
Искусственный интеллект сыграл колоссальную роль в преодолении разрыва между возможностями людей и машин. Как исследователи, так и энтузиасты работают над многочисленными аспектами этой области, добиваясь удивительных результатов. Одним из таких аспектов является компьютерное зрение.
Повестка дня этого направления сводится к тому, чтобы обучить машины видеть и воспринимать мир так, как это делают люди, чтобы использовать полученную информацию для решения таких задач, как:
- распознавание образов и видеоизображений;
- анализ и классификация изображений;
- воссоздание мультимедиа;
- моделирование рекомендательных систем;
- обработка естественного языка.
Достижениям в области компьютерного зрения как технологии глубокого обучения мы обязаны, прежде всего, специальному алгоритму — сверточной нейронной сети.
Вступление
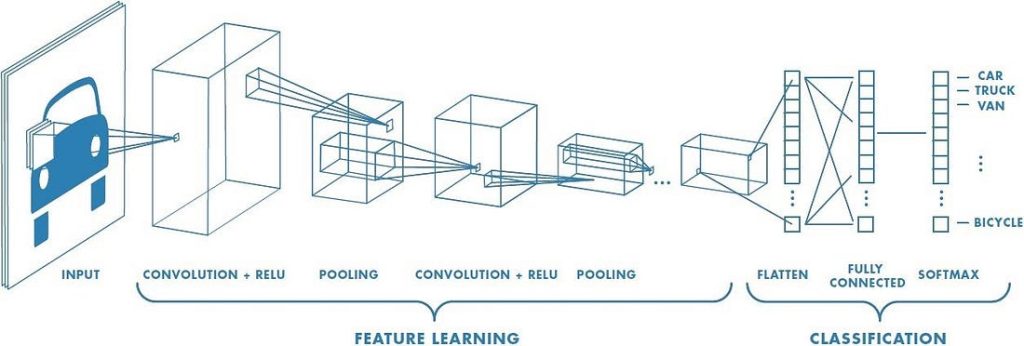
Сверточная нейронная сеть (ConvNet / CNN) — это алгоритм глубокого обучения, который способен воспринимать входное изображение, определять существенность различных его аспектов / элементов (усваиваемых весов и смещений) и уметь отличать одни данные от других. По сравнению с другими алгоритмами классификации, ConvNet требует гораздо меньше предварительной обработки. Если в примитивных технологиях системы фильтрации разрабатываются вручную, нейронные сети, при должном обучении, успешно овладевают фильтрационными/характеристическими программами.
Архитектура ConvNet аналогична структуре связей нейронов человеческого мозга. За основу ее была принята организация зрительной зоны коры головного мозга. Отдельные нейроны реагируют на стимулы только в ограниченной области зрительной зоны, известной как рецептивное поле. Ряд таких полей накладываются друг на друга, охватывая всю визуальную область.
В чем преимущество ConvNet перед нейросетью прямого распространения?
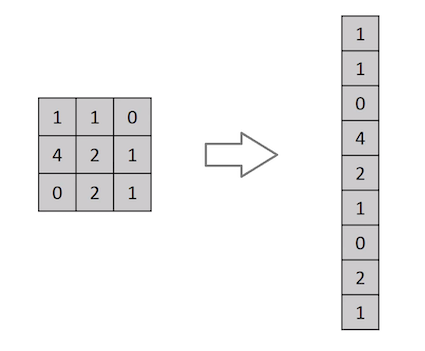
Изображение — это не что иное, как матрица значений пикселей, верно? Так почему бы просто не выполнить сведение изображения (например, сведение матрицы изображения 3×3 к вектору 9×1) и не передать его на многоуровневый классифицирующий персептрон? Э-э-э… все не так просто.
При таком подходе можно получить средний коэффициент точности лишь в случаях с чрезвычайно простыми двоичными изображениями. Однако, когда дело дойдет до сложных изображений, имеющих зависимости от пикселей на всех участках, даже на среднюю оценку точности нельзя будет рассчитывать.
ConvNet способна успешно захватывать пространственные и временные зависимости в изображении с помощью соответствующих фильтров. Специальная ее архитектура обеспечивает оптимальную адаптацию к набору данных изображений за счет сокращения числа задействованных параметров и возможности повторного использования весов. Другими словами, такая сеть лучше приспособлена к обучению распознания сложных изображений.
Входное изображение
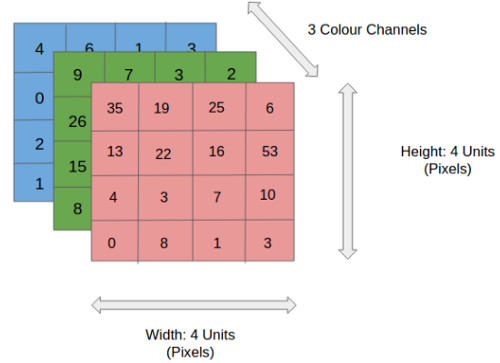
На рисунке вы видите RGB-изображение, которое разделено тремя цветовыми плоскостями — красной, зеленой и синей. Помимо RGB, возможны и другие цветовые модели, например полутоновая (с оттенками серого), HSV (цвет-насыщенность-значение), CMYK (бирюзово-пурпурно-желто-черная).
Можете себе представить, насколько интенсивными должны быть вычисления, если изображение будет достигать больших размеров, скажем, 8 Кб (7680 × 4320). Роль ConvNet заключается в том, чтобы привести изображения в форму, которую легче обрабатывать без потери характеристик, имеющих решающее значение для точного прогноза. Это важно, если необходимо разработать архитектуру сети, которая не только хорошо обучается распознавать признаки, но и масштабируется для массивных наборов данных.
Слой свертки — ядро
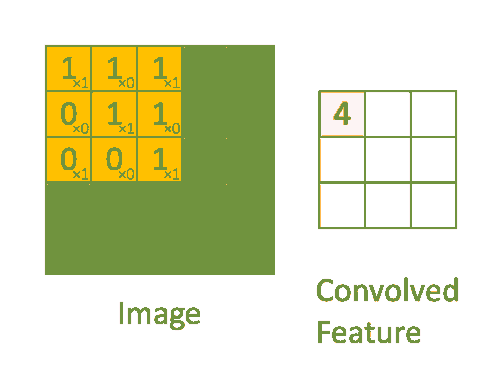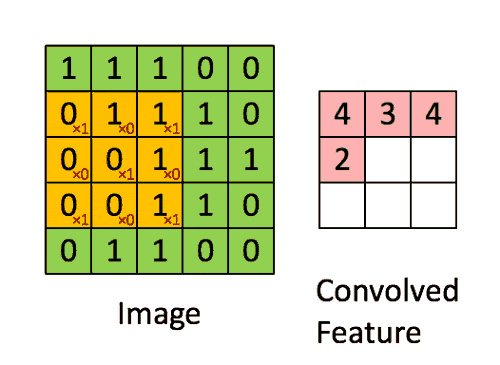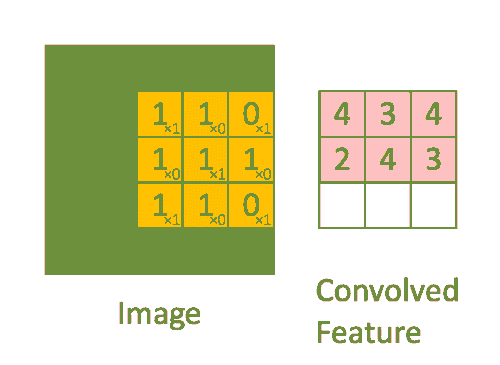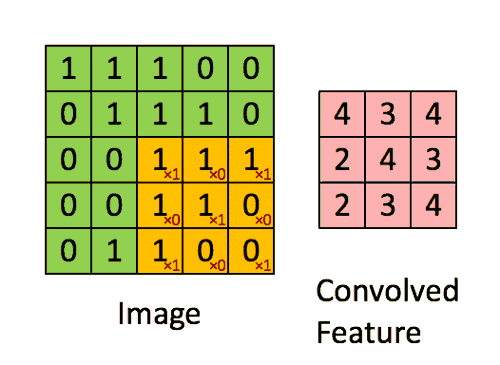
Размеры изображения = 5 (высота) х 5 (ширина) х 1 (количество каналов, например RGB)
На приведенной выше гифке видно, что зеленая секция напоминает наше входное изображение 5x5x1, I. Элемент, участвующий в выполнении операции свертки в первой части сверточного слоя, называется ядром /фильтром, K, представленным желтым цветом. Мы выбрали K в качестве матрицы 3x3x1.
Kernel/Filter, K =
1 0 1
0 1 0
1 0 1
Ядро смещается 9 раз, поскольку длина шага = 1 (бесшаговая свертка), и каждый раз выполняется операция матричного умножения между K и фрагментом P изображения, над которым находится ядро.
Фильтр перемещается вправо с определенным значением шага, пока не проанализирует всю ширину. Двигаясь дальше, он переходит к началу (слева) изображения с тем же значением шага и повторяет процесс до тех пор, пока не будет пройдено все изображение.
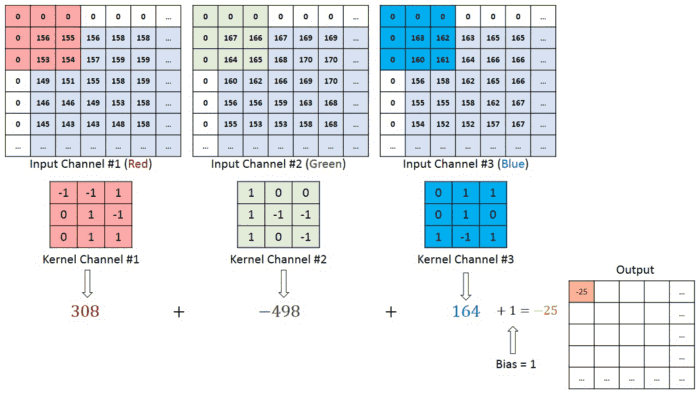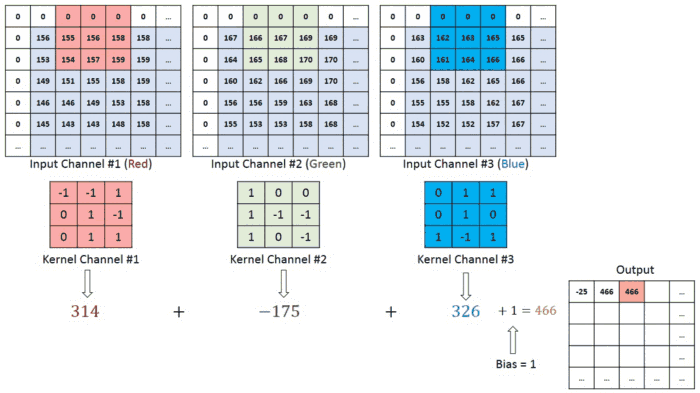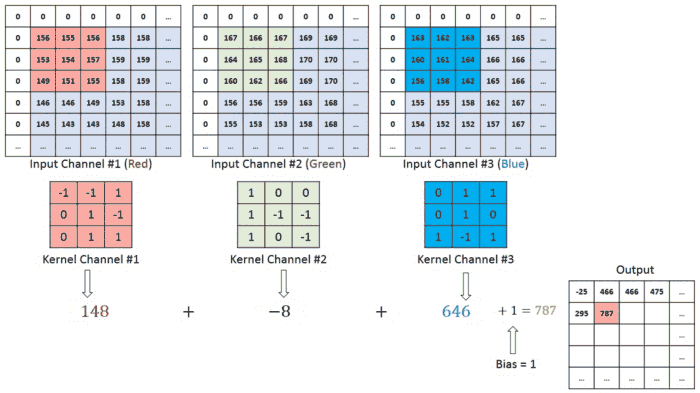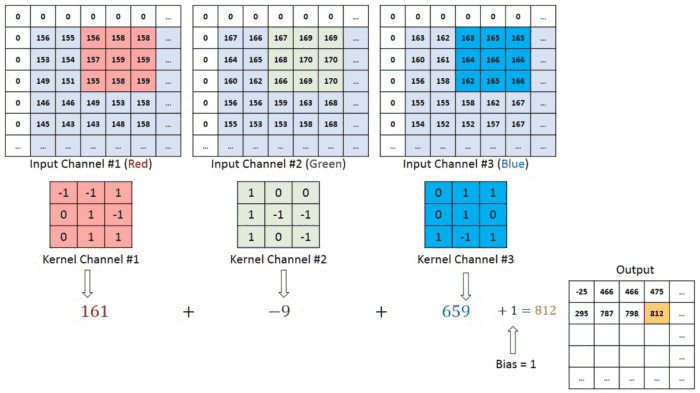
В случае изображения с несколькими каналами (например, RGB) ядро имеет ту же глубину, что и входное изображение. Матричное умножение выполняется между Kn и In стека ([K1, I1]; [K2, I2]; [K3, I3]), и все результаты суммируются со смещением, что приводит к выводу сжатого сверточного объекта с каналами одной глубины.
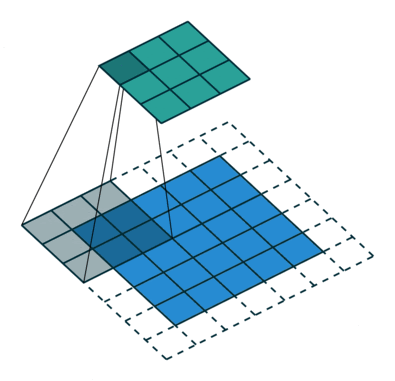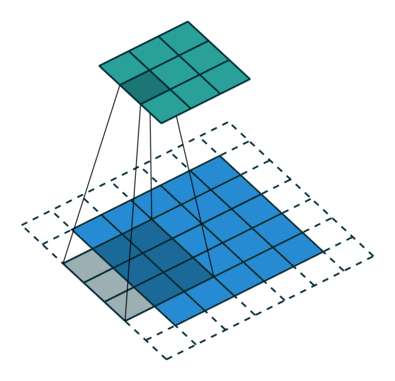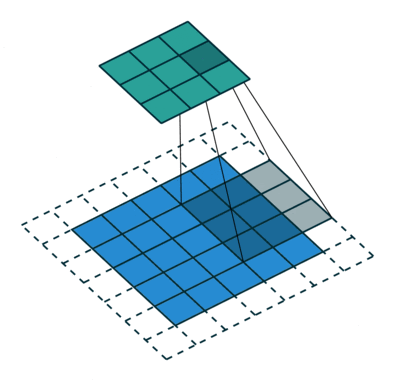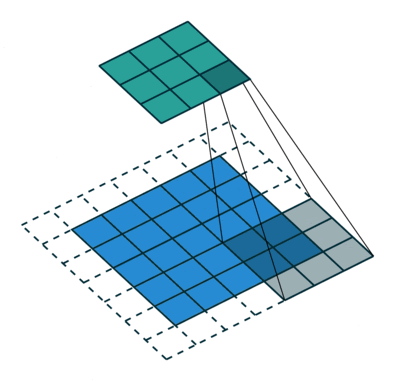
Целью операции свертки является извлечение из входного изображения высокоуровневых признаков, таких как линии. Сети не всегда ограничиваются только одним слоем свертки. Обычно первый сверточный слой отвечает за захватывание низкоуровневых признаков, таких как границы, цвет, ориентация градиента и т.д. С добавлением слоев архитектура адаптируется к признакам высокого уровня. Так происходит полное распознавание сетью изображения из набора данных, очень близкое к зрительной работе человеческого мозга.
Результат операции может быть одним их двух:
- свернутый объект уменьшается в размере по сравнению с входными данными;
- размерность свернутого объекта увеличивается, либо остается прежней.
Первый результат достигается путем Valid-паддинга (Valid Padding) — заполнения без дополнения. Второй ожидается при применении Same-паддинга (Same Padding) — заполнения с дополнением нулями.
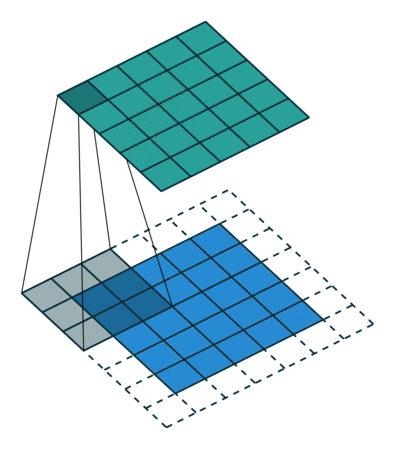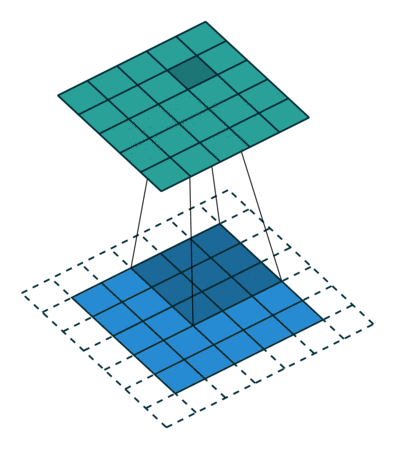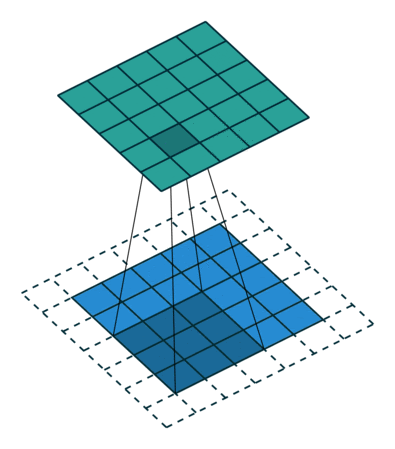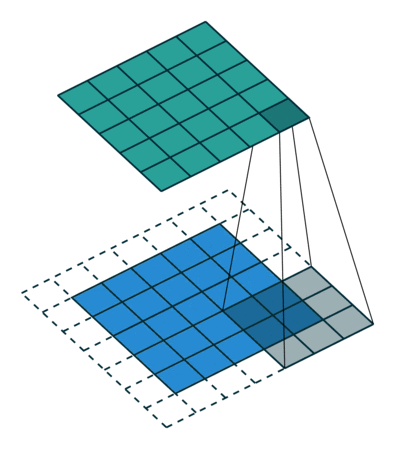
Когда мы увеличиваем изображение 5x5x1 до изображения 6x6x1, а затем применяем к нему ядро 3x3x1, то обнаруживаем, что размер свернутой матрицы оказывается 5x5x1. Отсюда и название — Same Padding (то же самое).
Если выполнить ту же операцию без дополнения, получится матрица с размерами самого ядра (3x3x1) — Valid Padding (корректное заполнение).
В этом репозитории https://github.com/vdumoulin/conv_arithmetic содержится множество GIF-файлов, которые помогут лучше понять, как паддинг и длина шага могут работать вместе для достижения необходимых вам результатов.
Слой пулинга
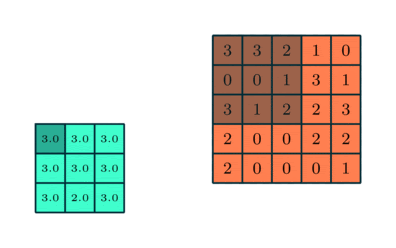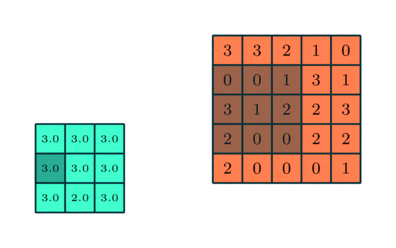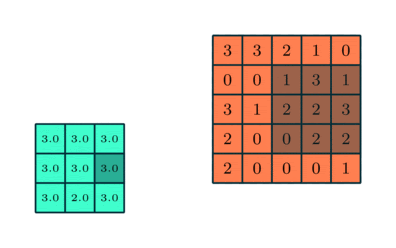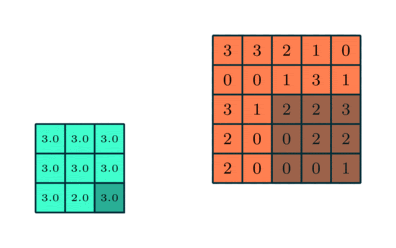
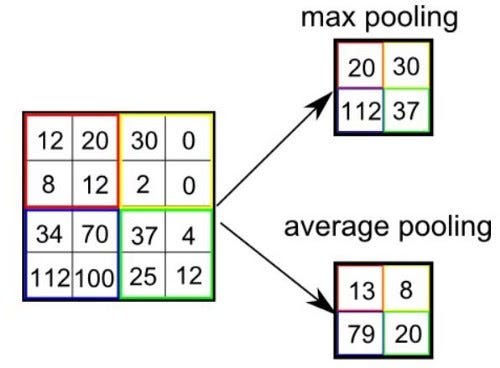
Как и слой свертки, слой пулинга отвечает за уменьшение пространственного размера свернутого объекта. Уменьшение размерности позволяет сократить вычислительную мощность, необходимую для обработки данных. Кроме того, уплотнение изображения полезно для извлечения доминирующих признаков, которые являются ротационными и позиционно-инвариантными. В результате поддерживается процесс эффективного обучения модели.
Различают два типа пулинга:
- максимальный — возвращающий максимальное значение из фрагмента изображения, охватываемого ядром;
- средний — возвращающий среднее всех значений из фрагмента изображения, охватываемого ядром.
Максимальный пулинг также выполняет функцию подавления шума. Он полностью устраняет шумовые активации, а также выполняет шумоподавление наряду с уменьшением размерности. Средний пулинг просто выполняет уменьшение размерности в качестве механизма подавления шума. Из этого можно сделать вывод, что максимальный пулинг работает намного эффективнее среднего.
Слой свертки и слой пулинга вместе образуют I-й слой сверточной нейронной сети. В зависимости от сложности изображений, количество таких слоев может быть увеличено для более точного захватывания деталей низкого уровня, но ценой увеличения вычислительной мощности.
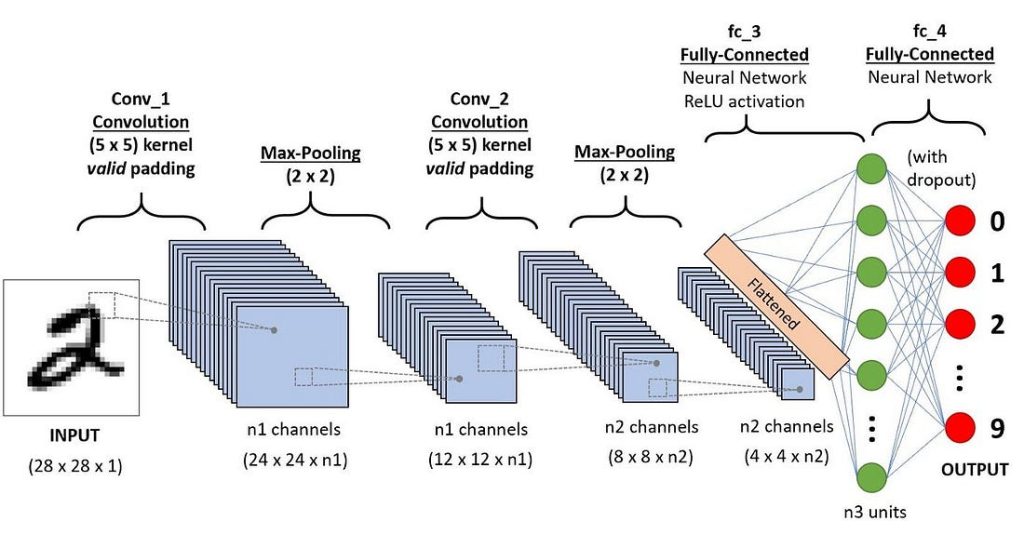
Описанный выше процесс позволит вам успешно создать модель, способную распознавать признаки изображений. Далее останется сжать конечный вывод и передать его в обычную нейронную сеть для классификации.
Классификация — полносвязный слой (слой FC)
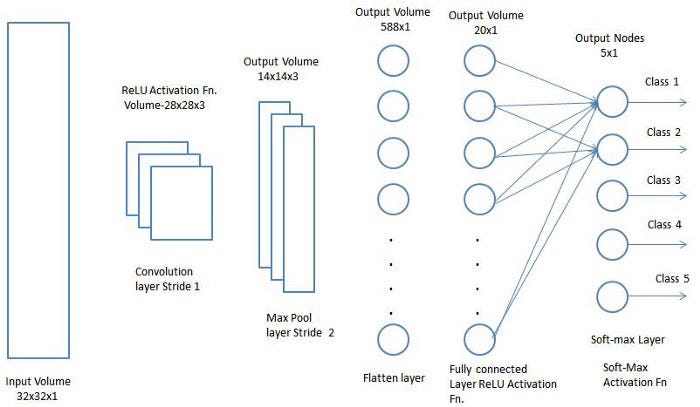
Добавление полносвязного слоя — это (как правило) дешевый способ изучения нелинейных комбинаций признаков высокого уровня, представленных выходными данными сверточного слоя. Полносвязный слой изучает вероятность нелинейной функции в этом пространстве.
Теперь, когда входное изображение преобразовано в форму, подходящую для многоуровневого персептрона, необходимо свести его к вектору-столбцу. Сжатый вывод подается в нейронную сеть с прямой передачей, и обратное распространение применяется на каждой итерации обучения. В течение ряда эпох модель способна различать доминирующие и определенные низкоуровневые признаки изображения и классифицировать их с помощью метода Softmax Classification.
В настоящее время доступны различные архитектуры CNN, сыгравшие ключевую роль в создании алгоритмов. Они обеспечивают работу ИИ сегодня и будут приводить его в действие в обозримом будущем. Некоторые из них перечислены ниже:
- LeNet;
- AlexNet;
- VGGNet;
- GoogLeNet;
- ResNet;
- ZFNet.
GitHub Notebook — Распознавание рукописных цифр с использованием набора данных MNIST с TensorFlow
Читайте также:
- О нейронных сетях в двух словах
- Автоматизация Doom с глубоким Q-обучением: реализация в Tensorflow
- Глубокие свёрточные нейросети: руководство для начинающих
Читайте нас в Telegram, VK и Дзен
Перевод статьи Sumit Saha: A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way





