
Как можно о вине сказать, что оно острое, резкое, яркое или плотное? Описания вин (особенно те, которые делают сомелье) часто состоят из как будто бы случайно собранных прилагательных, и это может запутать любителя. Раньше, когда я работал в винном магазине, видел сам, как такие описания приводят к недопониманию. Как покупатель должен узнать, понравится ли ему бутылка, если в ее описании нет никакого смысла? А если вино понравилось, то как найти похожую бутылку?
Задачи проекта
1) Найти тенденции в винных обзорах при помощи обработки естественного языка и тематического моделирования.
2) Создать систему рекомендаций, которая находит похожие (и более дешевые) вина на базе тематического моделирования из первой части.
Данные: датасет для этого проекта взяли с Kaggle. А создал его пользователь, который в 2017 году собрал журнал Wine Enthusiast. Там было 130 000 обзоров вина с такими полезными характеристиками, как мнение сомелье, регион, цена, крепость, сорт винограда. Подробности о данных и их характеристиках в датасете здесь.
Шаг 1: чистка и исследовательский анализ данных
Как в абсолютно любом проекте из сферы науки о данных, исследовательский анализ и очистка — это первые шаги в процессе. Некоторые просто ненавидят этот момент, другие — обожают. В любом случае нам просто нужно пройти через него. Большинство подходов ИАД в этом проекте было сделано просто для забавы или практики. В целом в них не было острой необходимости для ОЕЯ (обработки естественного языка), поэтому не будем говорить об этом подробно. Хотя, если вы хотите погрузиться в мой код и процесс, загляните в проект на Github.
Шаг 2: подготовка к тематическому моделированию
Что такое тематическое моделирование?
Тематическое моделирование — это такой вид модели обработки естественного языка, который анализирует слова в документах и пытается найти основные темы, которые в них содержатся. Допустим, у нас есть 4 предложения (их еще называют документами в ОЕЯ). 1) “Я люблю собак и котов” 2) “В вине чувствуются нотки земляники” 3) “У собаки чёрная шерсть” 4) “Вино пахнет кошачьим кормом”. Если мы подумаем о темах этих отрывков, то очевидно, что первый и третий о животных, второй — о вине, а четвертый может быть смешением двух тем. Тематические модели проделывают это распознавание с математической точностью.
Существует много разных вариантов тематического моделирования. К ним относятся неотрицательное матричное разложение, латентное размещение Дирихле и латентно-семантический анализ. У каждого метода есть свое уникальное математическое обоснование. Более того, каждую из этих моделей можно запустить во многих пакетах Python, например в spaCy, Gensim, scikit-learn и остальных. Для каждой утилиты шаги предварительной обработки текста немного отличаются. И хотя я испытал разные модели и утилиты, лучшая работающая модель у меня — латентное размещение Дирихле в Gensim. Этот опыт я и опишу.
Подготовка текста к тематическому моделированию
Перед погружением в тематическое моделирование, нам нужно подготовить текст, который мы будем прогонять через модели. Для этого анализа я просмотрел основные темы в описаниях вина, так что в этом датасете я использовал только колонку описания. Эта характеристика содержит описание, которое дал сомелье каждому вину.
На этапе предварительной обработки:
- Удалить знаки пунктуации, цифры, все заглавные буквы делаем строчными.
- Убрать стоп-слова: стоп-слова — это слова общего смысла, сильно распространённые для связки словосочетаний, например, “и” и “но”. В каждом программном пакете есть встроенный набор стоп-слов, которые вы можете персонализировать. Проходя итерации процесса, я настроил свой список стоп-слов размером около 15 000 слов. Оно стоило того, чтобы помочь вам прояснить темы. Посмотрите код на Github.
- Токенизация: разделяем колонки с описанием на отдельные отрезки со словами.
- Лемматизация и/или выделение основы слов: благодаря этому подходу слова по типу “бег”, “бежать”, “бегущий” система воспринимает как одинаковые и помогает уменьшить количество уникальных вхождений слов.
- Мешок слов: трансформировать текст в мешок слов так, чтобы могли сделать модель. Мешок слов воспринимает каждое слово отдельно, как в известной игре со словами — есть мешок и в нем отдельные элементы с буквами. Только в нашем случае это — целые слова. Также в этом методе система считает количество вхождений каждого слова, а после вы можете применить TF-IDF (статистическая мера, используемая для оценки важности слова в контексте документа) или произвести векторизацию, чтобы модель была более целостной. Правда, в той модели, о которой мы говорим тут, этого не было. На Github есть и другие примеры моделей с применением TF-IDF и CV.
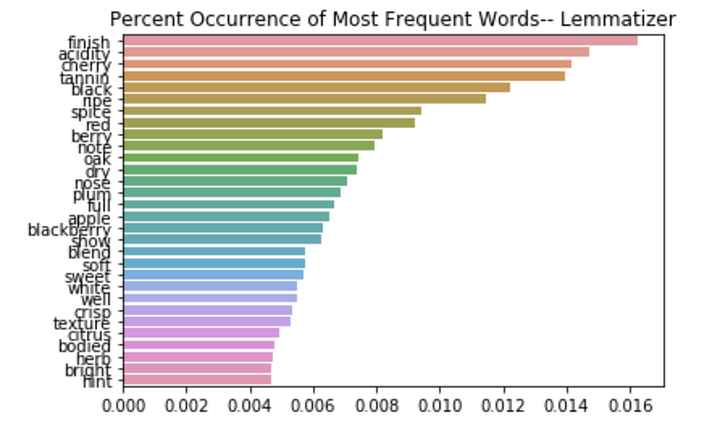
Шаг 3: запуск моделей латентного размещения Дирихле
Вот теперь текст готов к моделированию. Как я раньше упоминал, есть множество различных подходов и утилит для процедуры тематического моделирования. И дальше я расскажу о своей финальной модели LDA (СРД) в Gensim.
Что же такое ЛРД (Латентное размещение Дирихле)?
ЛРД — это вероятностная модель, которая воспринимает, что каждый документ в корпусе состоит из распределения тем, а каждая тема складывается из распределения слов. Цель моделирования — изучить комбинации тем в каждом документе и сочетание слов в каждой теме. В случае ЛРД для ОЕЯ мы берем количество тем (вот тут очень хитрый и многоуровневый процесс), а у модели должно быть тематическое распределение n числа тем. Модель анализирует текст на уровне слово-тема, а также на уровне тема-документ. Когда проходят итерации, модель спрашивает: какова вероятность того, что слово относится к теме и что конкретный документ включает в себя именно эти темы?
Приведённая внизу диаграмма помогает мне визуализировать процесс работы ЛРД. Допустим, что у нас есть три темы — каждый угол треугольника соотносим с уникальной темой. Если так, то каждый документ состоит из некоторого соотношения трёх тем. Если же в нашем документе намешано много тем, он будет выглядеть как верхний правый треугольник. Если в документе смешано две или три темы, то он будет выглядеть как нижний левый треугольник. В ЛРД существует два гиперпараметра (альфа и бета), которые влияют на комбинации тем. В своей модели я брал дефолтные.
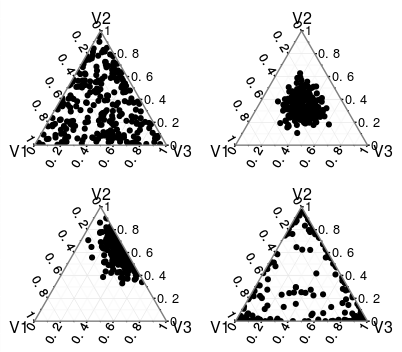
Запуск ЛДР-моделей в пакете Gensim
# Словарь - термин для числового id-мэппинга
dictionary = corpora.Dictionary(df.tokenized)
# Корпус - трансформация текстов в числовую форму (мешок слов)
corpus = [dictionary.doc2bow(doc) for doc in df.tokenized]
# Модель ЛРД - 15 тем, 20 проходов
lda_model = models.LdaModel(corpus, id2word=dictionary, num_topics=15, passes=20 )
# Вывод тем
lda_model.print_topics(15)После запуска модели, вам следует проверить свои темы на предмет наличия в них смысла. Это сложная часть обработки естественного языка, так что правильного ответа тут нет. Стоит применить свою интуицию и релевантные знания, чтобы понять, есть ли смысл в темах. Скорее всего, вам придётся попробовать несколько раз. После запуска модели (вверху), некоторые темы выглядят следующим образом:
(1,
'0.136*"oak" + 0.069*"vanilla" + 0.045*"toast" + 0.021*"toasted" + 0.020*"toasty" + 0.017*"buttered" + 0.016*"caramel" + 0.015*"richness" + 0.015*"wood" + 0.014*"oaky"'),(7,
'0.034*"finish" + 0.030*"apple" + 0.021*"sweet" + 0.019*"pear" + 0.018*"pineapple" + 0.018*"citrus" + 0.018*"nose" + 0.016*"melon" + 0.015*"white" + 0.014*"tropical"'), (9,
'0.060*"blackberry" + 0.044*"black" + 0.029*"chocolate" + 0.025*"tannin" + 0.018*"ripe" + 0.017*"cherry" + 0.017*"syrah" + 0.016*"tannic" + 0.016*"oak" + 0.015*"show"'),Для меня они выглядят осмысленно. В первой может идти речь о маслянистости, крепости, шардоне. А девятая может описывать шоколадный вкус и крепкие красные вина.
Шаг 4: рекомендация похожих по вкусу вин и при этом менее дорогих
Представьте, что идёте на ужин в гости к своему начальнику и пробуете изумительное вино. А завтра вы заглядываете в отзыв на это вино и узнаете, что стоит оно 13 000 рублей. Возможно, вы захотите найти что-то похожее и при этом более доступное. Выискивание точного вкуса и прочёсывание запутанных описаний может быть долго и сложно.
Системы рекомендаций
И вот теперь тематическое моделирование полностью выполнено, а мы можем применить результаты в создании системы рекомендаций. Есть два основных типа таких систем: основанные на контенте и перекрестной фильтрации. Для этого проекта я создал систему рекомендаций по контенту. Такие модели используют дополнительную информацию о пользователях и/или характеристиках (например, демографический параметр) и не опираются на мнение пользователей. В моей модели нет никакой пользовательской информации, а контент — распределение тем в описаниях вина. Поэтому модель советует вина с похожими разбивками тем.
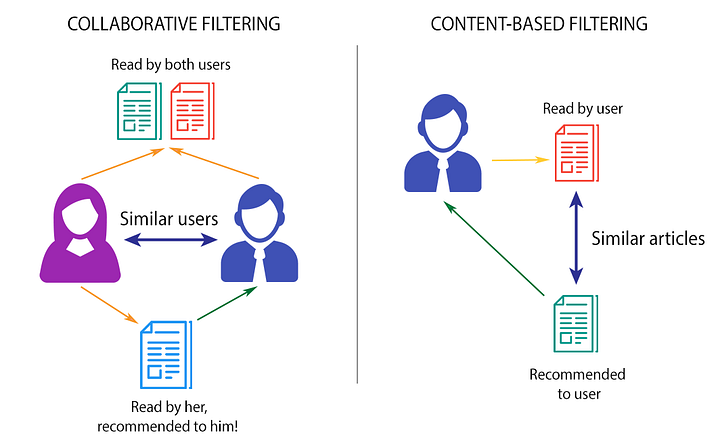
Если простыми словами, то системы рекомендаций сравнивают предметы по некоторой характеристике расхождения. Так тут может быть косинусное сходство, евклидово расстояние, расхождение Дженсена-Шеннона, расстояние Кульбака-Лейблера и многие другие варианты. Они все говорят только о том, насколько близки предметы в пространстве. Для своего проекта я взял расхождение Дженсена-Шеннона, потому что это способ измерит расхождение в вероятностном распределении, что, как известно, присуще тематическому распределению в каждом документе в модели ЛРД.
Чтобы имплементировать это в Python, я воспользовался измерением энтропии в SciPy. Без глубокого погружения в математику (ха-ха, после этих-то понятий из предыдущего абзаца), просто запомните, что Дженсен-Шэннон основывается на расстоянии Кульбака-Лейблера, а энтропия SciPy просто измеряет это расстояние Кульбака -Лейблера. Ранжируется этот показатель от нуля до единицы, где 0 значит, что два распределения являются самыми близкими друг к другу или наиболее схожими.
Этапы запуска рекомендационной системы
Первый момент для получения расхождения Дженсена-Шеннона — это трансформация нашей матрицы из ЛРД в частотную матрицу тем документа Х. В этой получившейся матрице каждая строчка является обзором на вино, а колонки — разбивки тем для каждого из вин. И раз у нас есть эта матрица, то мы запускаем метрику расхождения (хотя бы расхождения Дженсена-Шеннона) между векторами документов.
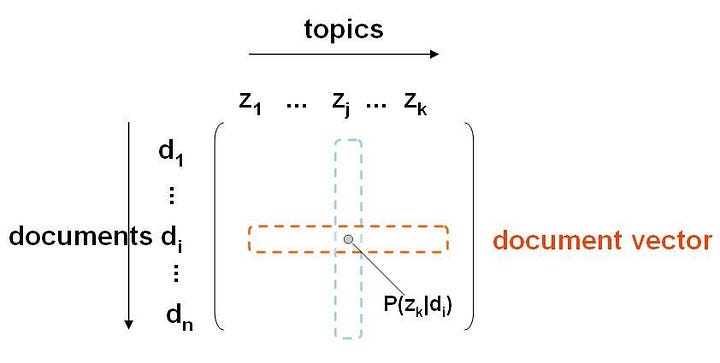
Включая эти простые шаги:
# Конвертация из bow в разреженную матрицу, в плотную матрицу, в pandas
# Трансформация из bow
corpus_lda = lda_model_tfidf[corpus]
# Конвертация корпуса bow в разреженную матрицу с документами в колонках
csc_mat_lda = gensim.matutils.corpus2csc(corpus_lda)
# Перевод документов в строки и конвертация в массив np
# Теперь у нас есть матрица тем документа Х
doc_topic_array_lda = csc_mat_lda.T.toarray()
# Конвертация в pandas для простоты и возможности прочитать
df_lda = pd.DataFrame(doc_topic_array_lda)
Перевод названий колонок в темы #s для pandas df
df_lda.columns = [f'topic_{x}' for x in np.arange(0,len(df_lda.columns))]Если нам доступно любое вино в датафрейме, то мы запросто увидим сочетание тем в его описании.
# Случайный выбор вина для проверки разброса тем
df_lda.loc[123]
________________________________
# Выглядит так, что в основном описание этого вина состоит из тем 6, 9 и 14
topic_0 0.000000
topic_1 0.000000
topic_2 0.000000
topic_3 0.082272
topic_4 0.067868
topic_5 0.000000
topic_6 0.253451
topic_7 0.000000
topic_8 0.107688
topic_9 0.287275
topic_10 0.000000
topic_11 0.000000
topic_12 0.000000
topic_13 0.000000
topic_14 0.179217Мы приходим к моменту формирования рекомендаций
Теперь, когда у нас есть матрица тем нашего документа Х, всего-то нужно запустить несколько функций, чтобы выдать наиболее схожие вина для запроса.
def jensen_shannon(query, matrix):
import numpy as np
import scipy.stats
"""
Вычисляет РДШ (расстояние Дженсена-Шеннона) при помощи энтропии SciPy. Находит РДШ между входящим запросом (распределение тем ЛРД в отдельном документе) и целой матрицей(корпус распределений по темам).
"""
p = query[None,:].T # транспонирование
q = matrix.T # транспонирование матрицы
print(type(p), type(q))
m = 0.5*(p + q)
return np.sqrt(0.5*(scipy.stats.entropy(p,m) + scipy.stats.entropy(q,m)))
def get_most_similar_wines(query,matrix,k=20):
"""
Эта функция имплементирует РДШ-функцию и возвращает максимальный коэффициент наименьшего РДШ. Для поиска рекомендаций, используйте INDICIES.
"""
sims = jensen_shannon(query,matrix) # список РДШ для запроса от ВСЕЙ матрицы
distances = sorted(sims,reverse=True)
most_similar_k = sims.argsort()[:k]
exploration_k = sims.argsort()[30: 30+k]
return sims.argsort()[:k] # максимальный коэффициент отметок наименьших РДШ.Функции для 1) поиска РДШ (Расстояние Дженсена-Шеннона) между определенным вином и остальными в корпусе и 2) поиска наиболее схожих вин.
На выходе из этих функций мы получим коэффициент самых схожих вин в количестве k. Выглядит примерно следующим образом:
# Получить распределение тем по вину из запроса, чтобы потом найти похожие
to new_wine = doc_topic_array_lda[123].T
most_similar_wine_ilocs = get_most_similar_wines(new_wine,full_matrix)
________________________________
array([123, 3436, 52985, 59716, 101170, 37219, 43017, 99717, 80216, 9732, 101690, 40619, 66589, 14478, 1068, 1157, 67821, 100428, 8895, 8894])Когда выполняется эта функция, возьмите на заметку, что new_wine — это распределение тем по запросу о вине, к которому мы хотим найти рекомендации. Возможно, это вино, которое вы пили у начальника дома.
Отлично, и теперь еще один шаг перед получением финальных рекомендаций. Индексы pandas, которые мы получаем из предыдущих функций, — это ilocs из матрицы тем документа Х. Помните, в ней есть только распределения тем в колонках, а о самих винах информации нет. Нам нужно соединить этот датафрейм с оригинальным датафреймом, так что когда мы получим самые схожие вина, в нашем распоряжении будет полная информация. Это важно для случая, когда мы хотим показать пользователю описание вина, а при этом использовать описательную информацию (такую как цена) в роли фильтра. Только удостоверьтесь, что все это соединилось правильно, или у вас будут несовпадения. Когда все закончится, можете создать итоговую функцию, которая инкапсулирует все, а на входе забирает вилку цен.
Пример работы системы рекомендаций
И вот лучший способ проиллюстрировать окончательную модель — протестировать ее на примере. Я выбрал вино Malbec из Аргентины (цена около 14 000 рублей) и прогнал его описание через финальную систему рекомендаций. Также я добавил фильтр по цене, чтобы найти вино с похожим вкусом менее чем за 3 000 рублей. И лучшая рекомендация была о вине Каберне Савиньон из Вашингтона за чуть больше чем 3000 рублей.
Я вывел распределение тем для обоих вин и они схожи в достаточной мере. А это значит, что система рекомендаций работает. Конечно, неидеально, а все тематическое моделирование можно разбивать на новые и новые итерации много раз, чтобы получить лучшие и более точные темы, которые, в свою очередь, вернут лучшие рекомендации.
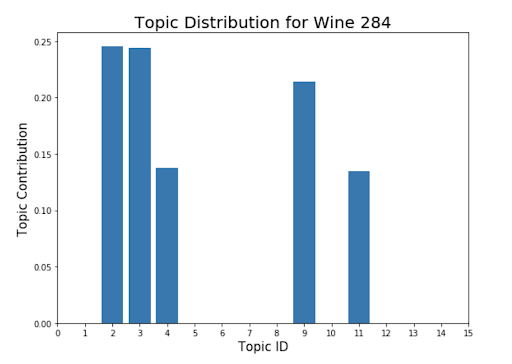
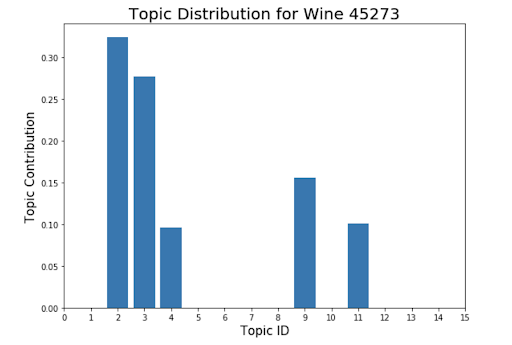
Заключение
Мы устанавливали цели проекта:
- применить тематическое моделирование ОЕЯ для поиска общих тем в винных обзорах,
- создать систему рекомендаций, основанную на контенте, для поиска похожих сортов вина.
В моём материале я рассказал об этапах предварительной обработки текста, кратко прошелся по ЛРД (Латентному распределению Дирихле — Latent Dirichlet Allocation), а также по совместному с ним тематическому моделированию в Gensim. В итоге, я прошел этапы создания рекомендационной системы на основе контента. Благодаря реализации этого проекта, я достиг своих двух поставленных целей и получил финальную модель, которая даёт рекомендации вина на основе вкусовых профилей из текстовых описаний.
Весь код находятся у меня на Github.
Читайте также:
- Развёртывание модели машинного обучения в виде REST API
- Почему мы создаем инфраструктуру машинного обучения в Go, а не в Python
- Как построить модель машинного обучения, если под рукой нет доступных данных
Перевод статьи Alen Tersakyan: How can a wine be pointy and sharp?





