
На одном из этапов моего проекта в школе программирования Flatiron Bootcamp мне пришлось столкнулся с проблемой, совершенно отличающейся от того, что я видел раньше. В этом проекте мне не нужен был ключ аутентификации, поэтому использовался открытый API. Но этот API возвращал какие-то специфичные данные (были строки с HTML-содержимым), тогда как все, что мне было нужно, — чтобы данные сохранялись в виде строки и ничего больше. Это было проблемой, потому что информация из API использовалась в проекте в качестве начальных данных, давая возможность отображать, что и когда мне нужно. И здесь в дело вступает ActionView::Base.

Остается только вопрос, как это поможет решить проблему. Сначала поговорим о том, что делают ActionView Helpers. Вот что написано в документации Ruby о ActionView Helpers:
«Шаблоны Action View написаны с использованием встроенного Ruby в тегах в сочетании с HTML. Во избежание перенасыщения шаблонов шаблонным кодом несколько вспомогательных классов предоставляет общее поведение для форм, дат и строк. Также по мере развития приложения в него легко добавлять новые вспомогательные средства».
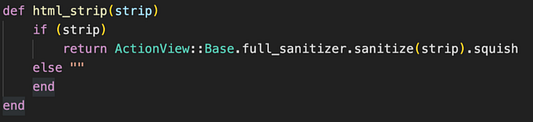
Ну вот, с ActionView Helper разобрались. Теперь узнаем, как использовать вспомогательное средство для вызова full_sanitizer. В документации Ruby сказано, что в модуле SanitizeHelper предусмотрен ряд методов для очистки текста от нежелательных HTML-элементов. Похоже, наконец-то дело сдвинулось с мертвой точки. Но как работает этот код? В процессе выполнения проекта я определил локальный метод в файле Seeds..rb (здесь же выполняю GET-запрос к API). В том виде, в каком был изначально написан, этот метод выглядел так:

Запустив этот метод, я заметил кое-что странное, пока он удалял HTML-код из строки. Код возвращал часть кода, в которой либо была куча тегов /n, либо несколько дополнительных значений с пробелами в строке. Вот как примерно выглядела строка, возвращавшаяся с этим кодом:

/n и дополнительные значения с пробелами при проверке с использованием консоли Rails.Теперь, похоже, у нас другая проблема, но в ActionView::Base имеется еще один мощный метод .squish. Он принимает все значения с пробелами и заполнителями типа /n и удаляет их, возвращая аккуратную новую строку с правильным использованием пробелов и без проблем с заполнителями. Теперь добавляем в строку функциональность .squish и видим, что при повторном тестировании значения с пробелами и заполнителями исчезли!


Теперь с проблемой покончено? Не совсем, ведь у меня еще оставалась проблема с API: метод не позволял выполнять пополнение данных базы данных, когда начальное значение строки из API было null. Решить проблему удалось, написав в методе очень простой оператор if. Его смысл в том, что если передаваемый аргумент содержит значение, то запускаются написанные мной методы ActionView::Base. В противном случае просто возвращается пустая строка во избежание проблем с файлом seed и для передачи информации в формате JSON на сервер. Финальный код и его вызов в запросе к API для получения начальных значений выглядел так:
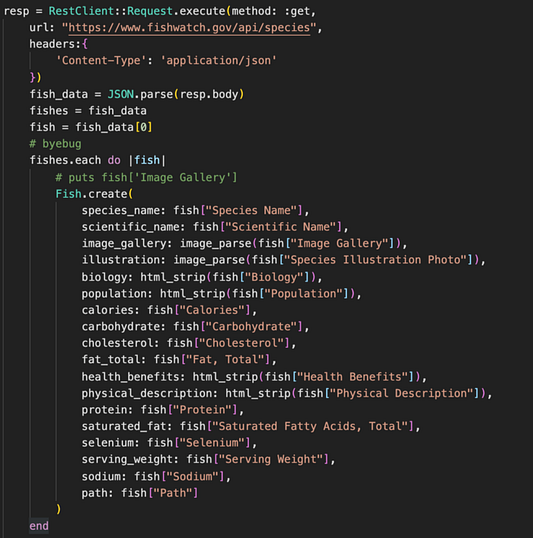
Вот и все. Теперь мы можем успешно заполучить информацию из API и удалить возвращаемые оттуда HTML-элементы. Имеются и другие вспомогательные методы, использующиеся в файле seed, для решения различных проблем, но это уже тема для другой статьи. Надеюсь, эта информация выручит вас, если вдруг возникнет аналогичная проблема!
Читайте также:
- 7 полезных атрибутов HTML, о которых не все знают
- Работа с HTML и CSS: 10 полезных приемов для дизайнеров
- 5 полезных советов для загрузки HTML-файлов
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Andrew Perlis: Parsing HTML From A String In Ruby On Rails





