
По роду своей деятельности я слежу за качеством данных и немного меняю способ их генерирования и сбора. В такой ситуации важно убедиться в согласованности данных между старым и новым подходами. Посмотрим, можно ли автоматизировать эту задачу с помощью Terraform и BigQuery.
Как и я, вы наверняка тоже задаетесь вопросом, подходит ли для этой цели BigQuery. Вероятно, использование этого инструмента подобно поездке на Ferrari в соседний магазин за продуктами.
На самом деле мне уже удалось решить эту задачу с помощью Microsoft U-SQL, поэтому подойдет любой инструмент, способный запрашивать CSV. Однако вариант решения с BigQuery представляется весьма интересным.
Для простоты понимания изучите мой репозиторий на GitHub, куда я загрузил весь материал, включая фиктивные тестовые данные.
Необходимые требования
- Аккаунт на Google Cloud;
- Google SDK;
- Terraform.
При использовании Google Cloud shell → SDK и Terraform предоставляются по умолчанию!
Описание задачи
Поскольку мы обновляем процесс ELT, нужно убедиться, что он не сопровождается потерей данных. Появление новых из них допускается, а вот отсутствие старых — нет.
Чтобы это проконтролировать, я создал несколько коллекций данных и начал сравнивать их вручную. Как можно представить, это оказалось совсем не продуктивно.
Я решил автоматизировать сравнение нескольких сложных датасетов. Мне нужно было установить, происходит ли потеря данных в каждом из них, и сделать это, автоматизируя создание среды и необходимых сервисов.
В рамках этой статьи мы сосредоточимся только на одном из датасетов. Таблица BSEG в SAP.
Хранилище
В результате извлечения данные выводятся в виде файлов CSV. BigQuery позволяет запрашивать CSV, которые хранятся в хранилище Google Cloud Storage. Далее необходимо создать контейнер (bucket), используя google_storage_bucket, и загрузить оба файла в виде объектов google_storage_bucket_object, чтобы обеспечить BigQuery к ним доступ. Ниже представлены фрагменты кода контейнеров:
resource "google_storage_bucket" "datatables_bucket" {
project = google_project.bigquery_project.project_id
name = random_id.storage.hex
location = "EU"
force_destroy = true
lifecycle_rule {
condition {
age = 2
}
action {
type = "Delete"
}
}
}
resource "google_storage_bucket_object" "datatables_original_csv" {
name = "original/BSEG.csv"
source = "./Data/original/BSEG.csv"
bucket = random_id.storage.hex
depends_on = [
google_storage_bucket.datatables_bucket,
]
}
resource "google_storage_bucket_object" "datatables_new_csv" {
name = "newversion/BSEG.csv"
source = "./Data/newversion/BSEG.csv"
bucket = random_id.storage.hex
depends_on = [
google_storage_bucket.datatables_bucket,
]
}BigQuery
После загрузки датасетов в облако можно обращаться к ним из BigQuery. Но для этого сначала нужно создать датасет, который впоследствии сможет ссылаться на файлы CSV и использовать их в качестве таблиц. Задействуем ресурс google_bigquery_dataset для создания экземпляра BigQuery.
resource "google_bigquery_dataset" "default" {
project = google_project.bigquery_project.project_id
dataset_id = "test"
friendly_name = "test"
description = "Testing - SAP table compare."
location = "EU"
default_table_expiration_ms = 10800000 // 3 hr
depends_on = [
google_storage_bucket_object.datatables_original_csv,
google_storage_bucket_object.datatables_new_csv,
]
}Как видно, я добавил хранилище в качестве зависимости для BigQuery. Объясняется это тем, что Terraform может параллельно начать создавать сервисы. Поскольку BigQuery создавался до загрузки данных, это привело к ошибкам инстанцирования, которые были устранены простым добавлением зависимости.
Теперь когда данные и BigQuery на своих местах, обратимся к файлам CSV и выполним к ним запрос. Для создания ссылки на BigQuery воспользуемся таблицей google_bigquery_table.
В ряде случаев BigQuery может самостоятельно определить схему данных. В нашем же примере ему это не удалось, поэтому мне пришлось указать ему, как следует интерпретировать СSV.
resource "google_bigquery_table" "original_bseg" {
project = google_project.bigquery_project.project_id
dataset_id = google_bigquery_dataset.default.dataset_id
table_id = "original_bseg"
deletion_protection = false
schema = file("./Data/original/BSEG_metadata.json")
external_data_configuration {
autodetect = true
source_format = "CSV"
csv_options {
quote = "\""
skip_leading_rows = 1
}
source_uris = [
"${google_storage_bucket.datatables_bucket.url}/original/BSEG.csv",
]
}
depends_on = [
google_bigquery_dataset.default,
]
}Тестирование
Пора запускать среду и проводить сравнения. Выполняем всеми любимые команды:
$> terraform init
$> terraform plan
$> terraform applyВ консоли Google Cloud Console переходим к BigQuery. Вы должны увидеть один датасет с двумя таблицами.
Вставляем этот запрос в редактор и нажимаем RUN.
SELECT
sid, mandt, bukrs, belnr, gjahr, buzei, buzid, augdt, augcp, augbl, bschl, koart, umskz, umsks, zumsk, shkzg, gsber, mwskz, qsskz, pswsl, mwart, ktosl, zuonr, sgtxt, vbund, vorgn, fdtag, fkont, kokrs, kostl, aufnr, vbeln, vbel2, posn2, anln1, anln2, anbwa, bzdat, xumsw, xauto, xzahl, saknr, hkont, kunnr, lifnr, xbilk, gvtyp, zfbdt, zterm, zlsch, zlspr, zbfix, hbkid, rebzg, rebzj, rebzz, rebzt, zolld, landl, anfae, mschl, mansp, madat, manst, maber, matnr, werks, meins, ebeln, ebelp, zekkn, vprsv, bwkey, bwtar, bustw, tbtkz, egbld, eglld, rstgr, prctr, dabrz, xragl, pprct, xref1, xref2, fkber, xnegp, kkber, empfb, xref3, kidno, pycur, penrc, auggj, kstar, dmbtr, wrbtr, kzbtr, pswbt, mwsts, wmwst, bdiff, zbd1t, zbd2t, zbd3t, zbd1p, zbd2p, skfbt, sknto, wskto, dmbt1, wrbt1, menge, projk, agzei, pyamt, ppdiff, penlc1, penfc
FROM `test.original_bseg`
EXCEPT DISTINCT
SELECT
sid, mandt, bukrs, belnr, gjahr, buzei, buzid, augdt, augcp, augbl, bschl, koart, umskz, umsks, zumsk, shkzg, gsber, mwskz, qsskz, pswsl, mwart, ktosl, zuonr, sgtxt, vbund, vorgn, fdtag, fkont, kokrs, kostl, aufnr, vbeln, vbel2, posn2, anln1, anln2, anbwa, bzdat, xumsw, xauto, xzahl, saknr, hkont, kunnr, lifnr, xbilk, gvtyp, zfbdt, zterm, zlsch, zlspr, zbfix, hbkid, rebzg, rebzj, rebzz, rebzt, zolld, landl, anfae, mschl, mansp, madat, manst, maber, matnr, werks, meins, ebeln, ebelp, zekkn, vprsv, bwkey, bwtar, bustw, tbtkz, egbld, eglld, rstgr, prctr, dabrz, xragl, pprct, xref1, xref2, fkber, xnegp, kkber, empfb, xref3, kidno, pycur, penrc, auggj, kstar, dmbtr, wrbtr, kzbtr, pswbt, mwsts, wmwst, bdiff, zbd1t, zbd2t, zbd3t, zbd1p, zbd2p, skfbt, sknto, wskto, dmbt1, wrbt1, menge, projk, agzei, pyamt, ppdiff, penlc1, penfc
FROM `test.newversion_bseg`;Определите, какие данные из A отсутствуют в B.
Если вы следовали инструкциям, используя мои тестовые данные, то получите только одну строку с контрольными показателями.
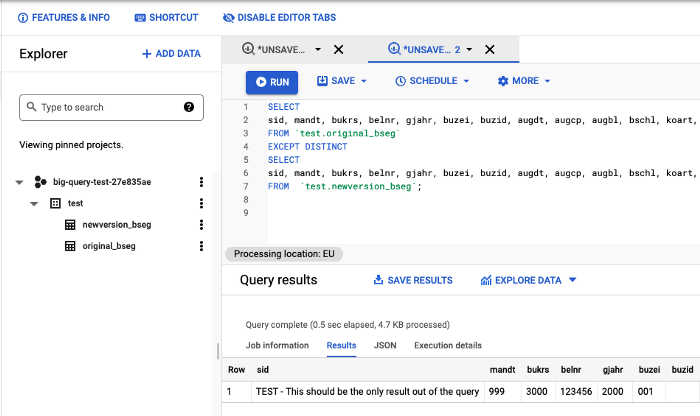
Результаты теста
Тест прошел успешно: между датасетами (ни настоящими, ни фиктивными) не было обнаружено никаких отличий.
Не забудьте:
$> terraform destroyЧитайте также:
- Создание динамического кластера ECS с помощью Terraform
- Как создать бота для автоматизации повседневных задач, с помощью Python и Google BigQuery
- Алгоритм XGBoost: пусть он царствует долго!
Читайте нас в Telegram, VK и Дзен
Перевод статьи Rafael Escoto: How to Automate Dataset Comparison Using Terraform And BigQuery





