
Я и раньше писал о Pandas по очевидным причинам — это изумительная библиотека для анализа данных и даже для визуализации. Предыдущая статья была о функциях, которые стоит чаще использовать, потому что они:
- держат ваш код в чистоте;
- не заставляют вас заново изобретать колесо.
Однако в сегодняшнем посте я хочу сместить фокус на некоторые более полезные функции, которые заставили меня почувствовать себя полнейшим идиотом. Почему же, спросите вы. Я ленился и не гуглил перед тем, как писать код, и поэтому просто не знал о существовании этих функций.
Конечный результат был разочаровывающим. Я реализовывал необходимую логику, но ценой нескольких лишних часов, седых волос и, безусловно, кучи ненужного кода.
Ниже перечисленные функции помогут избежать подобных ошибок.
idxmin() и idxmax()
Да, я уже писал о них ранее, но они необходимы, чтобы этот пост имел смысл. Вы не сможете понять вторую полезную функцию, если не разберетесь предварительно с этими.
Вкратце, эти функции возвращают ID (индекс) нужной записи. Скажем, я создам следующий массив Pandas:
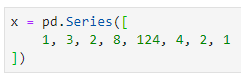
И хочу найти индексы наименьшего и наибольшего элементов. Разумеется, очень легко найти их и так, но никогда (я действительно имею в виду никогда) не бывает настолько мало данных в проектах.
Это означает, что эти функции вам точно пригодятся. Давайте посмотрим, как:
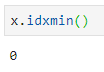
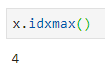
Имейте в виду, что функции возвращают индекс первого наблюдаемого наименьшего или наибольшего значений.
ne()
Эта функция стала для меня открытием. Некоторое время назад я работал с временными данными, и у меня возникли проблемы, когда несколько первых наблюдаемых значений были равны 0.
Проще говоря, представьте, что вы купили что-то, но не использовали в течение некоторого времени. Вещь находится в вашем распоряжении, но, раз вы ее не используете, потребление в этот период равно 0. В случае, если меня интересует именно потребление и оно начинается с момента фактического использования вещи, функция ne() прекрасно подойдет.
Давайте рассмотрим следующий сценарий: у вас есть объект Pandas DataFrame с несколькими нулевыми значениями в начале:

Функция ne() вернет True, если текущее значение не равно заданному (скажем 0), и False в обратном случае:

Само по себе это не очень полезно. Помните, что выше я отметил, что вам нужно знать idxmax(), чтобы понять эту тему? Что ж, вот и оно, вы можете включить idxmax() в код ниже:
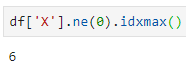
Итак, в индексе 6 у нас впервые появляется ненулевое значение. Еще раз — это пока еще не представляет большой ценности. А вот что действительно можно сделать, так это использовать эту информацию, чтобы DataFrame выводил только значения, начинающиеся с того момента, когда элемент был впервые использован:

И это полезно каждый раз, когда вы имеете дело с временными данными.
nsmallest() и nlargest()
Я думаю, вы догадались о назначении этих функций по именам. Скажем, я создам следующий объект DataFrame:
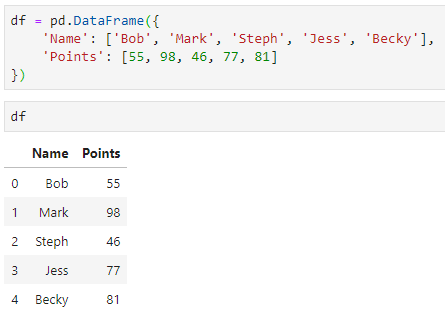
Давайте предположим, что это 5 записей баллов, полученных после написания теста. И нам нужно найти трех студентов, которые справились хуже всех:
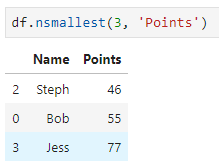
Или трех студентов, которые справились лучше всех:
Эти две функции являются отличной заменой таким функциям, как sort_values().
Читайте также:
- 5 Расширенных возможностей Pandas и как ими пользоваться
- Строим конвейеры с Pandas, используя «pdpipe»
- Одно слово для «быстрой» Pandas
Перевод статьи Dario Radečić: Top 3 Pandas Functions You Don’t Know About (Probably)





