
В Sarus мы создаем инструменты для работы с конфиденциальными данными. Наш продукт базируется на 3 “китах”:
- Дистанционное выполнение кода для сохранения конфиденциальных данных.
- Генерация синтетических данных для предоставления пользователю возможности сборки.
- Дифференциальная приватность для контроля нарушений приватности.
Таким образом, большую часть времени мы посвящаем тому, что обучаем модели машинного обучения генерировать синтетические данные. Кроме того, мы разрабатываем инструменты для дистанционного выполнения кода. Dask так или иначе связан с обеими вышеуказанными задачами. Это отличная библиотека для параллельных вычислений на Python, а также хорошо разработанное программное обеспечение и отличный источник вдохновения для беспрепятственного дистанционного выполнения кода.
Из этого краткого туториала вы узнаете о том, как развернуть кластер dask на kubernetes в общедоступном облаке, таком как GCP.
Шаг 1-й. Запуск кластера kubernetes
На консоли GCP создайте кластер GKE:
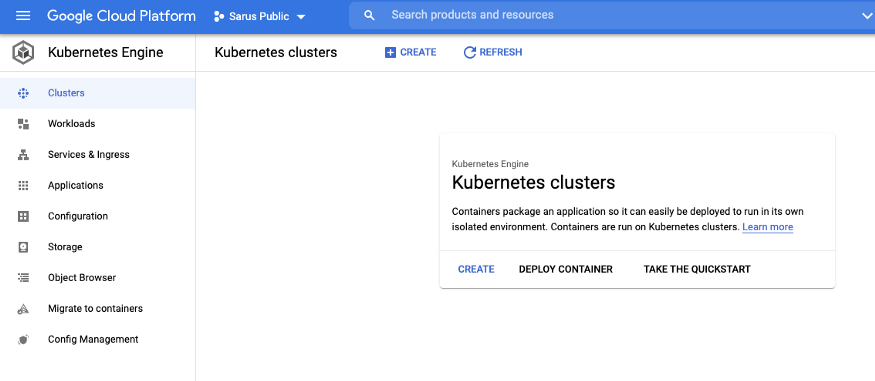
В нашем случае это будет базовый кластер под названием sarus-cluster в регионе europe-west1 и в текущем проекте: sarus-public.
Затем загрузите файл учетных данных, чтобы получить доступ к кластеру с компьютера. Для этого просто введите следующую команду в терминале:
gcloud container clusters get-credentials sarus-cluster --region europe-west1 --project sarus-publicЕсли у вас не установлен gcloud, обратитесь к этой документации: она помогает легко загрузить gcloud на многие платформы.
Теперь кластер kubernetes должен быть запущен. Для управления им установите утилиту командной строки kubectl. Здесь дается обзор инструмента и рассказывается, как его установить.
Чтобы проверить узлы кластера, выполните следующую команду:
# kubectl get nodesШаг 2-й. Развертывание dask с помощью helm
Для развертывания dask мы будем использовать менеджер пакетов helm. Для этого просто установите helm и введите следующие команды:
helm repo add dask https://helm.dask.org/
helm repo update
helm install sarus-dask dask/daskЕсли вас не устраивает конфигурация по умолчанию dask helm chart, можете использовать файл конфигурации:
# dask_config.yaml
worker:
replicas: 7
resources:
limits:
cpu: 1
memory: 2G
requests:
cpu: 0.5
memory: 1G
env:
- name: EXTRA_PIP_PACKAGES
value: pandas scikit-learn --upgradeи инициируйте:
helm install sarus-dask dask/dask -f dask_config.yamlЧтобы проверить, успешно ли прошло развертывание и правильно ли работают различные сервисы, предоставляемые dask, воспользуйтесь следующим:
# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
sarus-dask-jupyter 1/1 1 1 5m21s
sarus-dask-scheduler 1/1 1 1 5m21s
sarus-dask-worker 3/3 3 3 5m21s
# kubectl get service
...Проверить состояние кластера можно через веб-интерфейс, но, поскольку кластер dask не предоставляет никаких адресов для доступа к нему извне GCP, необходимо перенаправить локальные HTTP-запросы в кластер с помощью следующей команды:
kubectl port-forward service/sarus-dask-scheduler 8001:80Затем можете проверить http://localhost:8001/status, и вы увидите нечто подобное:
Шаг 3-й. Подключение к кластеру
Чтобы подключиться к кластеру, убедитесь, что пакеты python dask и dask_kubernetes установлены локально. Затем запустите интерпретатор python и инициируйте:
from dask_kubernetes import HelmCluster
from dask.distributed import Client
cluster = HelmCluster(release_name="sarus-dask")
client = Client(cluster)Таким образом вы соединитесь с кластером. После подключения можете приступить к простому заданию:
import dask.array as da
x = da.random.random((10000, 10000), chunks=(1000, 1000))
y = x + x.T
z = y[::2, 5000:].mean(axis=1)
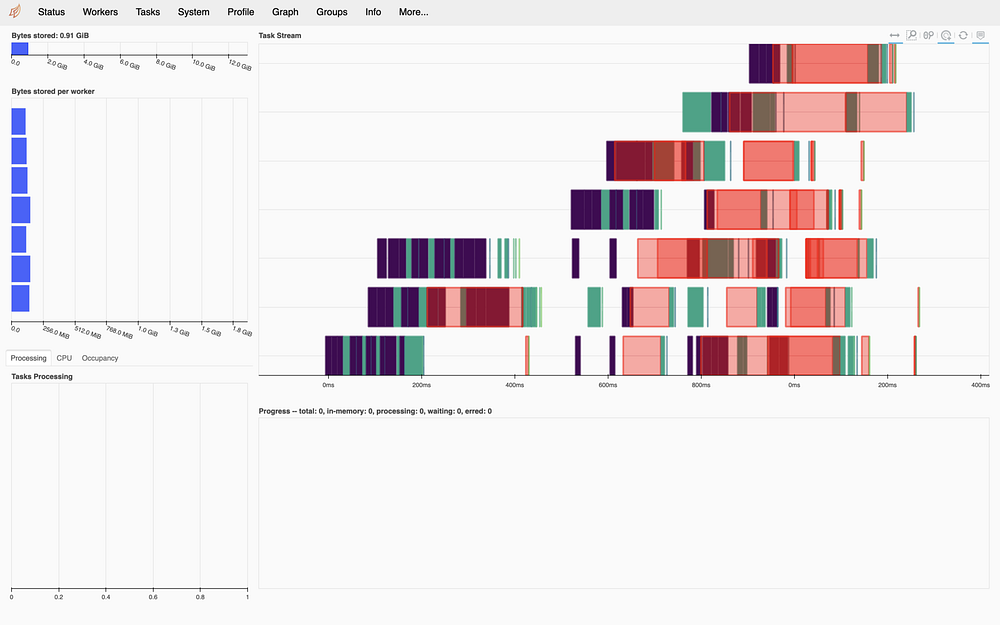
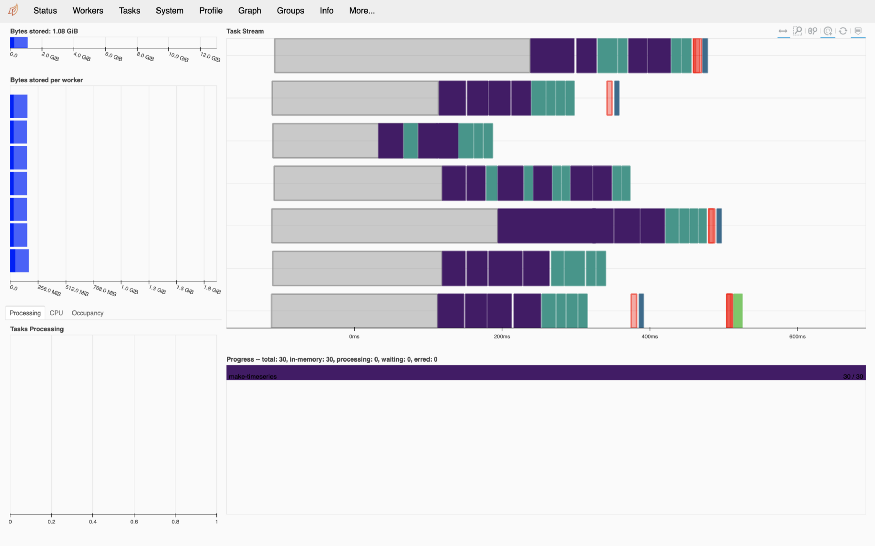
z.compute()Можете наблюдать за рабочими процессорами в веб-интерфейсе:
Вы также можете манипулировать panda-подобными датафреймами:
import dask
df = dask.datasets.timeseries()
df = df.persist()
df.groupby('name').agg({'x': ['mean', 'std'], 'y': ['mean', 'count']}).compute().head()Как видите, кластер хранит данные:
Dask также можно использовать для параллельного запуска заданий машинного обучения. Вот пример поиска в сетке по гиперпараметрам классификации опорных векторов:
from sklearn.datasets import make_classification
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
import pandas as pd
X, y = make_classification(n_samples=1000, random_state=0)
param_grid = {"C": [0.001, 0.01, 0.1, 0.5, 1.0, 2.0, 5.0, 10.0],
"kernel": ['rbf', 'poly', 'sigmoid'],
"shrinking": [True, False]}
grid_search = GridSearchCV(SVC(gamma='auto', random_state=0, probability=True),
param_grid=param_grid,
return_train_score=False,
cv=3,
n_jobs=-1)
import joblib
with joblib.parallel_backend('dask'):
grid_search.fit(X, y)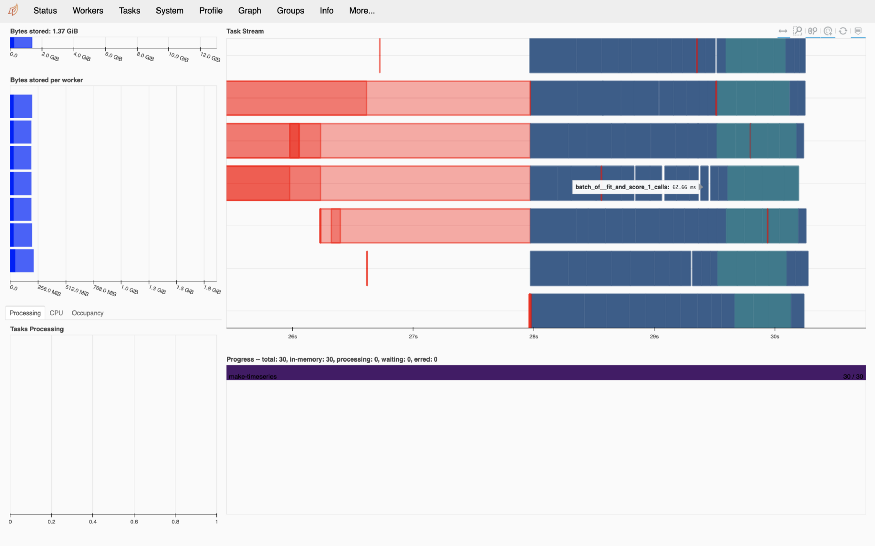
Проделав эти три шага, вы убедитесь, насколько мощным может быть cloud + k8s + dask. Вы также увидите, насколько зрелой стала экосистема разработки данных, поскольку ее настройка и запуск — это вопрос нескольких щелчков мыши и команд.
Конечно, многое еще предстоит сделать, чтобы подготовить эту технологию к производственной среде (по крайней мере, с точки зрения безопасности и управления разрешениями). Но kubernetes уже сегодня показывает, что способен на многое, например автоматизированное предоставление ресурсов и автоматическое масштабирование/самовосстановление.
Читайте также:
- О машинном обучении простым языком
- Машинное обучение с Amazon Aurora
- Все модели машинного обучения за 6 минут
Читайте нас в Telegram, VK и Дзен
Перевод статьи Nicolas Grislain: Distributed ML with Dask and Kubernetes on GCP


")


