
В XXI веке машинное обучение и искусственный интеллект будут “править бал”. Ежедневно мы производим большое количество данных. Сюда также входят данные о покупках клиентов на сайтах онлайн-коммерции и в продуктовых магазинах, информация о продажах компаний и т. д.
Вот затем, чтобы управлять этими данными, нам и необходимо машинное обучение. Поэтому неудивительно, что эта IT-сфера набирает обороты. Но что такое машинное обучение? Чем оно отличается от традиционного способа программирования? Давайте разберемся в этом без заумной научной терминологии.
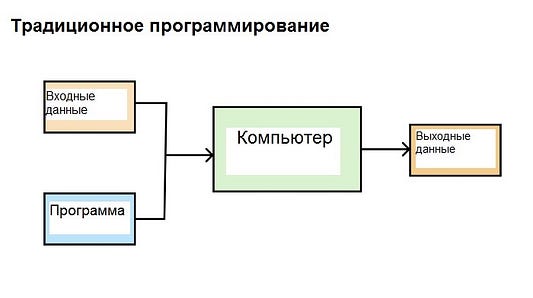
Традиционное программирование
При обычном компьютерном программировании мы вводим входные данные в систему, и после их обработки компьютер генерирует выходные значения.
Например:
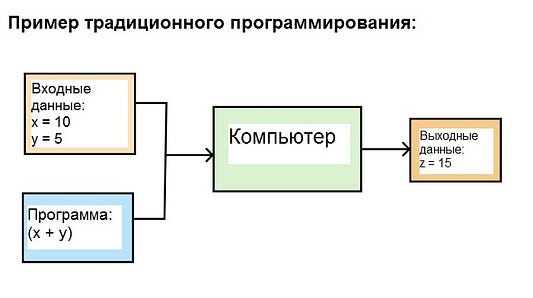
В этом случае мы даем компьютеру входные данные x = 10 и y = 5, из которых он генерирует выходные данные (z = 15).
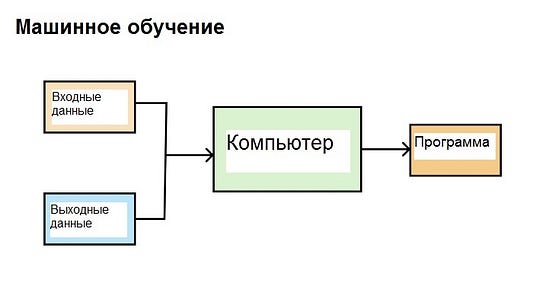
Суть машинного обучения
Тут-то и кроется различие. Задача машинного обучения — получить представление о данных, а в наших примерах данные уже сгенерированы. В этом случае мы различаем входную информацию и данные на выходе, т.е. нашу цель. А в машинном обучении мы вводим как входные, так и выходные данные в компьютер, а он в свою очередь генерирует выходную информацию в виде программы.
Например:
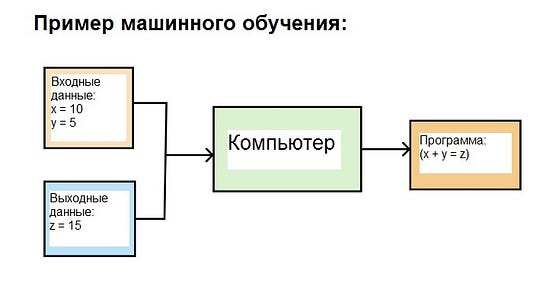
Здесь мы вводим входные значения (x = 10, y = 5) и выходные данные (z = 15), а алгоритм машинного обучения генерирует программу (x + y = z).
Таким образом, машинное обучение — это не что иное, как формирование связи между входными и выходными значениями. Алгоритм машинного обучения автоматически извлекает информацию из входных и выходных данных и предоставляет новые выходные данные в виде программы.
После того, как мы получили искомое отношение (т.е. программу), мы можем предсказать, какие выходные значения получатся после обработки скрытых входных данных. Это может оказаться полезным, например, при прогнозировании будущих продаж компании.
Давайте представим, что у нас есть данные об объемах продаж компании за прошедший период и переменные величины, повлиявшие на этот объем. После того, как мы возьмем эти переменные в качестве входных данных, а сами продажи в качестве выходных (т.е. целевых), мы передадим их алгоритму машинного обучения, который сгенерирует определенное отношение. Получив результат, мы сможем прогнозировать объем продаж компании в будущем.
Как правило, машинное обучение оперирует огромным количеством данных, которые выстраиваются в миллионы строк и сотни столбцов. Алгоритм машинного обучения генерирует взаимосвязь между этим колоссальным набором значений и подготавливает модель машинного обучения для прогнозирования результатов.
Ключевой принцип машинного обучения:
“Мы, люди, учимся на собственном опыте и реагируем в соответствии с ним. Однако машина (компьютер) учится на тех данных, которые мы ей предоставляем. На основе этой информации она генерирует модель данных, которая дает представление о выходных значениях, полученных из скрытых входных данных.”
Сферы применения машинного обучения:
- Общее прогнозирование.
- Распознавание изображений.
- Распознавание речи.
- Рекомендации по использованию продукта.
- Фильтрация спама в электронной почте.
- Прогнозирование цен на акции.
Благодарю вас за то, что прочитали мою первую статью о машинном обучении. Я постарался объяснить его принципы как можно проще. Моей целью было внести вклад в наработки команды исследователей данных и поделиться знаниями об этой удивительной области компьютерной науки, причем сделать это максимально доступно.
Читайте также:
- Как инструменты дизайна интерфейса и визуализации способствуют развитию Machine Teaching?
- 29 сниппетов Pytorch для ускорения цикла машинного обучения
- Внутренняя платформа МО Bigeye: цели и методы создания
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Saurabh Rana, “Machine Learning in Layman’s Language”





