
Я расскажу о том, как создал 42 стикера для Telegram из постеров, взятых в интернет-магазине. Там продаются различные постеры с забавными надписями, а вот подобных стикеров не существует. Научимся создавать их самостоятельно!
Единственная проблема заключается в том, что генерация нескольких десятков изображений (в данном случае — 42) занимает слишком много времени. Ведь только для создания одного стикера потребуется совершить несколько операций:
- загрузить картинку с веб-страницы;
- отделить буквы от фона в фотошопе;
- сохранить изображение в разрешении, предусмотренном для стикеров в Telegram.
Чтобы сократить время создания стикеров, попробуем автоматизировать процесс.
Итак, вот план.
- Веб-скрейпинг — извлечение нужных картинок из интернет-магазина.
- Автоматическое отделение букв от фона, удаление теней с фона, придание картинкам вида сканов.
Загрузка картинок
Начнем с создания списка необходимых ссылок. Каждая из них будет вести на страницу отдельного постера. Это позволит загружать картинки высокого разрешения. Разрешение картинок в главной галерее слишком низкое.
Для этого сохраним все ссылки на картинки в галерее.
import requests
from bs4 import BeautifulSoup
import urllib.request
url = 'https://demonpress.ecwid.com/%D0%9F%D0%BB%D0%B0%D0%BA%D0%B0%D1%82%D1%8B-c26701164'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36'}
text = requests.get(url, headers=headers)
soup = BeautifulSoup(text.content, 'html.parser')
urls = []
for i in soup.find_all('a', attrs = {"class": "grid-product__image"}):
urls += [i['href']]Галерея разделена на четыре страницы с 15 постерами на каждой. Чтобы перейти на следующую страницу, достаточно добавить ?offset=15, 30 или 45. Это позволит парсить оставшиеся ссылки.
for i in ['15','30','45']:
url_next = url + '?offset=' + i
text = requests.get(url_next, headers=headers)
soup = BeautifulSoup(text.content, 'html.parser')
for i in soup.find_all('a', attrs = {"class": "grid-product__image"}):
urls += [i['href']]Теперь поочередно переходим по каждой ссылке, чтобы загрузить фото высокого разрешения со страниц товаров.
for url in urls:
text = requests.get(url, headers=headers)
soup = BeautifulSoup(text.content, 'html.parser')
for j in soup.find_all('img', {'class':'details-gallery__picture details-gallery__photoswipe-index-0'}):
urllib.request.urlretrieve(j['src'], j['title'].replace('/','').replace('*','').replace('?','')+'.jpg')Поскольку картинки названы в соответствии с текстом на постерах, нужно удалить из названий недопустимые символы, такие как /, ? и *.
Обработка изображений
К сожалению, в интернет-магазине представлены фото постеров, а не сканы. Поэтому мы не можем использовать их в том виде, как они есть. Вот пример того, как выглядит типичная картинка:

Постер на картинке освещен сбоку. Благодаря этому текстура бумаги хорошо видна. В некоторых случаях сложно отделить буквы с помощью порога яркости, поскольку при определенных обстоятельствах буквы могут быть ярче, чем некоторые части фона. В данном случае этот подход не является универсальным.
Чтобы реализовать метод, подходящий для всех возможных условий освещенности, воспользуемся тем, что все постеры содержат большие красные буквы на белом или сером фоне. Каждый пиксель цифрового изображения представляет собой вектор из трех чисел. Серый пиксель, независимо от того, яркий он или тусклый, состоит из трех одинаковых чисел, в то время как цветовой пиксель будет содержать числа, отличающиеся друг от друга.
Поэтому гораздо эффективнее отделять фон на основе порогового стандартного отклонения, а не яркости. Методом проб и ошибок было выяснено, что хорошим значением для такого порога будет 30.
После определения пикселя как части фона, установим его значение (245, 245, 245). Для пикселей, которые являются частью букв, устанавливаем другое значение (200, 17, 11). Фон не получится идеально белым, но будет смотреться отлично, поскольку идеально белой бумаги не существует, а набор стикеров должен имитировать постеры.
def remove_bg(input_img: np.ndarray) -> np.ndarray:
img = input_img.copy()
for i in range(0, img.shape[0]):
for j in range(0, img.shape[1]):
if img[i][j].std() < 30:
img[i][j] = [245, 245, 245]
else:
img[i][j] = img[i][j] + 0.5*([200, 17, 11] - img[i][j])
return imgВот результат:

Остался последний шаг — изменить размер изображения так, чтобы самая большая длина не превышала 512. Чтобы изменить размер всех изображений и сохранить их как файлы png, воспользуемся библиотекой PIL.
from PIL import Image
files = []
for i in os.listdir('.'):
if i[-4::] == '.jpg':
files += [i]
for file in files:
img = mpimg.imread(file).copy()
img = remove_bg(img)
x = int(512)
y = int(512 * img.shape[1]/img.shape[0])
img = Image.fromarray((resize(img, (x, y))*255).astype(np.uint8))
img.save(f'result/{file[0:-4]}', 'png')
print('Done!')Вот результат:
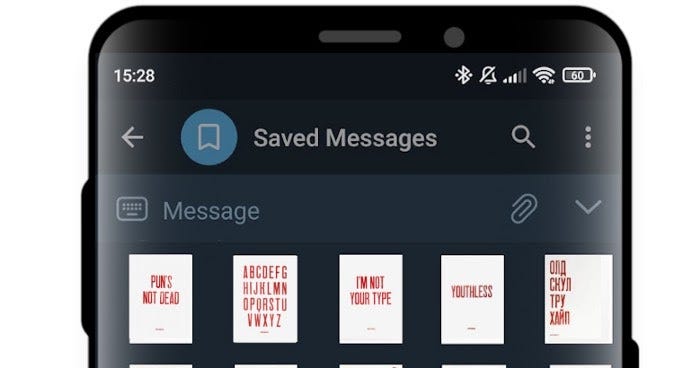
И ссылка на GitHub для тех, кому интересно.
Читайте также:
- Сравнение производительности ввода/вывода: C, C++, Rust, Golang, Java и Python
- 12 проверенных способов оптимизации функций Python
- Стилизация фотографий под мультфильмы с помощью Python
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Danil Vityazev: Automating Sticker Generation With Web Scraping and Image Processing in Python





