
1. Теорема Брюера
CAP (Consistency, Availability, Partition tolerance) — теорема о том, что для распределенных вычислений невозможно обеспечить все три свойства: согласованность данных, доступность и устойчивость к разделению.
Термин CAP, относящийся к проектированию распределенных систем, также называется теоремой Брюера. Теорема утверждает, что распределенное хранилище данных не может одновременно обеспечить более двух из трех изображенных на схеме свойств:
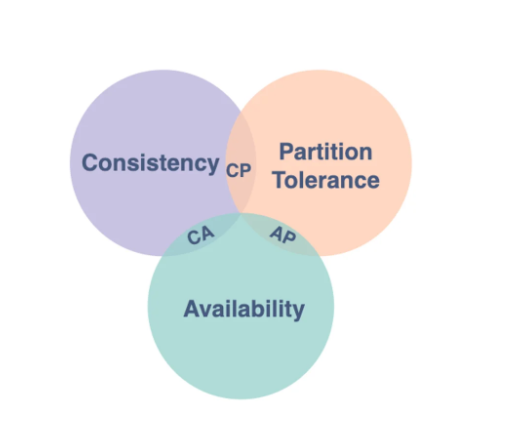
Теперь давайте подробнее проанализируем нюансы каждого из трех свойств распределенной системы согласно CAP:
- Согласованность.
Каждый процесс чтения получает последнюю запись или ошибку, соответственно, когда в системе запущено несколько параллельных процессов записи и чтения, то каждое чтение всегда возвращает последнюю запись, сделанную в системе. - Доступность.
Принцип доступности в распределенной системе гарантирует, что система всегда остается работоспособной. Каждый запрос получает ответ без ошибок, независимо от индивидуального состояния узла. Впрочем, принцип не гарантирует, что ответ содержит самую последнюю запись (смотрите предыдущий пункт “Согласованность”). - Устойчивость к разделению.
Распределенная система продолжает работу, даже когда отдельный узел не отвечает. Вышедший из строя узел подкрепляется вторичным узлом, поэтому вторичный узел заменяет первичный во время сбоев, а система становится отказоустойчивой. Хотя некоторые сообщения все-таки могут выходить из строя.
Напоминаем, что распределенная система обеспечивает не больше двух свойств из перечисленных трех.
Например, MongoDB — это CP-хранилище данных, соответственно, обеспечиваются согласованность и разделение.
MongoDB — это одномастерная структура. MongoDB допускает один первичный узел, который получает все операции записи. Когда первичный узел вне доступа, то вторичный узел выбирается в качестве нового первичного узла. Поскольку клиенты не отправляют запросы на запись в течение интервала смены ролей, данные остаются согласованными по всей сети.
Следующий пример, Cassandra — это AP-хранилище данных, где обеспечиваются доступность и устойчивость к разделению, но отсутствует постоянная согласованность.
Следовательно, примеры показывают, что только два свойства CAP гарантированы.
2. Акроним требований ACID
ACID (Atomicity, Consistency, Isolation, Durability) — описание требований к СУБД, системе управления базами данных: атомарность, согласованность, изолированность и прочность.
Следование требованиям ACID обеспечивает надежную и предсказуемую работу транзакционных систем.
- Атомарность — все изменения данных выполняются как единая операция, от начала и до конца.
- Согласованность — после нормального завершения работы (EOT, End of transaction) транзакция фиксирует допустимые результаты.
- Изолированность — параллельные транзакции не должны влиять друг на друга во время выполнения.
- Прочность — пользователь может быть уверен, что после оповещение об успешной транзакции ничто не отменит результат.
- Транзакции получают доступ к данным через операции чтения и записи.
- Для обеспечения согласованности данных до и после транзакции соблюдаются свойства ACID.
3. Управление транзакциями
Базы данных SQL идеально подходят для обработки транзакций, поскольку они обеспечивают все свойства ACID.
Тем не менее, NoSQL-хранилища в состоянии справиться с транзакциями, однако придется самостоятельно написать дополнительную логику управления транзакциями в отдельном приложении.
Некоторые базы данных NoSQL, такие как Neo4j и MarkLogic, обеспечивают свойства ACID. Однако они все равно не так надежны, как реляционные базы данных.
В целом, распределенные базы данных NoSQL характеризуются более легкой семантикой транзакций, чем реляционные базы данных, но все же и они предоставляют инструменты для атомарных операций на определенном уровне.
По мере прочтения руководства вы поймете причину, по которой транзакции легко выполняются в реляционных хранилищах, но представляют сложность в распределенных. Конечно, ведь SQL изначально разрабатывался под транзакции!
В реляционных базах данных все связанные данные хранятся в одном узле или на одной машине. В то же время NoSQL позволяет организовать несколько узлов, обрабатывающих связанные данные (горизонтальное масштабирование).
Например, в случае применения SQL все связанные данные для таблицы размещены на одной машине, однако для NoSQL решений характерно горизонтальное разделение. Следовательно, в распределенных базах данных связанные данные находятся на нескольких узлах. Поэтому транзакции в NoSQL затруднены.
Большинство инструментов NoSQL ослабляют критерии согласованности операций для обеспечения отказоустойчивости и масштабирования. Подобные решения усложняют реализацию транзакций согласно требованиям ACID.
Для баз данных NoSQL реализовывается согласованность в конечном счете, соответственно, в конечном итоге все обращения к элементу вернут последнее обновленное значение. Но такой согласованности недостаточно для транзакционных приложений, например, для личного кабинета онлайн-банкинга.
Банковский и финансовый сектора предпочитают SQL из-за целостности данных и возможности выполнения сложных запросов.
В последних обновлениях дистрибутивов MySQL реализовано разбиение на разделы, однако система становится сложной и трудной в управлении.
4. Достоинства и недостатки схемы
Базы данных SQL следуют подходу “schema first”, “сначала схема”.
При подходе “сначала схема” все столбцы относятся к одному из предопределенных типов, например, string, timestamp, integer.
NoSQL не содержит схем. Таким образом, когда вы вставляете в документ любые данные, то среди них могут указываться вперемешку строки, целые числа и временные метки, например:
[{“amount”: 9}, {“amount”:”hello”}, {“amout”: 282827199273}]При возникновении какой-либо ошибки в наборе данных для распределенного хранилища, поиск и устранение неисправности будет гораздо тяжелее, чем при хранении данных в реляционном хранилище. Ошибки в моделировании данных или несоответствия в данных стоят очень дорого.
Веб-фреймворки реализовывают собственные модели и валидации перед вставкой данных в базу. Например, Express.js навязывает схему поверх вашего приложения с распределенным хранилищем данных. Таким образом, вероятность ошибки очень мала.
Но не стоит забывать, что шаблон схемы в SQL также заботится о проверке данных на уровне BD и возвращает вам соответствующую ошибку при запросе.
5. Нормализация
Нормализацией называется техника проектирования баз данных, устраняющая избыточность данных и аномалии при операциях вставки, обновления, удаления.
Определено 5 правил нормализации: 1NF, 2NF, 3NF, 4NF, 5NF.
Системы управления реляционными базами данных, RDBMS SQL, по умолчанию поддерживают нормализацию и позволяют управлять данными отдельно, в то время как распределенные СУБД NoSQL не обеспечивают встроенную поддержку нормализации, следовательно, они требуют более тщательного поддержания целостности от клиентских приложений.
6. Вертикальное и горизонтальное масштабирование
Масштабированием базы данных называется разделение данных между несколькими узлами.
Горизонтальное масштабирование означает, что вы масштабируете базу данных путем добавления новых машин в пул ресурсов.
Вертикальное масштабирование означает, что вы добавляете больше вычислительной мощности (CPU или RAM) к существующей машине.
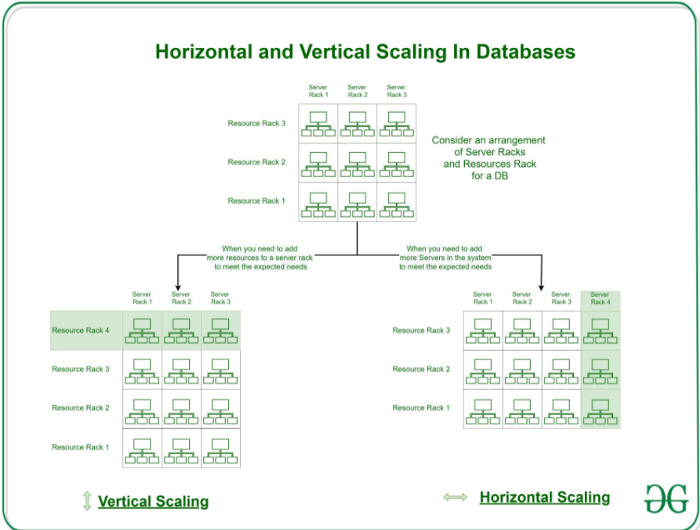
Для SQL СУБД применяется вертикальное масштабирование, а для NoSQL СУБД — горизонтальное.
В SQL горизонтальное масштабирование невозможно, оно стоит слишком много усилий как раз из-за управления транзакциями, ключевой особенности реляционных баз данных.
В то же время транзакцию или согласованность нельзя назвать основными характеристиками распределенных баз данных, поэтому горизонтальное масштабирование легко осуществляется через согласованное хеширование.
7. Запросы и доступ к данным
Рассмотрим пример: получение всех заказов с указанием данных конкретного пользователя.
- Операция в SQL.
Две SQL-таблицы — пользователиusersи заказыorders.
Запрос:select userdetails,order from user,orders where user.id = orders.user_id. Выполняется один запрос. - Операция в NoSQL.
Получить заказы на основеuserid, затем получить данные о пользователе на основеuserid. Выполняется два запроса.
Легче всего управлять реляционными хранилищами тогда, когда оперировать приходится связанными между собой данными, распределенными по таблицам. Следовательно, при работе со связанными данными, когда нужно произвести несколько операций объединения, — пригодится SQL, потому что на SQL удобно писать сложные запросы, например, при помощи оператора JOIN, да и вычисления сложных запросов выполняется быстро.
В свою очередь, NoSQL быстрее обрабатывает простые запросы, такие как get, insert, filtering, order (получение данных, вставка, фильтрация и упорядочивание). В NoSQL становится трудно выполнять запросы и управлять соединениями только тогда, когда предоставлены связанные между собой наборы данных, хранящиеся в нескольких коллекциях.
К вашему сведению, начиная с MongoDB версии 3.2 доступен $lookup для выполнения операций между двумя коллекциями.
8. Архивация данных
Архивация означает возможность хранения огромных объемов исторических данных, с получением доступа для аналитики.
Чаще всего при архивации данных применяются NoSQL хранилища, поскольку известно, что не потребуются нормализация или соответствие требованиям ACID.
Выбор СУБД для анализа данных зависит от множества факторов, например, от типа данных, которые вы анализируете, от их количества и необходимой скорости доступа.
Например, реляционная база данных лучше всего подходит для приложений вроде анализа поведения пользователей. Если данные помещаются в электронную таблицу, то все еще лучше выбрать реляционную базу данных, такую как Postgres или BigQuery. Выбор объясняется тем, что реляционные СУБД хорошо анализируют данные в строках и столбцах.
Для полуструктурированных данных, таких как статистика социальных сетей, тексты или географические данные, то есть, в случае большого объема операций текстового анализа или обработки изображений, лучше всего подходят распределенные базы данных, такие как MongoDB или CouchDB.
9. Правда, что NoSQL быстрее SQL?
Вы где-то слышали, что NoSQL быстрее? Если да, то это не так.
Единственная причина, по которой у людей сложилось общее заблуждение, что SQL работает медленнее, заключается в том, что они не пытаются понять причину.
Схемы SQL способны выполнять сложные запросы, операции JOIN со множеством разных таблиц. В то время как в NoSQL совсем нет возможности выполнить сложный запрос.
NoSQL быстро выполняет простые запросы к определенной таблице. Поэтому люди говорят, что NoSQL быстрее только из-за потенциальной возможности выполнения сложных запросов на SQL-сервере, в отличии от NoSQL.
Лучший подход, чтобы понять, какая база данных быстрее, полностью зависит от конкретного бизнеса. Какую CRUD-операцию вы хотите выполнить? Какого вендора или какую реализацию вы выбираете в качестве типа схемы? Для чего вам необходимо увеличить скорость выполнения операций? А как насчет кластеров, разделов, архивации, критичности требований?
Приложения на основе NoSQL предоставляют весь доступ к данным и модификациям, через операции на основе первичных ключей, чтобы оптимизировать работу с хранилищем NoSQL K/V.
Преимущества баз данных SQL в том, что они более производительны при работе со сложными запросами.
10. Недостатки реляционных и распределенных баз данных
Рассмотрим краткую сводку главных недостатков обеих типов СУБД
- Недостатки SQL базы данных:
- Реляционные хранилища данных нельзя горизонтально масштабировать.
- SQL базы данных — не отказоустойчивая система.
- Схема определена заранее. Модификация базы данных потребует усилий.
- Не рекомендуется для приложений, ориентированных на хранение петабайтов данных.
- Недостатки NoSQL базы данных:
- Отсутствие управления транзакциями и поддержки ACID.
- Нет предопределенной схемы. Следовательно, нет и валидации на уровне базы данных.
- Транзакциями очень сложно управлять.
- Невозможно выполнить сложную операцию объединения таблиц.
Выводы
Быстрый выбор базы данных для конкретного проекта, итоговая сводка руководства:
- Выбирайте SQL для управления транзакциями.
- Выбирайте SQL, если данные из хранилища можно уместить на одной машине без необходимости в расширении системы.
- Выбирайте SQL, когда целостность данных считается ключевой характеристикой, а вы хотите, чтобы программное обеспечение соответствовало требованиям ACID.
- Выбирайте SQL для управления связанными данными со сложными соединениями. Сложные запросы легче пишутся и быстрее выполняются на SQL.
- Выбирайте NoSQL, если нужно хранить огромное количество данных, и вы знаете, что один узел не справится с их обработкой в полном объеме.
- Выбирайте NoSQL при работе с неструктурированными и не связанными между собой данными.
- Выбирайте NoSQL, если вы часто модифицируете БД и не уверены в постоянстве схемы.
- Выбирайте NoSQL, когда большинство запросов — операции фильтрации, группировки или упорядочивания; то есть, когда нужны только простые запросы.
- Выбирайте NoSQL для графоподобных данных и приложений, работающих с данными в реальном времени, таких как Интернет вещей или видеоигры.
Примечание: оптимальное решение — это совмещение баз данных с применением лучших свойств как распределенных, так и реляционных СУБД.
Читайте также:
Читайте нас в Telegram, VK и Дзен
Перевод статьи Vivek Singh: SQL or NoSQL — Which one to choose?





