
Предыдущие части: Часть 1, Часть 2
Оптимизируем
Теперь, когда мы обнаружили проблемные области, давайте посмотрим, можем ли мы сделать сервер быстрее.
Лёгкий и быстрый способ
Давайте вернем код слушателя server.on (вместо пустой функции) и используем правильное имя для проверки условия. Наша функция etaggerвыглядит вот так:
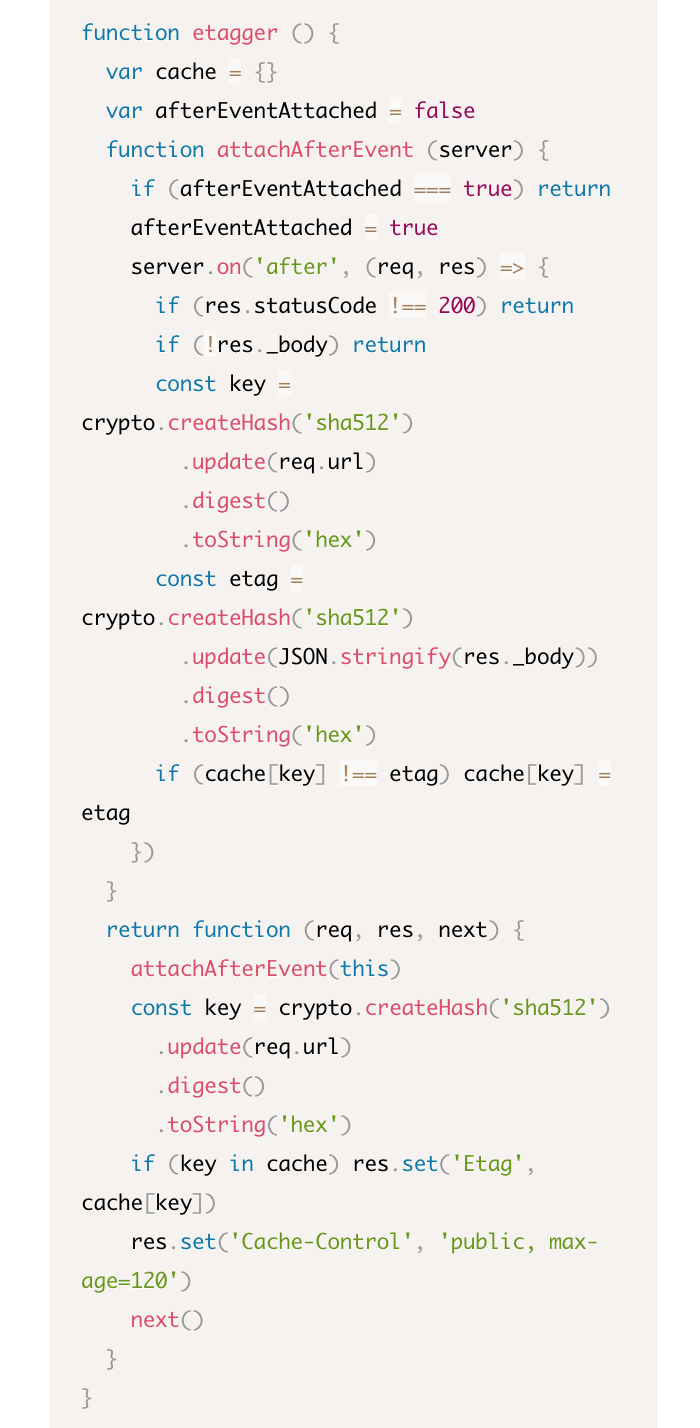
Профилируем снова, чтобы проверить наши исправления. Запустите сервер на одном терминале:

Затем профилируем с AutoCannon:

Результат должен улучшится примерно в 200 раз. (запуск теста 10сек @ http://localhost:3000/seed/v1 — 100 подключений):
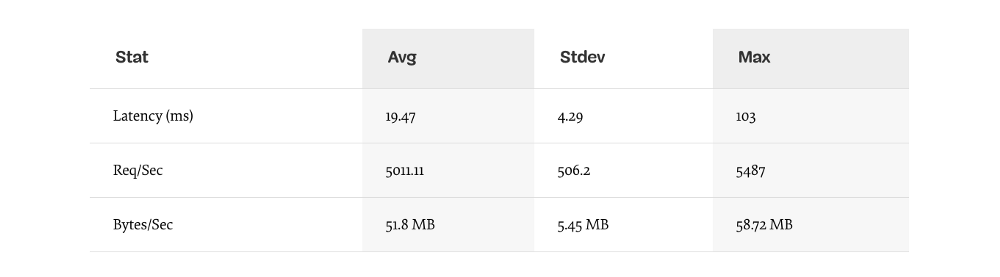
Важно сбалансировать потенциальное снижение стоимости сервера с затратами на разработку. Нам нужно определить, в контексте нашей ситуации, как далеко нам нужно зайти в оптимизации проекта. В противном случае, мы легко можем положить 80% усилий в 20% повышения скорости. Оправдывают ли это ограничения проекта?
В некоторых случаях было бы целесообразно достичь улучшения в 200 раз лёгким путём, потратив на это всего день. В других случаях мы, возможно, захотим сделать нашу реализацию настолько быстрой, насколько это возможно. Это действительно зависит от приоритетов проекта.
Один из способов контролировать расходы ресурсов — постановка цели. Например, улучшение в 10 раз или 4000 запросов в секунду. Имеет смысл исходить из потребностей бизнеса. Например, если затраты на сервер превышают бюджет на 100%, мы можем поставить цель улучшения в 2 раза.
Идём дальше
Если мы создадим новый flame graph нашего сервера, мы увидем что-то подобное:
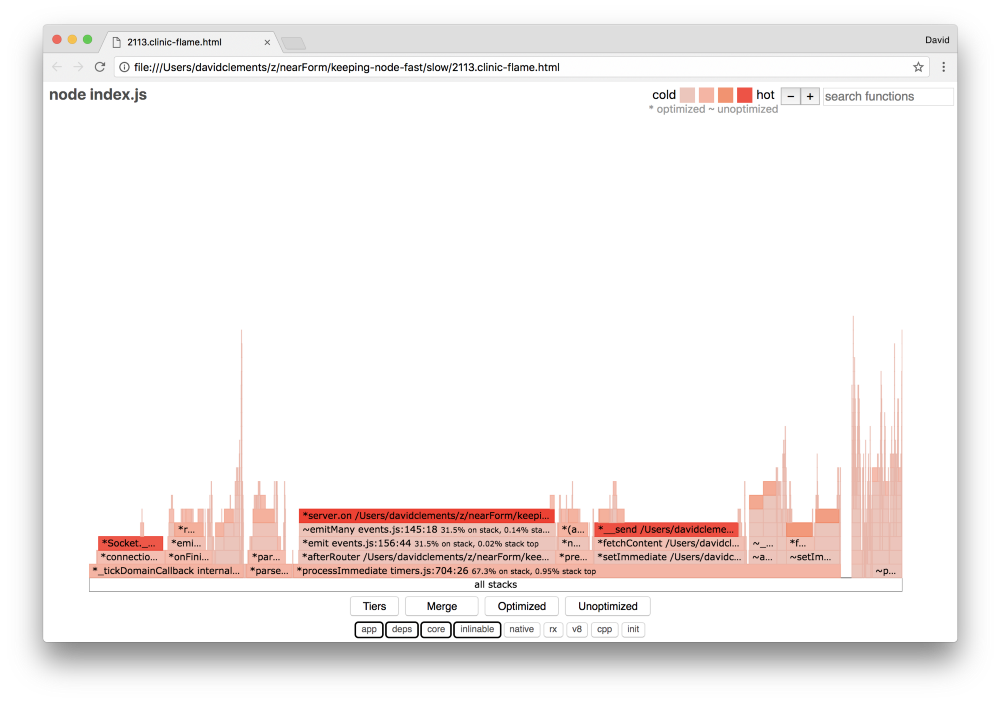
Слушатель событий по-прежнему bottleneck, он всё еще занимает одну треть процессорного времени во время профилирования (ширина составляет около трети всего графика).
Какие еще улучшения можно сделать, и стоит ли вносить изменения (учитывая связанные с ними последствия)?
В оптимизированной реализации, которая, тем не менее ограничена, могут быть достигнуты следующие характеристики (запуск теста 10сек @ http://localhost:3000/seed/v1–10 подключений):
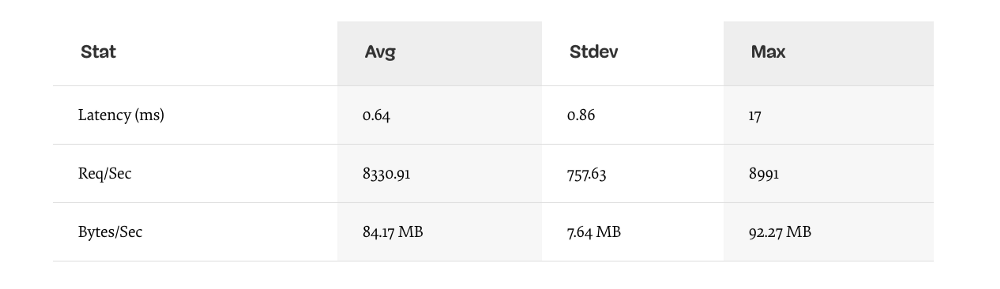
Улучшение в 1.6 раз это существенно, но оправданы ли усилия, изменения и нарушение кода, необходимые для достижения такого результата? Зависит от ситуации. Особенно по сравнению с 200-кратным улучшением оригинальной реализации после исправления одной ошибки.
Для достижения этого улучшения использовалась та же итеративная техника: профилирование, flame graph, анализ, debug, оптимизация. Код оптимизированного сервера можно найти здесь.
На последок, для достижения 8000 запросов/сек :
- Создайте строку JSON напрямую вместо создания объекта и сериализации;
- Используйте что-то уникальное в контенте, чтобы определить его Etag, вместо создания хэша;
- Не хэшируйте URL, используйте его непосредственно как ключ.
Эти изменения немного более значимы, немного более разрушительны для кода и делают etaggermiddleware немного менее гибким. Потому что это накладывает нагрузку на маршрут, чтобы предоставить значения Etag. Но мы получили дополнительные 3000 запросов в секунду на профилируемой машине.
Давайте взглянем на flame graph после последних улучшений:
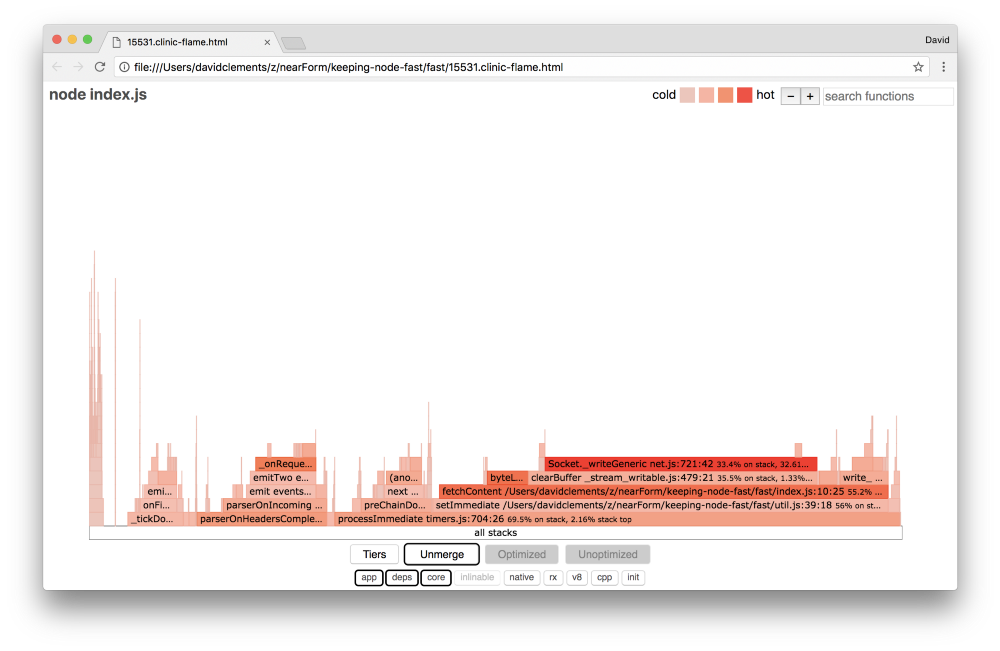
Самая горячая часть flame graph указывает на модуль net, а это часть ядра Node. Это идеально.
Предотвращение проблем с производительностью
В заключение приведу несколько рекомендаций по предотвращению проблем с производительностью перед развертыванием.
Используйте инструменты для отслеживания проблем с производительностью на этапе разработки. Они помогут отфильтровать баги, прежде чем они попадут в продакшн. Рекомендую использовать инструменты AutoCannon и Clinic (или их эквиваленты) в повседневной разработке.
Если покупаете фреймворк, разузнайте о его политике производительности. Если производительность не самая сильная сторона фреймворка, тогда важно проверить, соответствует ли он инфраструктурным практикам и бизнес-целям. Например, команда Restify явно (начиная с релиза седьмой версии) вложилась в повышение производительности библиотеки. Впрочем, если низкая стоимость и высокая скорость являются абсолютным приоритетом, рассмотрите Fastify. Его производительность на 17% выше, измерения проводил участник Restify.
Следите за другими широко известными библиотеками, особенно изучайте логи. По мере устранения багов разработчики могут вести дополнительный лог чтобы помочь исправлять проблемы в будущем. Если используется плохо работающий логгер, он может снизить производительность с течением времени, как в истории с лягушкой в кипятке. Логгер pino — самым быстрый логгер json с переносом строки, доступный для Node.js.
Наконец, всегда помните, что Event Loop относится к общим ресурсам. Node.js сервер, в конечном счете, ограничен самой медленной логикой в самом нагруженном пути.
Перевод статьи: David Mark Clements Keeping Node.js Fast: Tools, Techniques, And Tips For Making High-Performance Node.js Servers





