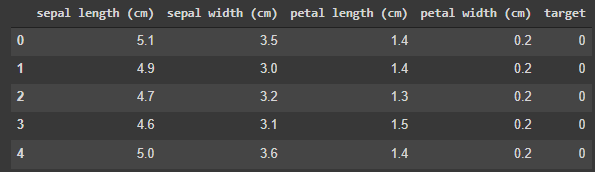
Использование SQL позволяет создать столбец номера строки и соединить две таблицы с помощью номера строки. Поскольку Pandasql использует SQLite, в таблице SQLite по умолчанию будет создан столбец rowid. Этот столбец содержит инкрементные целочисленные значения, начиная с 1.
query = 'SELECT rowid, * FROM df_feature LIMIT 3'
pysqldf(query)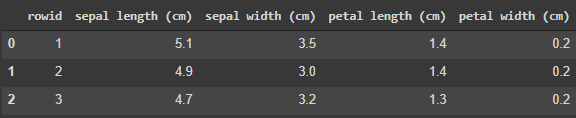
Теперь можно объединить обе таблицы по столбцу rowid. Полученный результат можно присвоить другой переменной, которую впоследствии можно будет снова запросить с помощью Pandasql.
query = 'SELECT * FROM df_feature INNER JOIN df_target ON df_feature.rowid = df_target.rowid'
df = pysqldf(query)
df.head()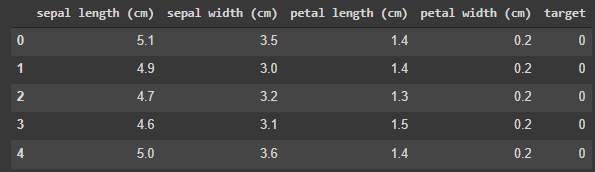
Вот примеры других операций, которые можно выполнить.
- Нахождение средней длины чашелистика для разных целевых классов. Обратите внимание, что
"sepal length (cm)"заключено в кавычки. Это необходимо только в том случае, если в названиях столбцов есть пробелы.
query = 'SELECT target, AVG("sepal length (cm)") AS mean_sepal_length
FROM df GROUP BY target'
pysqldf(query)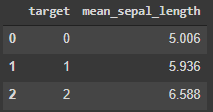
- Можно также использовать f-строки в python для создания динамических строк SQL-запросов.
COL_NAME = '"sepal length (cm)"'
ALIAS = 'sepal_length'
AGG = 'MAX'
query = f"SELECT {AGG}({COL_NAME}) AS {ALIAS} FROM df"
pysqldf(query)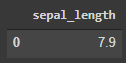
Ограничения Pandasql
- Поскольку Pandasql использует SQLite, на него распространяются все ограничения SQLite. Например, SQLite не реализует правое внешнее соединение и полное внешнее соединение.
- Pandasql выполняет только запросы и не может выполнять такие SQL-операции, как обновление, вставка и изменение таблиц.
Заключение
Pandasql — это отличное дополнение к инструментарию тех исследователей данных, которые предпочитают использовать синтаксис SQL, а не Pandas. Теперь и вы знаете, как запросить датафрейм Pandas с помощью SQL с использованием Pandasql и можете применить полученные знания на практике, учитывая возможности и ограничения библиотеки Pandasql.
Читайте также:
- 10 лайфхаков для работы с библиотекой Pandas
- По маршруту SQLite - Pandas: 7 основных операций
- 3 классные малоизвестные функции Pandas
Читайте нас в Telegram, VK и Дзен
Перевод статьи Edwin Tan: Query Pandas DataFrame with SQL





