
Всем дата-сайентистам хорошо известно: данные никогда не будут такими, какими вы хотите их видеть. Вы можете получить сколько-нибудь упорядоченный спредшит или более-менее точные табличные данные, но в любом случае вам придется проводить очистку, прежде чем перейти к анализу.
Поэтому очень важно научиться переходить от одного формата данных к другому. Иногда это исключительно вопрос читабельности и простоты интерпретации. В других случаях программный пакет или алгоритм, который вы пытаетесь использовать, просто не заработает, пока данные не будут отформатированы определенным образом. Как бы там ни было, этим навыком нужно владеть всем дата-сайентистам.
Предлагаю рассмотреть два распространенных формата данных: длинный и широкий. Обе версии — часто используемые парадигмы в науке о данных, поэтому стоит ознакомиться с ними. Разберем несколько примеров, чтобы понять, как именно выглядит каждый формат данных, а затем посмотрим, как конвертировать один формат в другой с помощью Python (и, в частности, Pandas).
Длинноформатные и широкоформатные данные
Начнем непосредственно с определений.
- Широкоформатные данные включают одну строку для каждого возможного значения независимой переменной, а все зависимые переменные записаны в метках столбцов. Таким образом, метка в каждой строке (для независимой переменной) будет уникальной.
- Длинноформатные данные включают одну строку для каждого наблюдения, и каждая зависимая переменная записывается как новое значение в нескольких строках. Следовательно, значения независимой переменной повторяются в строках.
Что же это значит? Проще будет понять на конкретном примере. Допустим, у нас есть набор данных о студентах: их оценочные баллы (scores) за промежуточный экзамен (midterm exam), итоговый экзамен (final exam) и учебный проект (class project). В широком формате эти данные будут выглядеть следующим образом:
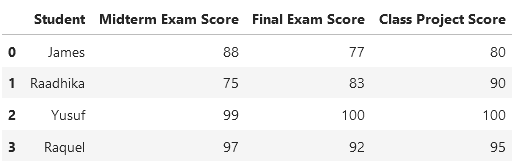
Здесь каждый студент — независимая переменная, а все оценочные баллы — соответствующие зависимые переменные (поскольку оценка за конкретный экзамен или проект зависит от студента). Как видите, значение Student уникально для каждой строки, как и следовало ожидать от широкоформатных данных.
Теперь посмотрим на те же данные, но в длинном формате:
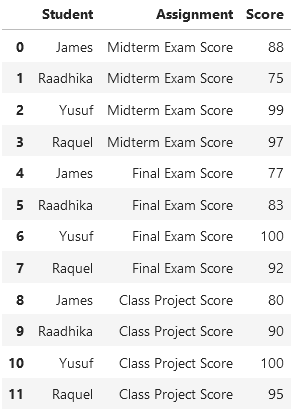
На этот раз у нас есть строка для каждого наблюдения. В данном случае наблюдение соответствует оценке за определенное задание (Assignment). В приведенной выше широкоформатной версии этих данных мы записали несколько наблюдений (оценок) в одну строку, тогда как здесь каждая строка имеет свою оценку.
Кроме того, значения независимой переменной Student повторяются в этом формате данных, что опять же соответствует нашим ожиданиям.
Чуть позже поговорим о том, почему для нас важно разделение этих форматов. Но сначала вкратце рассмотрим, как с помощью Pandas можно конвертировать данные из одного формата в другой.
Конвертация широкоформатных данных в длинноформатные: функция Melt
Снова обратимся к данным в широком формате, приведенным выше. На этот раз дадим датафрейму имя student_data:
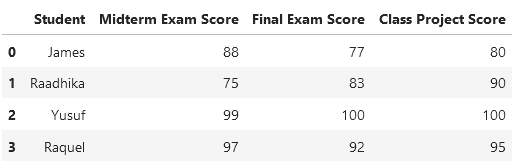
Чтобы преобразовать student_data в длинный формат, используем следующую строку кода:
student_data.melt('Student', var_name='Assignment', value_name='Score')
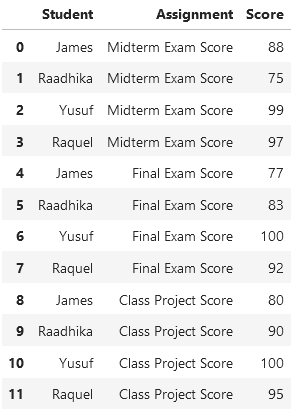
Вот пошаговое объяснение.
- Функция
meltпредназначена для преобразования широкоформатных данных в длинноформатные. - Параметр
var_nameуказывает на название второго столбца, который будет содержать соответствующие зависимые переменные. - Параметр
value_nameопределяет название третьего столбца, который будет содержать наблюдаемые индивидуальные значения (в данном случае баллы).
Итак, у нас есть данные в длинном формате. Но что, если по какой-то причине потребуется вернуться к широкому формату?
Конвертация длинноформатных данных в широкоформатные: функция Pivot
Итак, на этот раз начинаем с версии данных в длинном формате. Дадим ей имя student_data_long. Следующая строка кода преобразует ее обратно в исходный формат:
student_data_long.pivot(index='Student', columns='Assignment', values='Score')
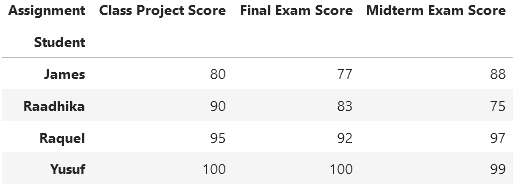
За исключением слегка обновленных меток (pivot показывает общую метку столбца 'Assignment'), это именно те данные, с которых мы начинали выше.
Вот пошаговое объяснение.
- Функция
pivotпредназначена для преобразования широкоформатных данных в длинноформатные. - Параметр
indexуказывает, значения каких столбцов мы сделаем уникальными строками (т.е. независимой переменной). - Параметр
columnsуказывает, уникальные значения какого столбца (в длинном формате) станут уникальными метками столбцов. - Параметр
valuesуказывает на то, метки каких столбцов будут представлять собой фактические данные в широком формате.
Зачем это нужно?
В заключение обратим внимание на то, что, хотя на первый взгляд все вышесказанное может показаться несущественным, на самом деле это очень полезный навык. Вы не раз обнаружите, что наличие данных в определенном формате значительно облегчает жизнь.
Проиллюстрирую эту мысль примером из личной практики. Мне часто приходится визуализировать данные на Python. Использование при этом моего любимого модуля Altair привело к неожиданной проблеме: большинство спредшитов, как правило, имеют широкий формат, а особенности Altair значительно проще использовать в длинном формате.
В начале этого года я довольно долго трудился над созданием одной визуализации. Посоветовавшись с коллегами на Stack Overflow, я обнаружил, что нужно было лишь преобразовать данные в длинный формат.
Возможно, вы не работаете в сфере визуализации, но если читаете эту статью, то, скорее всего, имеете дело с данными. Поэтому вам необходимо уметь преобразовывать их. Конвертация данных из одного формата в другой — полезный навык, который должен быть в арсенале каждого дата-сайентиста.
Читайте также:
- 9 первоклассных функций Pandas Python для работы с данными
- Четыре метода, которые повысят качество работы с Pandas
- Пакетная обработка 22 ГБ данных о транзакциях с помощью Pandas
Читайте нас в Telegram, VK и Дзен
Перевод статьи Murtaza Ali: How to Use Pandas to Get Your Data in the Format You Need





