
Представим такой ход развития событий:
Когда-то вы освободили место на жестком диске ноутбука и загрузили в облако три больших ZIP-файла по 8 ГБ каждый. Теперь вы хотите посмотреть любимый фильм и точно знаете, что он в одном из загруженных архивов. Но при этом вы в отпуске, данные передаются с мобильного телефона, соединение медленное, а превышение 10 ГБ трансфера потребует дополнительной оплаты. Эти три файла называются:
backup1.zip,backup2.zipиbackup3.zip. Вопрос знатокам: какой же из них скачать?
Если вас заинтересовала задача и способ ее решения, и вы не прочь узнать что-то новое про AWS, формат ZIP-файла и HTTP-запросы, то добро пожаловать!
Веб-сервисы Amazon (AWS)
Бессерверная технология выше всяких похвал. Благодаря ей мы можем писать и развертывать исполняемый код, не забивая себе голову проблемами лежащей в основе инфраструктуры.
Из этой статьи вы узнаете, как работать с такими бессерверными сервисами AWS, как S3 и Lambda.
- Amazon Simple Storage Service (Amazon S3) — это сервис хранения объектов, предназначенный для извлечений любых данных из любого места.
- AWS Lambda — это управляемый событиями вычислительный сервис, который выполняет код.
Оба сервиса относятся к категории бессерверных. А это значит, что вам не надо думать о серверах или кластерах, поскольку всем управляет AWS.
HTTP-метод HEAD
Вы наверняка уже знаете такие HTTP-запросы, как:
- GET;
- POST;
- PUT;
- DELETE.
А знаком ли вам HTTP-метод HEAD? По своему принципу действия он аналогичен методу GET, за исключением того, что не скачивает данные. За более точной информацией обратимся к веб-документации MDN Web Docs.
HTTP-метод
HEADзапрашивает заголовки, идентичные тем, что возвращаются при запросе указанного URL посредством HTTP-методаGET.
Иначе говоря, при выполнении запроса HEAD вы получаете только заголовки ответа. Один из них — заголовок Content-Length, указывающий размер тела сообщения.
Заголовок HTTP-запроса Range
С методом запроса HEAD мы разобрались. Теперь узнаем кое-что новое об известном методе GET, а именно о заголовке HTTP-запроса Range.
Этот заголовок запроса указывает серверу, какую часть документа он должен вернуть. Например, можно отправить запрос GET с заголовком Range: bytes=100–199 и получить байты из заданного диапазона запроса. В данном случае — 100 байтов, начиная с 100-го байта файла.
Формат ZIP-файла
ZIP — это формат архивного файла. На этом ресурсе приведена его полная спецификация. Она носит довольно технический характер. Тот факт, что я с ней уже ознакомился, избавляет вас от необходимости ее читать.
Для наших целей достаточно лишь знать, что ZIP-файлы обладают четко определенной структурой. Каждый из них распознается по end of central directory record (запись EOCD), которая находится в конце архивной структуры. ZIP-файл также содержит central directory entry (запись CD). В ней фиксируется имя каждого файла или директории в архиве вместе с другими метаданными о записи, а также смещение, указывающее на фактические данные записи.
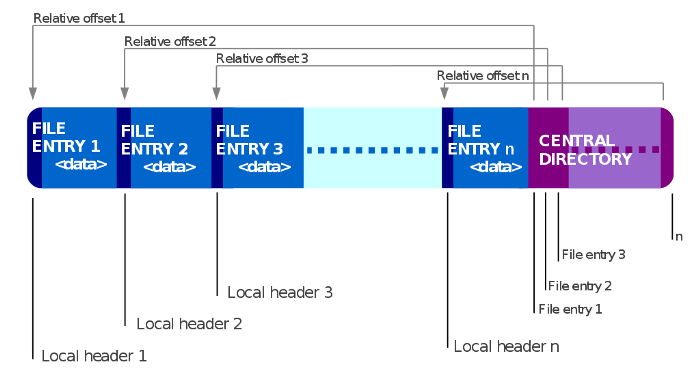
Стандартный формат ZIP-файла имеет ограничение в 4 ГБ. Если файл превышает данный размер, он архивируется в обновленной версии формата — ZIP64. Между этими форматами существует пара отличий. Нас же интересует наличие дополнительных ZIP64 End Of Central Directory Record (конец записи центрального каталога) и ZIP64 End of Central Directory Locator (конец локатора центрального каталога):
[local file header 1..n]
[encryption header 1..n]
[file data 1..n]
[data descriptor 1..n]
...
[central directory header 1..n]
[zip64 end of central directory record]
[zip64 end of central directory locator]
[end of central directory record]Мы завершили обзор теоретического материала, необходимого для понимания последующего алгоритма.
Алгоритм
- Сначала узнаем размер файла. Для этого отправляем запрос
HEADи читаем заголовок ответаContent-Length. - Затем получаем запись EOCD, отправляя запрос
GETс заголовкомRange. EOCD всегда находится в конце ZIP-файла и составляет 22 байта. - Из записи EOCD извлекаем метаданные CD, а именно его размер и смещение от начала. Они всегда занимают от 12 до 20 байтов. Что касается EOCD, можно отправить запрос
GETс заданным диапазономRange. Проводим парсинг полученных данных, так как согласно спецификации: “Все значения ДОЛЖНЫ храниться в обратном (от младшего к старшему) порядке байтов”. Нам же понадобитсяint.
Offset | Bytes | Description
12 | 4 | Size of central directory
16 | 4 | Offset of start of CD, relative to start of archive4. Располагая метаданными CD (его началом и размером), получаем и сам CD. Для этого снова отправляем запрос GET с заголовком Range.
5. На предпоследнем этапе просто читаем поток байтов. CD и EOCD располагаются непосредственно друг за другом, поэтому наличие их обоих позволяет читать блок байтов.
6. И еще один прием напоследок. Байты CD+EOCD можно открыть как ZIP-файл и сделать с ним все, что угодно. Например, перебрать файлы в списке и вывести все их имена.
ZIP64
Как ранее упоминалось, структуры ZIP и ZIP64 немного отличаются. Алгоритм для ZIP64 выглядит точно так же. Единственное отличие в том, что потребуется получить дополнительную запись ZIP64 EOCD и локатор ZIP64 EOCD. Это даст возможность прочитать 4 блока байтов (CD+запись EOCD64+локатор EOCD64+EOCD) и открыть их как ZIP-файл.
Offset | Bytes | Description
40 | 8 | Size of central directory
48 | 8 | Offset of start of CD, relative to start of archiveКод
Ниже представлен рабочий пример кода для вывода содержимого ZIP-файла без необходимости скачивать его целиком.
Этот код работает для файлов, расположенных в хранилище S3. Лямбда-функция вызывается в ответ на оповещение о событии S3.
import boto3
import io
import struct
import zipfile
s3 = boto3.client('s3')
EOCD_RECORD_SIZE = 22
ZIP64_EOCD_RECORD_SIZE = 56
ZIP64_EOCD_LOCATOR_SIZE = 20
MAX_STANDARD_ZIP_SIZE = 4_294_967_295
def lambda_handler(event):
bucket = event['bucket']
key = event['key']
zip_file = get_zip_file(bucket, key)
print_zip_content(zip_file)
def get_zip_file(bucket, key):
file_size = get_file_size(bucket, key)
eocd_record = fetch(bucket, key, file_size - EOCD_RECORD_SIZE, EOCD_RECORD_SIZE)
if file_size <= MAX_STANDARD_ZIP_SIZE:
cd_start, cd_size = get_central_directory_metadata_from_eocd(eocd_record)
central_directory = fetch(bucket, key, cd_start, cd_size)
return zipfile.ZipFile(io.BytesIO(central_directory + eocd_record))
else:
zip64_eocd_record = fetch(bucket, key,
file_size - (EOCD_RECORD_SIZE + ZIP64_EOCD_LOCATOR_SIZE + ZIP64_EOCD_RECORD_SIZE),
ZIP64_EOCD_RECORD_SIZE)
zip64_eocd_locator = fetch(bucket, key,
file_size - (EOCD_RECORD_SIZE + ZIP64_EOCD_LOCATOR_SIZE),
ZIP64_EOCD_LOCATOR_SIZE)
cd_start, cd_size = get_central_directory_metadata_from_eocd64(zip64_eocd_record)
central_directory = fetch(bucket, key, cd_start, cd_size)
return zipfile.ZipFile(io.BytesIO(central_directory + zip64_eocd_record + zip64_eocd_locator + eocd_record))
def get_file_size(bucket, key):
head_response = s3.head_object(Bucket=bucket, Key=key)
return head_response['ContentLength']
def fetch(bucket, key, start, length):
end = start + length - 1
response = s3.get_object(Bucket=bucket, Key=key, Range="bytes=%d-%d" % (start, end))
return response['Body'].read()
def get_central_directory_metadata_from_eocd(eocd):
cd_size = parse_little_endian_to_int(eocd[12:16])
cd_start = parse_little_endian_to_int(eocd[16:20])
return cd_start, cd_size
def get_central_directory_metadata_from_eocd64(eocd64):
cd_size = parse_little_endian_to_int(eocd64[40:48])
cd_start = parse_little_endian_to_int(eocd64[48:56])
return cd_start, cd_size
def parse_little_endian_to_int(little_endian_bytes):
format_character = "i" if len(little_endian_bytes) == 4 else "q"
return struct.unpack("<" + format_character, little_endian_bytes)[0]
def print_zip_content(zip_file):
for zi in zip_file.filelist:
print(zi.filename)После вывода всех файлов вы можете найти любимый фильм и скачать только один ZIP-файл, будучи на 100% уверенным в выборе нужного архива!
Заключение
В статье был рассмотрен вывод списка содержимого ZIP-файла без его скачивания. В реализации этого способа нам помогли методы HTTP-запроса, заголовки и знание структуры формата ZIP-файла.
Читайте также:
- Форматы .tar .zip .gz: Различия и эффективность
- Что такое бессерверная платформа?
- Как создать самообновляющийся заголовок Twitter с динамическим контентом
Читайте нас в Telegram, VK и Дзен
Перевод статьи Krzysztof Kwieciński: Determine the Contents of a Zip File Without Downloading It





