
Начнем с азов
Предлагаю начать с разработки базового приложения с несколькими пользователями. Развернуть всю систему на одном сервере проще простого. Именно с этого начинает большинство разработчиков.
- Сайт (включая API) работает на веб-сервере, таком как Apache (или Tomcat).
- База данных, такая как Oracle (или mysql).
Однако у такой архитектуры есть следующие недостатки.
- Если база данных выходит из строя, вся система тоже “летит”.
- Если веб-сервер выходит из строя, то же самое происходит и с системой.
В данном случае у нас нет аварийного переключения и резервных систем. Если сервер выходит из строя, все выходит из строя.
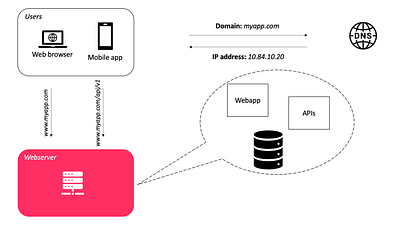
Использование DNS-сервера для разрешения имен хостов и IP-адресов
На приведенном выше рисунке показано, как пользователи (или клиенты) подключаются к DNS-системе, чтобы получить IP-адрес сервера (интернет-протокол), на котором размещена система. Как только IP-адрес получен, запросы отправляются непосредственно в систему.
При каждом посещении сайта компьютер выполняет DNS-поиск.
Обычно сервер DNS (Domain Name System — системы доменных имен) используется в качестве платной услуги, предоставляемой хостинговой компанией, и не запускается на вашем сервере.
Искусство масштабирования
Повышение производительности системы или масштабирование требуется по различным причинам. Например:
- из-за увеличения объема данных;
- из-за расширения функционала (введение множества различных транзакций);
- из-за увеличения количества пользователей.
Масштабируемость обычно означает возможность обрабатывать больше пользователей, клиентов, данных, транзакций или запросов, не влияя на пользовательский интерфейс, за счет добавления большего количества ресурсов.
Вы должны решить, как именно будете масштабировать систему, исходя из двух существующих типов масштабирования: вертикального — scale-up и горизонтального — scale-out.
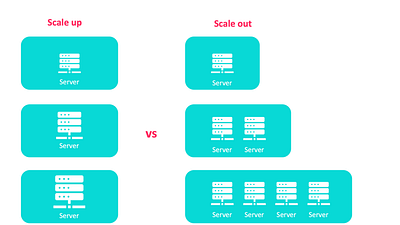
Масштабирование: добавьте больше ОЗУ и ЦП на сервер
Так называемое “вертикальное масштабирование” относится к максимизации ресурсов системы для повышения ее способности справляться с растущей нагрузкой. К примеру, вы можете увеличить мощность сервера путем расширения потенциала оперативного запоминающего устройства (ОЗУ) память и центрального процессора (ЦП).
Так, сервер с 8 ГБ оперативной памяти легко обновить до 32 ГБ или даже 128 ГБ. Это можно сделать путем замены или добавления оборудования.
Вы можете воспользоваться следующими способами вертикального масштабирования.
- Увеличение емкости ввода-вывода за счет добавления большего количества жестких дисков в массивы RAID.
- Оптимизация времени доступа к вводу-выводу за счет перехода на твердотельные накопители (SSD).
- Переключение на сервер с большим количеством процессоров.
- Повышение пропускной способности сети за счет обновления сетевых интерфейсов или установки дополнительных.
- Сокращение операций ввода-вывода за счет увеличения оперативной памяти.
Вертикальное масштабирование является хорошим вариантом для небольших систем, предполагающим обновление оборудования. При этом оно имеет серьезные ограничения.
- Невозможно добавить неограниченную мощность к одному серверу (все зависит в основном от операционной системы и ширины шины памяти сервера).
- Обновление оперативной памяти в системе требует выключения сервера, поэтому, если в системе только один сервер, время простоя неизбежно.
- Мощные машины обычно стоят намного дороже, чем популярное оборудование.
Масштабирование применимо не только к аппаратным средствам, но и к программному обеспечению. К примеру, оно включает оптимизацию запросов и кода приложения.
Нужно ли вам больше одного сервера?
С ростом числа пользователей никогда не бывает достаточно одного сервера. Вам придется разделить его на несколько серверов.
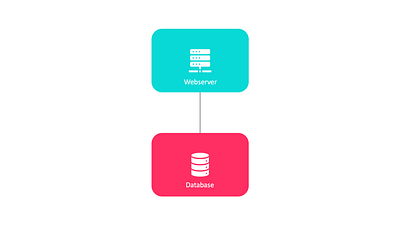
При такой архитектуре появляются следующие преимущества.
- Веб-сервер можно настраивать иначе, чем сервер базы данных.
- Веб-серверу требуется более мощный процессор, а сервер баз данных использует больше оперативной памяти.
- Использование отдельных серверов для веб-уровня и уровня данных позволяет им масштабироваться независимо друг от друга.
Горизонтальное масштабирование: добавьте любое количество аппаратных и программных средств
При так называемом “горизонтальном масштабировании” добавляют больше объектов (машин, служб) в пул ресурсов. Добиться горизонтального масштабирования сложнее, чем вертикального, так как его методы предусматриваются до того, как система будет построена.
Горизонтальное масштабирование часто стоит дороже, потому что даже для простейших систем требуется больше одного сервера, но эти затраты окупаются на более позднем этапе. Вам придется находить компромиссные решения, поскольку:
- увеличение количества серверов означает необходимость поддержки большего числа ресурсов;
- код системы также нуждается в изменениях, чтобы обеспечить параллелизм и распределение работы между несколькими серверами.
Использование балансировщика нагрузки для равномерного распределения трафика между всеми узлами
Балансировщик нагрузки — это специализированный аппаратный или программный компонент, который помогает равномерно распределять трафик по кластеру серверов для повышения быстрого реагирования и эксплуатационной пригодности системы (включая приложения, веб-сайты, базы данных, но не ограничиваясь этим).
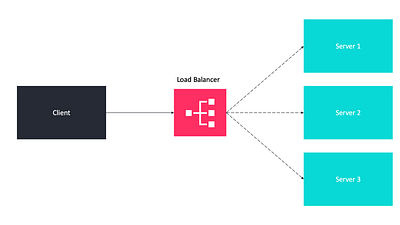
Обычно балансировщик нагрузки находится между клиентом и сервером. Принимая трафик приложения и сетевой трафик, он распределяет весь объем информации между несколькими внутренними серверами с использованием определенных алгоритмов. Балансировщик нагрузки может также использоваться между веб-серверами и серверами баз данных.
HAProxy и NGINX — два популярных вида софта с открытым исходным кодом, предназначенные для балансировки нагрузки.
Технология балансировки нагрузки обеспечивает отказоустойчивость и повышение эксплуатационной пригодности системы следующим образом.
- Если сервер 1 отключится, весь трафик будет перенаправлен на сервер 2 и сервер 3. В результате сайт не будет отключен. Вам также придется добавить новый исправный сервер в пул серверов, чтобы сбалансировать нагрузку.
- Если трафик будет быстро расти, вам нужно добавить еще серверов в пул веб-серверов. Балансировщик нагрузки будет распределять трафик между ними.
Балансировщики нагрузки используют различные стратегии и алгоритмы для оптимального распределения нагрузки следующим образом.
- Циклический алгоритм диспетчеризации: в этом случае каждый сервер получает запросы в последовательном порядке, аналогичном принципу очередности “Первый пришел — первым обслужен” (FIFO).
- Минимальное количество подключений: запрос будет направлен на сервер с наименьшим количеством подключений.
- Наиболее быстрый ответ: запрос будет направлен на самый быстрореагирующий сервер (в последнее время или чаще всего).
- Взвешенная стратегия: более мощные серверы будут получать больше запросов, чем более слабые, невзвешенные.
- IP-хэш: в этом случае хэш IP-адреса клиента вычисляется для перенаправления запроса на сервер.
Простейший способ сбалансировать запросы между несколькими серверами — это использование аппаратного устройства, при котором:
- добавление и удаление реальных серверов с общего IP-адреса происходит мгновенно;
- балансировку нагрузки можно выполнять произвольно.
Балансировка нагрузки программного обеспечения является более дешевой альтернативой аппаратным балансировщикам нагрузки. Она может осуществляться на уровне сети (4) и уровне приложения (7).
- Уровень 4: балансировщик нагрузки использует информацию, предоставляемую TCP на сетевом уровне. При этом он обычно выбирает сервер, не просматривая содержимое запроса.
- Уровень 7: запросы могут быть сбалансированы на основе информации в строке запроса, файлах cookie или любом выбранном вами заголовке, а также на регулярном уровне, включая адреса источника информации и получателя.
Масштабирование реляционной базы данных
В простой системе для сохранения элементов данных вы можете использовать такую реляционную СУБД, как Oracle или MySQL. Но реляционные системы баз данных имеют свои проблемы, особенно при масштабировании.
Существует множество методов масштабирования реляционной базы данных: репликация «ведущий-ведомый», репликация «ведущий-ведущий», федерация, шардинг, денормализация и настройка SQL. Вот коротко суть каждого из них.
- Репликация позволяет хранить несколько копий одних и тех же данных на разных машинах.
- Федерация (или функциональная декомпозиция) разделяет базы данных по функциям.
- Шардинг — это шаблон архитектуры базы данных, связанный с разделением путем размещения разных частей данных на разных серверах, чтобы разные пользователи получали доступ к разным частям набора данных.
- Денормализация — способ повысить производительность чтения за счет оптимизации процесса записи путем обработки данных в нескольких таблицах, что позволяет избежать дорогостоящих соединений.
- Настройка SQL.
Репликация “ведущий-ведомый”
Метод репликации “ведущий-ведомый” позволяет реплицировать данные с одного сервера базы данных (ведущего) на один или несколько других серверов баз данных (ведомых), как показано на рисунке ниже.
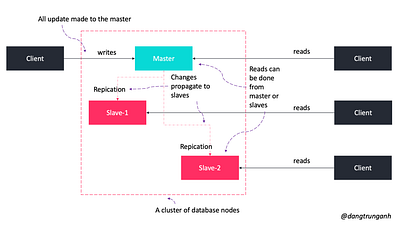
Работает это так.
- Клиент подключается к “ведущему” серверу и обновляет данные.
- Затем данные передаются по “ведомым” устройствам до тех пор, пока все данные не будут согласованы на серверах.
На практике здесь все же есть небольшая загвоздка.
- Если “ведущий” сервер по какой-либо причине выйдет из строя, данные по-прежнему будут доступны “ведомым” серверам, но новые записи будут невозможны.
- Нужен дополнительный алгоритм для превращения “ведомого” сервиса в “ведущий”.
Вот возможные решения для обеспечения обработки запросов на обновление только одним сервером.
- Синхронные решения: транзакция изменения данных не фиксируется до тех пор, пока не будет принята всеми серверами (распределенная транзакция), поэтому данные не теряются при аварийном переключении.
- Асинхронные решения: фиксация -> задержка -> распространение на другие серверы в кластере, поэтому некоторые обновления данных могут быть потеряны при аварийном переключении.
Если синхронные решения работают слишком медленно, переходите на асинхронные решения.
Репликация “ведущий-ведущий”
Каждый сервер базы данных может выступать в качестве “ведущего”, в то время как другие серверы тоже рассматриваются как “ведущие”. В какой-то момент все “ведущие” синхронизируются, чтобы убедиться, что все они содержат правильные и актуальные данные.
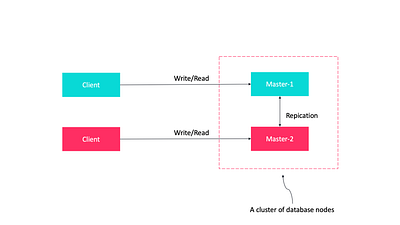
Вот некоторые преимущества репликации “ведущий-ведущий”.
- Если один “ведущий” выходит из строя, другие серверы баз данных могут работать нормально и подменить его. Когда выбывший сервер базы данных снова подключится к сети, он наверстает упущенное с помощью репликации.
- “Ведущие” серверы могут быть расположены на нескольких физических сайтах и могут быть распределены по сети.
- Репликация ограничена возможностью “ведущего” обрабатывать обновления.
Федерация
Федерация (или функциональная декомпозиция) разделяет базы данных по функциям. Например, вместо одной монолитной базы данных у вас может быть три: форумы, пользователи и продукты. Это приведет к сокращению трафика чтения и записи в каждую базу данных и, следовательно, к уменьшению задержки репликации.
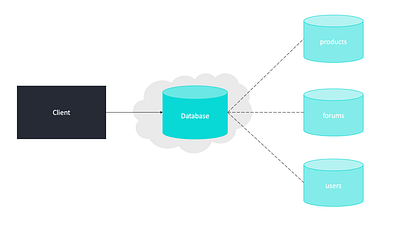
Меньшие базы данных приводят к большему количеству данных, которые могут поместиться в памяти, что, в свою очередь, приводит к большему количеству кэш-попаданий из-за улучшенной локализации кэша. При отсутствии единого централизованного “ведущего” сервера, выполняющего основную сериализацию записи, вы можете записывать параллельно, увеличивая пропускную способность.
Шардинг
Шардинг (также известный как разделение данных) — это метод разделения большой базы данных на множество более мелких частей, вследствие чего каждая из них может управлять только подмножеством данных.
В идеальном случае у вас будут разные пользователи, которые общаются с разными узлами базы данных. Это способствует улучшению управляемости, производительности, эксплуатационной пригодности и балансировки нагрузки системы.
Преимущества шардинга:
- каждый пользователь должен общаться только с одним сервером, поэтому получает быстрые ответы от него;
- нагрузка хорошо распределяется между серверами — если у вас пять серверов, каждый из них должен обрабатывать только 20% нагрузки.
На практике существует множество различных методов разбиения базы данных на несколько более мелких частей.
Горизонтальное разделение
При этом методе разные строки помещаются в разные таблицы. Например, храня профили пользователей в таблицах, вы можете хранить пользователей с идентификаторами менее 1000 в одной таблице, а пользователей с идентификаторами более 1001 и менее 2000 — в другой.
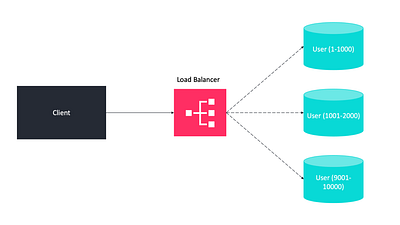
Вертикальное разделение
В этом случае вы разделяете данные для хранения в таблицах, связанных с определенной функцией, на их собственном сервере. Представьте, что создаете систему, подобную Instagram, где нужно хранить данные, связанные с пользователями, фотографии, которые они загружают, и сведения о людях, на которых они подписаны. В этом случае вы можете разместить информацию о профиле пользователя на одном сервере базы данных, списки друзей — на другом, а фотографии — на третьем.
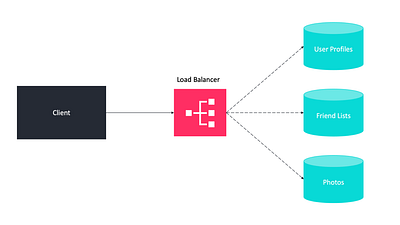
Разделение на основе каталогов
Слабосвязанный подход к этой проблеме заключается в создании службы поиска, которая знает текущую схему разделения и хранит карту каждого объекта и фрагмента базы данных, в котором он хранится.
Этот метод используется, если:
- хранилище данных нуждается в масштабировании за пределы ресурсов, доступных одному узлу хранения;
- необходимо повышение производительности за счет уменьшения конкуренции в хранилищах данных.
Но вы должны знать о существовании общих проблем с методами шардинга.
- Соединения баз данных становятся все более дорогостоящими, а в некоторых случаях просто недоступными.
- Шардинг может нарушить ссылочную
целостностьбазы данных. - Изменения
схемыбазы данных могут стать чрезвычайно дорогостоящими. - Распределение данных неравномерно, и на сегмент приходится большая нагрузка.
Денормализация
Денормализация — это способ повысить производительность чтения за счет повышения производительности записи. Избыточные копии данных записываются в несколько таблиц, чтобы избежать дорогостоящих соединений.
Как только данные распределяются с помощью таких методов, как федерация и шардинг, управление соединениями между центрами обработки данных еще больше усложняется. Денормализация может избавить от необходимости в таких сложных соединениях.
В большинстве систем число операций чтения может значительно превышать число операций записи в соотношении 100:1 или даже 1000:1. Чтение, приводящее к сложному соединению базы данных, может быть очень дорогостоящим, что требует значительных затрат времени на операции с дисковым устройством.
Некоторые СУБД, такие как PostgreSQL и Oracle, поддерживают материализованные представления, которые выполняют работу по хранению избыточной информации и обеспечивают согласованность избыточных копий.
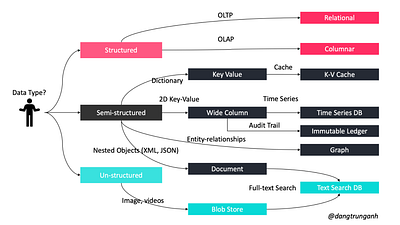
Какую базу данных использовать?
В мире баз данных существует два основных типа решений: SQL и NoSQL. Оба они отличаются построением, типом хранимой информации и используемым методом хранения.
SQL
Реляционные базы данных хранят данные в строках и столбцах. Каждая строка содержит всю информацию об одном объекте, а каждый столбец — все отдельные точки данных.
Наиболее популярные реляционные базы данных:
- MySQL;
- Oracle;
- MS SQL Server;
- SQLite;
- Postgres;
- MariaDB.
NoSQL
Эта категория также называется нереляционными базами данных. Они обычно группируются в пять основных хранилищ:
- ключ-значение;
- графики;
- столбцы;
- документы;
- Blob-объекты.
Хранилища ключей-значений
Данные хранятся в массиве пар ключ-значение. “Ключ” — это имя атрибута, которое связано со “значением”. Хорошо известные хранилища ключей-значений: Redis, Voldemort и Dynamo.
Базы данных документов
В этих базах данные хранятся в документах (вместо строк и столбцов в таблице), которые группируются в коллекции. Каждый документ может иметь совершенно уникальную структуру. Базы данных документов включают в себя CouchDB и MongoDB.
Базы данных с широкими столбцами
Вместо “таблиц”, в столбцовых базах данных хранятся семейства столбцов, служащие контейнерами для строк. В отличие от реляционных баз данных, вам не нужно заранее знать все столбцы, а в каждой строке не обязательно должно быть одинаковое количество столбцов.
Столбцовые базы данных лучше всего подходят для анализа больших наборов данных. Самые известные — Cassandra и HBase.
Графические базы данных
Эти базы данных используются для хранения данных, отношения которых лучше всего представлены в виде графика. Данные сохраняются в графовых структурах с узлами (сущностями), свойствами (информацией о сущностях) и линиями (связями между сущностями). Примеры графовых баз данных: Neo4J и InfiniteGraph.
Базы данных Blob-объектов
Blob-объекты похожи на хранилище ключей-значений для файлов и доступны через API, такие как Amazon S3, Windows Azure Blob Storage, Google Cloud Storage, Rackspace Cloud Files, OpenStack Swift.
Как выбрать базу данных?
Когда дело доходит до выбора базы данных, приемлемого для всех решения не существует. Вот почему многие компании используют базы данных SQL и NoSQL в зависимости от конкретных целей.
Посмотрите на мое руководство ниже!
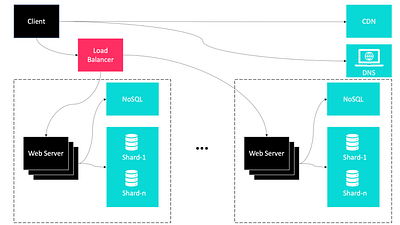
Горизонтальное масштабирование веб-уровня
Мы масштабировали уровень данных, теперь нам нужно масштабировать веб-уровень. Для этого необходимо переместить данные пользовательских сеансов (состояния) за пределы веб-уровня, сохранив их в базе данных, такой как реляционная база данных или NoSQL. Это называется системой без состояния или распределенной архитектурой.
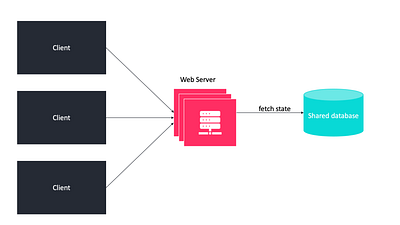
Не используйте архитектуру с сохранением состояния. Следует выбирать архитектуру без состояний, когда это возможно, потому что реализация состояния ограничивает масштабируемость, снижает доступность и увеличивает стоимость.
В приведенном выше сценарии балансировщик нагрузки может достичь максимальной эффективности, поскольку он может выбрать любой сервер для оптимальной обработки запросов.
Продвинутые концепции
Кэширование
Балансировка нагрузки — метод горизонтального масштабирования за счет увеличения количества серверов. Однако кэширование позволит вам, ограничившись уже имеющимися ресурсами, добиться ускорения обработки данных при последующих запросах.

Добавляя кэши на серверы, можно избежать чтения веб-страницы или данных непосредственно с сервера. В результате сокращается как время отклика, так и нагрузка на сервер. Это помогает сделать приложение более масштабируемым.
Кэширование может применяться на многих уровнях: базы данных, веб-сервера и сетевом уровне.
Сеть доставки контента (CDN)
Серверы CDN хранят кэшированные копии контента (изображений, веб-страниц и т.д.) и обслуживают их из ближайшего местоположения.
Использование CDN сокращает время загрузки страницы для пользователей, так как данные извлекаются из ближайшего к ней места. Это также помогает повысить доступность контента, поскольку он хранится в нескольких местах.
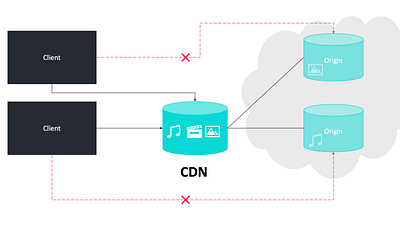
Серверы CDN отправляют запросы на веб-сервер для проверки кэшируемого контента и при необходимости обновляют его. Кэшируемый контент обычно статичен, например HTML-страницы, изображения, файлы JavaScript, CSS-файлы и т.д.
Выходите на глобальный уровень
Когда ваше приложение станет глобальным, вы будете владеть и управлять центрами обработки данных по всему миру, чтобы ваши продукты “работали” в режиме 24/7. Входящие запросы будут направляться в “лучший” центр обработки данных на основе GeoDNS.
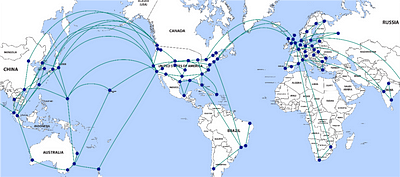
GeoDNS — это служба сервера доменных имен (DNS). В зависимости от местоположения клиентов, она преобразует доменные имена в IP-адреса. Клиент, подключившийся из Азии, может получить IP-адрес, отличный от IP-адреса, полученного клиентом, подключившимся из Европы.
Итеративный подход к разработке
Перечисленные методы, безусловно, помогут вам справиться с задачей масштабирования системы до более чем 100 млн пользователей. Масштабируйте веб-уровень с помощью распределенной архитектуры, используйте балансировку нагрузки, по максимуму применяйте кэшированные данные, обеспечьте поддержку нескольких центров обработки данных, размещайте статические ресурсы в CDN, путем шардирования масштабируйте уровень данных. Важно при этом использовать итеративный подход к разработке, то есть на каждом ее этапе проводить анализ и корректировку достигнутых результатов.
Читайте также:
- Введение в сетки в цифровом дизайне
- 8 мощных пакетов NPM для любого веб-разработчика
- Парсинг HTML из строки на Ruby On Rails
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Trung Anh Dang: How to design a system to scale to your first 100 million users





