
Термин “наука о данных” появился около 10 лет назад. Сейчас это одно из самых популярных словосочетаний в современном мире. ИТ-технологии активно внедряются во все сферы деятельности человека, от академических исследований до работы правительственных организаций почти в каждом секторе экономики. Поэтому появилось множество новых вакансий на рынке труда, таких как специалисты и инженеры по обработке данных.
Так что же означает этот термин? И что в нем такого особенного?
Существуют общие определения обязанностей для специалистов по данным. Однако потребности разных рынков привели к некоторым различиям в определениях и, возможно, даже к разным ответам на эти два вопроса. Я попытаюсь изложить здесь свое видение общей картины. Надеюсь, эта информация поможет вам получить более полное представление об этой сфере.
Что такое наука о данных?
Как следует из названия, наука о данных — это наука, которая занимается данными. Как показало развитие технологий в течение последних десятилетий, это определение вбирает в себя все больше понятий. В соответствии с текущей технологической инфраструктурой термин “наука о данных” включает в себя все, начиная со сбора данных и заканчивая всевозможными методами их хранения и анализа, вплоть до различных каналов, которые используют результаты такой деятельности. Этот тип цепочек обработки данных обычно называют конвейерами данных.
Конвейеры данных
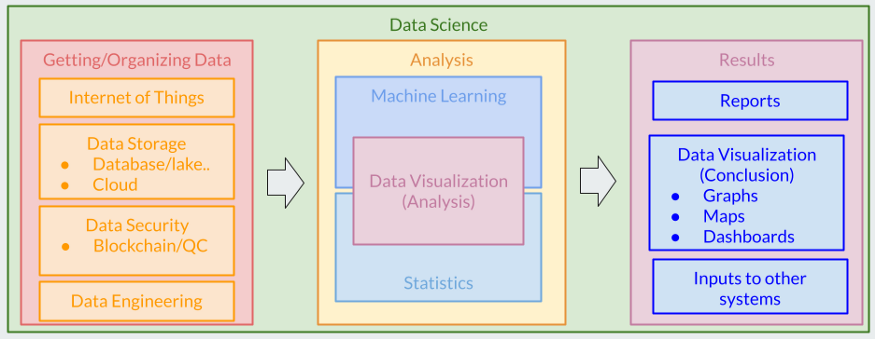
Конвейер данных обычно представляет собой упорядоченный набор компонентов, манипулирующих данными, начиная со сбора данных и заканчивая представлением полезной информации, извлеченной из них, а также все промежуточные этапы. Действуя подобно производственной цепочке, каждый из этих компонентов отвечает за обработку предоставленных входных данных определенным образом, а полученные данные на выходе используются в качестве входных для следующего этапа обработки. Хотя термин “конвейер данных” обычно означает долгосрочное внедрение компонентов для максимальной автоматизации процесса, похожий подход используется при анализе adhoc. Эту технологическую цепочку можно разбить на четыре основных этапа.
Сбор данных
Первый (практический) этап процесса, который подготавливает данные для дальнейшего анализа. Обычно перед этим проводится этап мозгового штурма с целью выяснения вопроса/проблемы для определения данных, подлежащих сбору. Иногда первый этап цепочки предварительно включает в себя сбор данных (часто автоматизированный), выражающийся в веб-скрейпинге или получении данных, которые поступают с удаленных датчиков через мобильную сеть. В зависимости от конкретного способа сбора, сюда может также входить написание поисковых роботов или сценариев, собирающих данные из какого-либо источника API.
Хранение данных
После этого данные направляются на платформу хранения данных, которая может представлять собой облачное хранилище или локальную базу данных. При таком перенаправлении происходит конвертирование формата данных (что часто подразумевается под обработкой данных), чтобы результат на выходе был совместим с параметрами хранилища, которое, как правило, оптимизируется для эффективного извлечения данных. Структура таких платформ хранения часто специально разрабатывается под соответствующие приложения, а сама разработка входит в обязанности инженеров по обработке данных. Эти специалисты также должны писать функции (часто SQL), которые извлекают оптимальные данные для дальнейшего анализа.
На практике большинство необработанных датасетов содержат много шума, который подлежит очистке. Инженеры по обработке данных, как правило, отвечают за подготовку данных к анализу. В ходе такой подготовки большая часть процесса очистки, а также сбора и хранения данных, описанных выше, максимально автоматизируются и выполняются настолько эффективно, насколько это возможно.
Анализ данных
Основная цель этого этапа — выявить тенденции и закономерности, которые присущи данным. В зависимости от типа данных, а также конечных целей проекта, применяется один из множества различных подходов. Как правило, этот этап включает в себя построение модели с использованием существующих данных. Для этого применяются многочисленные методы — от регрессии и анализа временных рядов до различных типов алгоритмов машинного обучения, таких как кластеризация и нейронные сети. Диапазон использования таких моделей поистине широк: от прогнозирования данных временных рядов в коммерческом и финансовом секторах до распознавания изображений для классификации опухолей и технологий автономного вождения.
Презентация
Этап, на котором используются конечные результаты. Они представляются либо в виде отчета/презентации, либо в виде конвейера готовых данных, интегрированном в систему.
Обычно для анализа adhoc полученные выводы представляются заинтересованным сторонам либо в отчете, либо в слайдовой презентации. Весьма вероятно, что заинтересованные стороны, скорее всего, будут гораздо менее информированы о технических деталях конвейера данных. Задача специалиста по обработке данных здесь очень похожа на задачу продавца. Основная цель их обоих состоит в том, чтобы убедить клиента: проделанная работа более чем стоила потраченных усилий и очень выгодна ему как заинтересованной стороне.
Хорошая визуализация данных является ключом к представлению результатов анализа (трудно переоценить значение знаменитой цитаты “Одна картинка стоит тысячи слов” в этом контексте). Вот две интересные ветки на Reddit — Данные прекрасны и Данные ужасны. В них можно найти множество интересных примеров, которые могут пригодиться при создании презентаций.
Конечный результат будет представлен либо в виде отчета/презентации, либо в виде конвейера готовых данных, интегрированного в систему, которая продолжит работу в высокоавтоматизированном режиме.
Вывод
Чтобы оптимизировать ценность, которую можно создать с помощью различных компонентов, специалистам по обработке данных часто приходится начинать работу с беседы с заказчиками. Обычно этот подход называется “ориентация на бизнес-проблемы”. Специалист по обработке данных собирает информацию от заинтересованных сторон, чтобы определить следующие аспекты.
- Конечную цель проекта: чего хочет заказчик, инвестирующий в проект конкретное количество денег и времени.
- Данные, подлежащие сбору: они обычно определяются конечной целью проекта.
- Требования к точности: в некоторых проектах нередко приходится жертвовать точностью ради эффективности отклика, например в системах реального времени.
- Потребность в дополнительном оборудовании: при наличии достаточной инфраструктуры для использования конечного продукта проекта.
Обеспечение удовлетворительных результатов на каждом из этих уровней не менее важно, чем их результирующая производительность в конвейере данных. Хорошая производительность и эффективность этих факторов имеют решающее значение для окончательного успеха. В этой связи хотелось бы вспомнить известную цитату одного из легендарных игроков НБА Карима Абдул Джаббара: “Один человек может стать решающим звеном в команде, но одного человека недостаточно для создания команды”.
Почему наука о данных внезапно стала популярной?
Мы уже давно обладаем как самими данными, так и методами для их анализа. Линейная регрессия, например, упоминается уже в 1800-х годах в работах Лежандра (1805) и Гаусса (1809). Но почему собственно наука о данных появилась только в прошлом десятилетии? На мой взгляд, к этому привело взаимодействие нескольких факторов.
Развитие интернета
С тех пор как интернет-сервисы обрели популярность в конце 1990-х годов, по всему миру ежедневно генерируются большие объемы данных. Особенно эта тенденция стала заметна, начиная с середины 2000-х годов (“бум” социальных сетей и создание смартфонов). Многие организации воспользовались вновь открывшимися информационными ресурсами и стали извлекать тенденции и закономерности поведения людей различных категорий. Полученные результаты стали чрезвычайно ценным подспорьем для повышения эффективности бизнеса во многих секторах, от электронной торговли до инфраструктурной аналитики.
Вычислительная мощность
Многие приемы машинного обучения, такие как метод опорных векторов, разработанный в начале 1990-х годов, стали популярными благодаря развитию вычислительной мощности. Машины коммерческого уровня, наконец, обрели достаточную мощность, чтобы больше людей могли использовать их преимущества. Сейчас можно анализировать данные сложных форматов, такие как звук, изображения и видео многими способами, которые раньше были просто недоступны.
Облачные вычисления
Активное использование инноваций в сфере интернета и вычислительных мощностей неизбежно привело к развитию облачных вычислений. Прежде чем облачные вычисления обрели популярность ближе к 2010 году, уже существовали такие технологии, как распределенные вычисления (например, LHC Computing GRID). Они нашли широкое применение в специализированных отраслях, например, в научных исследованиях. Преимущества такого бурного развития технологий очевидны. У нас появилась возможность владеть оборудованием, которое выполняет за нас работу. Благодаря дистанционному управлению мы запускаем задание, гасим свет, выключаем компьютер и отправляемся в бар, зная, что в это время работа продолжается без нашего присутствия.
Заключение
Взаимосвязь и взаимопроникновение вышеперечисленных факторов очевидны. Многие концепции, связанные с наукой о данных, уже существовали задолго до того, как сами термины “дата-сайенс”, “регрессия” и “конвейер данных” вошли в моду. По мере появления новых технологий некоторые из этих базовых понятий все еще будут существовать. Мы же сможем в дальнейшем использовать их более разумным способом с помощью еще более продвинутых инструментов. Неудивительно, что на курсах по обработке данных уделяют внимание именно этим аспектам, а не особенностям интерфейса какого-нибудь коммерческого софта с функциями машинного обучения.
В заключение хотелось бы напомнить золотое правило для всех процессов, связанных с обработкой данных: “Что заложишь, то и получишь”.
Читайте также:
- Значение Data Science в современном мире
- Настройка Data Science окружения на вашем компьютере
- Основы науки о данных
Читайте нас в Telegram, VK и Дзен
Перевод статьи Jason Tam: Data Science — What does it really mean?





