
Поиск сходства является подразделом машинного обучения и относится к нахождению элементов, близко связанных с исходным вводом. Эта техника невероятно полезна в таких сферах, как товары, музыка или рекомендации кино. Смотрели “Офис” на Netflix? Вот вам другие аналогичные шоу, которые вы наверняка оцените. Часто слушаете Bayside на Spotify? Вашему вниманию другие поп-панк группы.
Поиск сходства также применяется для автоматизации клиентской поддержки. Что, если на заданный клиентом вопрос вы бы могли программно находить подобные заданные ранее вопросы с ответами, которые могут его устроить?
В текущей статье мы создадим с помощью Python и Flask приложение, использующее Pinecone — управляемый поисковый сервис — как раз для этой задачи.
Мотив и применение в реальном мире
Прежде чем перейти к демо-приложению, мы получше сформулируем саму решаемую задачу.
Представьте, что состоите на руководящей должности в крупной компании с тысячами или даже миллионами клиентов. Ваша клиентская поддержка изо дня в день получает одни и те же вопросы. Чтобы сэкономить время и деньги, вы можете оптимизировать процесс предоставления помощи клиентами с помощью публичной документации и страниц в стиле Вопрос-Ответ.
Но как гарантировать, чтобы клиенты нашли интересующие их ответы? В конце концов, создать документацию — это только половина дела.
Многие компании в этом случае используют решение в виде виртуального собеседника. Когда клиент только инициирует диалог, сначала общение идет с ботом. Пользователь задает свой вопрос, и бот старается помочь с ним разобраться. Если ему удается выстроить точный диалог из уточняющих вопросов и ответов, то клиент вполне может решить свою проблему сам.
Если же это не срабатывает, то можно запросить связь с оператором. Искусственный интеллект и машинное обучение не способны решить все наши проблемы — пока что.
Обзор демо-приложения
А теперь перейдем к нашему приложению. Ниже вы видите короткую анимацию, демонстрирующую его работу. Пользователь вводит вопрос и отправляет форму, после чего перед ним появляются связанные по смыслу вопросы, среди которых можно поискать ответ.
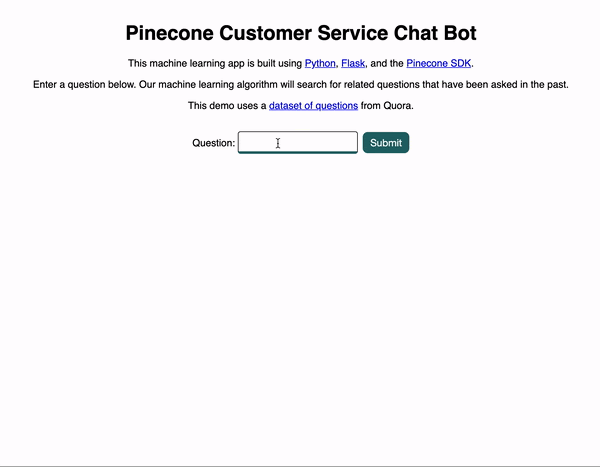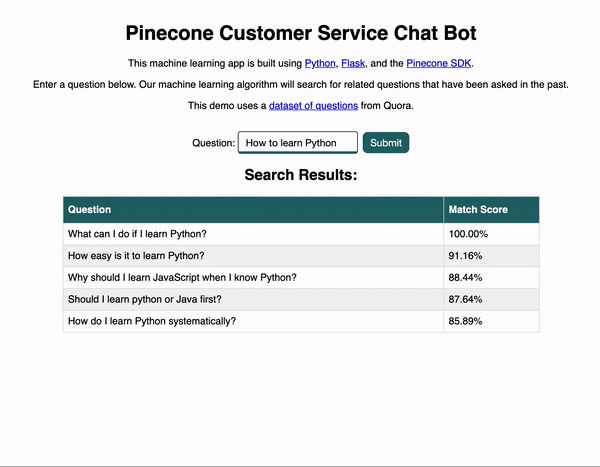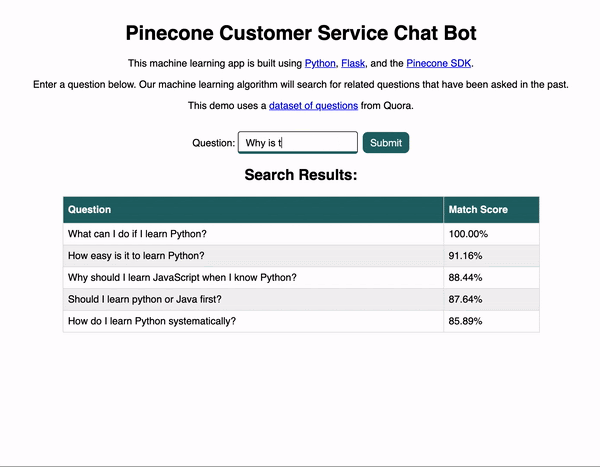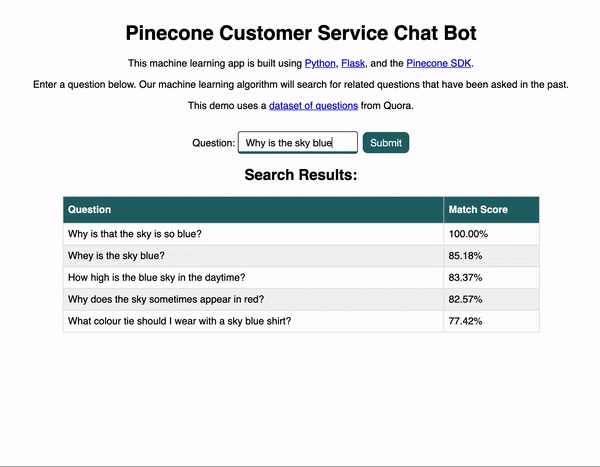
Неплохо, да? Как же это работает?
При построении данного приложения мы сначала нашли датасет вопросов и ответов на Quora. В нем содержаться сотни тысяч вопросов, но мы взяли только первые 50,000.
После этого выбранные вопросы мы прогнали через модель, создающую векторные представления слов, иногда называемые эмбеддингами.
Векторное представление слова (англ.), по сути, является списком чисел, предоставляющих метаданные для алгоритмов машинного обучения (МО) с целью определения сходства между входными данными.
Мы для этой цели взяли модель Average Word Embeddings (англ.). Полученные представления мы добавили в индекс, управляемый Pinecone.
Теперь, при отправке пользователем вопроса будет создаваться запрос к конечной точке API, которая с помощью SDK Pinecone будет получать нужный индекс представления.
Конечная точка возвращает пять похожих вопросов, которые отображаются в UI приложения.
Другими словами, Pinecone — как управляемое решение по поиску подобий — предоставляет механизм для возвращения рекомендаций. Вам лишь нужно обеспечить для него векторные представления слов, сгенерированные соответствующей моделью.
Если хотите попробовать сами, то код этого приложения находится на GitHub. В файле README содержатся инструкции по его локальному запуску на вашей машине.
Пояснение кода
Теперь, когда мы знаем смысл проекта и имеем общее представление о принципе работы приложения, можно углубляться в код, чтобы понять его внутренние процессы.
Для простоты весь бэкенд-код содержится в файле app.py, который в полном виде представлен ниже:
from dotenv import load_dotenv
from flask import Flask
from flask import render_template
from flask import request
from flask import url_for
import json
import os
import pandas as pd
import pinecone
import requests
from sentence_transformers import SentenceTransformer
app = Flask(__name__)
pinecone_index_name = "question-answering-chatbot"
DATA_DIR = "tmp"
DATA_FILE = f"{DATA_DIR}/quora_duplicate_questions.tsv"
DATA_URL = "https://qim.fs.quoracdn.net/quora_duplicate_questions.tsv"
def initialize_pinecone():
load_dotenv()
PINECONE_API_KEY = os.environ["PINECONE_API_KEY"]
pinecone.init(api_key=PINECONE_API_KEY)
def delete_existing_pinecone_index():
if pinecone_index_name in pinecone.list_indexes():
pinecone.delete_index(pinecone_index_name)
def create_pinecone_index():
pinecone.create_index(name=pinecone_index_name, metric="cosine", shards=1)
pinecone_index = pinecone.Index(name=pinecone_index_name)
return pinecone_index
def download_data():
os.makedirs(DATA_DIR, exist_ok=True)
if not os.path.exists(DATA_FILE):
r = requests.get(DATA_URL)
with open(DATA_FILE, "wb") as f:
f.write(r.content)
def read_tsv_file():
df = pd.read_csv(
f"{DATA_FILE}", sep="\t", usecols=["qid1", "question1"], index_col=False
)
df = df.sample(frac=1).reset_index(drop=True)
df.drop_duplicates(inplace=True)
return df
def create_and_apply_model():
model = SentenceTransformer("average_word_embeddings_glove.6B.300d")
df["question_vector"] = df.question1.apply(lambda x: model.encode(str(x)))
pinecone_index.upsert(items=zip(df.qid1, df.question_vector))
return model
def query_pinecone(search_term):
query_question = str(search_term)
query_vectors = [model.encode(query_question)]
query_results = pinecone_index.query(queries=query_vectors, top_k=5)
res = query_results[0]
results_list = []
for idx, _id in enumerate(res.ids):
results_list.append({
"id": _id,
"question": df[df.qid1 == int(_id)].question1.values[0],
"score": res.scores[idx],
})
return json.dumps(results_list)
initialize_pinecone()
delete_existing_pinecone_index()
pinecone_index = create_pinecone_index()
download_data()
df = read_tsv_file()
model = create_and_apply_model()
@app.route("/")
def index():
return render_template("index.html")
@app.route("/api/search", methods=["POST", "GET"])
def search():
if request.method == "POST":
return query_pinecone(request.form.question)
if request.method == "GET":
return query_pinecone(request.args.get("question", ""))
return "Only GET and POST methods are allowed for this endpoint"Теперь давайте подробно разберем его (прим. ред. для простоты сопоставления рекомендуется открыть оригинал статьи, где строки пронумерованы).
На строках 1–11 выполняется импорт зависимостей:
dotenvдля считывания переменных среды из файла.env;flaskдля настройки веб-приложения;jsonдля работы с JSON;osтоже для получения переменных среды;pandasдля работы с датасетом;pineconeдля работы с Pinecone SDK;requestsреализует запросы к API для скачивания датасета;sentence_transformersдля модели, генерирующей векторные представления.
На строке 13 находится шаблонный код, сообщающий Flask название приложения.
На строках 15–18 определяются константы, которые будут использоваться в приложении. К ним относятся имя индекса Pinecone, каталог, в котором будут храниться данные о вопросах, имя файла с датасетом и URL, с которого этот датасет скачивается.
На строках 20–23 метод intitialize_pinecone получает ключ API из файла .env и с помощью него инициализирует Pinecone.
На строках 25–27 метод delete_existing_pinecone_index ищет в нашем экземпляре Pinecone индексы с тем же именем, что используем мы (отвечающий на вопросы чат-бот). В случае нахождения существующего индекса он его удаляет.
На строках 29–33 метод create_pinecone_index создает новый индекс, используя выбранное нами имя (отвечающий на вопросы чат-бот), метрику оценки подобия по косинусному коэффициенту и только один элемент данных.
На строках 35–41 метод download_data при необходимости скачивает датасет Quora с парами вопросов и ответов. Если этот файл уже существует в каталоге tmp, то используется он.
На строках 43–50 метод read_tsv_file считывает файл TSV, используя библиотеку pandas, и вставляет каждый ряд в датафрейм. Здесь же удаляются любые повторяющиеся вопросы, найденные в датасете.
На строках 52–57 метод create_and_apply_model использует библиотеку sentence_transformers для работы с моделью Average Word Embeddings. Далее для каждого вопроса создается векторное представление путем его кодирования с помощью модели. После полученные представления добавляются в индекс Pinecone.
Каждый из описанных методов вызывается на строках 77–82 при запуске бэкенда приложения. Теперь мы подготовлены к заключительному этапу фактического запроса индекса Pinecone на основе ввода пользователя.
На строках 84–94 определены два маршрута для приложения: один, ведущий на домашнюю страницу, и второй на конечную точку API. Домашняя страница предоставляет файл шаблона index.html вместе с JS- и CSS-ресурсами, а конечная точка обеспечивает функционал поиска для реализации запросов к индексу Pinecone.
В завершении на строках 59–75 метод query_pinecone получает ввод пользователя, преобразует его в векторное представление и запрашивает поиск в индексе Pinecone аналогичных вопросов. Этот метод вызывается при срабатывании конечной точки /api/search, что происходит всякий раз, когда пользователь отправляет новый запрос.
В качестве наглядного представления приведу схему, отражающую работу приложения:
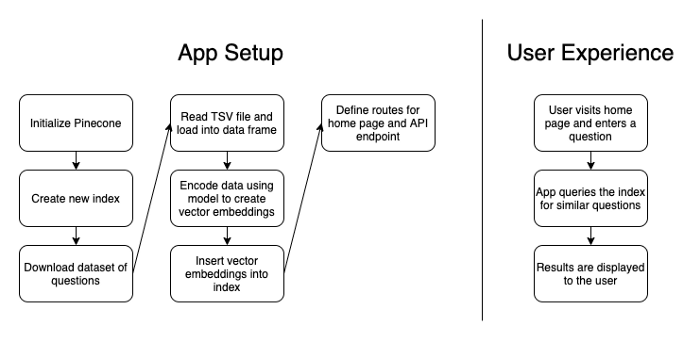
Пример сценария
Итак, как же в итоге выглядит сам пользовательский опыт?
Пользователь может зайти на сайт, ввести “How to learn Python”, найти подобные вопросы, заданные ранее, и кликать по ссылкам для просмотра этих вопросов и их ответов на Quora.
Следуя этому сценарию, пользователь может задать вопрос о том, как использовать продукт нашей компании, найти подобные вопросы, кликнуть по ссылке и перейти на страницу поддержки, где его будет ждать готовый ответ — никакого взаимодействия с оператором не потребуется.
Заключение
Вот мы и создали простое приложение для решения реальной задачи. Чтобы его улучшить, можно реализовать добавление в индекс новых вопросов-ответов после каждого задаваемого вопроса.
Еще можно использовать обратную связь клиентов, чтобы научить модель понимать, оказались ли представленные ей результаты подходящими. Как-никак, именно обратная связь позволяет модели повысить точность предлагаемых ответов.
Идея во всем этом проста: поиск подобий помогает предоставлять более качественные ответы на запросы. А Pinecone в качестве управляемого поискового сервиса упрощает перенос такой рекомендательной системы в продакшн.
Читайте также:
- Создание рекомендательного движка статей на основе ИИ/МО
- Автоматизация создания стикеров с помощью веб-скрейпинга и обработки изображений в Python
- Методы лингвистического моделирования с использованием Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи Tyler Hawkins: Build a Customer Service Chatbot Using Python, Flask, and Pinecone





