
Преимущества объединения хранилищ данных в последнее время привлекают большое внимание организаций всех уровней. В 2018 году корпорация Google разработала проект передачи данных (Data Transfer Project), а недавно технологический титан Microsoft запустил кампанию открытых данных (Open Data Campaign), направленную на то, чтобы к 2022 году подготовить к эксплуатации большие совместимые наборы данных.
Объем & разнообразие данных — цель любой организации
На приемном конце конвейера данных находятся модели машинного обучения. Подобно тому, как опрос общественного мнения выигрывает от большего количества ответов, знакомство с большим количеством образцов помогает модели машинного обучения точнее делать прогнозы. Разнообразие образцов в наборе данных также является ключевым фактором. Исследователи общественного мнения заинтересованы не просто в расширении аудитории респондентов, но и в ее разнообразии. То же можно сказать о модели: имея дело с похожими образцами, она окажется в тупике при первом же столкновении с выбросом в данных.
Обе задачи — расширение объема набора данных и достижение их разнообразия — проблематичны для организаций. Получение новых образцов может оказаться дорогостоящим делом. Если у вас универмаг и ваша модель извлекает уроки из набора данных покупок, вы не можете легко получить больше образцов, иначе вы бы уже сделали это. Разнообразие наборов данных часто совершенно невозможно, поскольку клиенты разных универмагов принадлежат к разным демографическим группам.
Мы можем решить эти проблемы, рассматривая доступ к данным как товар. Если компания хочет обучить модель, но ей не хватает данных, она может заплатить другой организации за предоставление доступа к ее данным. Мы убиваем сразу двух зайцев: во-первых, компания теперь имеет доступ к гораздо большему набору данных, обучаясь на данных нескольких организаций. Кроме того, полученные из автономных источников образцы более разнообразны. В результате модель становится более точной и устойчивой к выбросам.
На первый взгляд, рынок данных должен немедленно вызвать недоумение, поскольку наборы данных часто содержат личную или коммерчески конфиденциальную информацию. Однако речь идет не том, чтобы делиться самими данными, а только выводами из них; не покупками отдельных посетителей магазинов или историями болезней, а общими тенденциями. Такое стало возможным только совсем недавно, благодаря быстрому прогрессу в области вычислений, обеспечивающему сохранение конфиденциальности, что позволяет изучать закономерности в данных, скрывая при этом индивидуальную информацию.
Это беспроигрышный вариант: потребитель данных получает доступ к большему количеству и лучшему качеству информации. Поставщик данных устанавливает их стоимость, не раскрывая своих секретов.
Дополнительной проблемой являются инженерные издержки. Наборы данных отличаются друг от друга, имеют несовместимые функции и особенности. Нецелесообразно перестраивать модель каждый раз, когда мы хотим использовать новый набор данных, чтобы впустую не растрачивать инженерные усилия. К тому же, эти усилия придется умножить при обучении на нескольких наборах данных, которые могут использовать разные форматы для одной и той же информации.
Обучение на основе многообразий — метод, который позволяет нам автоматизировать задачу извлечения полезной информации из разрозненных наборов данных. Инженерам больше не нужно беспокоиться о кодировании функций данных. Вместо этого, записи превращаются в векторы чисел, значение которых согласовано между наборами данных. Обучение на новом наборе данных происходит быстрее и дешевле.
Барьеры на пути межорганизационного обмена данными
Теперь детально остановимся на основных трудностях межорганизационного обмена данными в глобальном масштабе. В завершение посмотрим, как Ntropy создает платформу, которая позволяет легко обучать модель на нескольких наборах данных и монетизировать данные через организационные барьеры, не ставя под угрозу приватность или конфиденциальность.
В настоящее время для доступа к дополнительным наборам данных возможны следующие решения:
- Поиск общедоступных данных. Альтернативы варьируются от преимущественно академических наборов данных, таких как репозиторий машинного обучения UCI, до коммерческих наборов данных в таких местах, как Kaggle и Google Dataset Search. Подобные хранилища данных предназначены для запуска моделей на отдельных наборах данных. При этом создается мало стимулов для внесения наборов данных в эти пулы. Вот почему объем их данных довольно ограничен.
- Коммерческие решения, ведущие к обмену данными между коммерческими компаниями, начиная с LiveRamp, LexisNexis и Experian и заканчивая более поздними проектами, такими как Snowflake и AdSquare, а также децентрализованными проектами типа Ocean. В отличие от общедоступных пулов данных, коммерческий обмен данными является двусторонним, и у поставщиков данных есть определенный стимул предоставлять свои данные. Однако барьеры для входа и издержки для обеих сторон коммерческого обмена весьма значительны.
Потребителям данных, чтобы получить постоянный доступ к любой полезной информации, придется выделять периодические ресурсы, включающие в себя:
- обнаружение, тестирование и интеграцию новых наборов данных;
- изучение лицензий от различных поставщиков данных;
- выяснение совместимости функций между наборами данных;
- решение проблем, связанных с транзакцией необработанных данных;
- постоянную проверку качества и подлинности данных.
Перед поставщиками данных стоит не меньше задач:
- обеспечение соблюдения лицензионных требований;
- установление оптимальной стоимости данных;
- прогнозирование спроса;
- обеспечение мобильности и анонимности транзакций;
- предупреждение рисков конфиденциальности и конкурентной чувствительности своих данных.
Неэффективность последних технологических достижений в области МО заключается в основном в том, что наборы данных сохраняются и проверяются людьми, и, следовательно, данные кодируются в удобочитаемом для человека формате. Однако модель учится только на распределении данных в целом, независимо от кодирования каждого отдельного образца.
Чтобы обеспечить уровень надежных данных, на основе которого можно создавать модели машинного обучения без дополнительных издержек, наборы данных должны рассматриваться как взаимодополняющие, связанные потоки информации, закодированные в “машинно-оптимальном”, а не удобочитаемом формате. Следование этому принципу открывает существенные преимущества перед нынешними решениями.
Обучение на основе многообразий
Рассмотрим возможности двух компаний, ведущих деятельность на одном рынке с соответствующими наборами данных о своих клиентах (A и B). Несмотря на сходство основных предложений, клиентские базы у них разные. В каждой компании есть команда управления продуктом, которая оценивает различные характеристики каждого клиента. Некоторые, если не все из этих характеристик, являются достаточно сложными и проприетарными. В каждой компании есть также команда обработки и анализа данных, которая обучает собственную модель, позволяющую ее продукту прогнозировать поведение клиентов и реагировать соответствующим образом.
Как было замечено выше, каждая из этих двух моделей могла бы быть значительно эффективней, если бы, в дополнение к собственным данным, имела доступ к данным другой компании. Как же нам объединить два набора данных, не раскрывая конкретной информации о каждом клиенте и не вовлекая в процесс какое-либо “отображение признаков”, связанное с человеческим фактором?
Давайте сделаем шаг назад и вспомним одну из самых фундаментальных теорем в программной инженерии:
“Мы можем решить любую проблему, введя дополнительный уровень косвенности” (Дэвид Уилер).
Хотя наши наборы данных A и B кодируются с использованием совершенно разных проприетарных характеристик, их распределения, вероятно, будут иметь много общего.

Таким образом, модель, обученная на обоих наборах данных одновременно, может применять понятия, извлеченные из двух наборов данных, повышая производительность исходного набора данных. Следовательно, если два набора данных имеют сходные распределения, должно существовать “скрытое пространство”, где выводы из обоих наборов данных могут быть сопоставимы. Кроме того, если у вас нет доступа к “кодировщикам”, которые отображают каждый набор данных в этом скрытом пространстве, будет очень трудно перепроектировать отображение и составить удобочитаемое представление каждого вывода. Но именно это и обеспечивает уровень конфиденциальности, открывающий публичный доступ даже к самым конфиденциальным наборам данных. Такой подход, также называемый обучением на основе многообразий, применим в отношении многих общедоступных наборов данных. Возьмем для примера вот этот набор данных из Worldline, осуществляющей транзакции по кредитным картам. Хотя каждый удобочитаемый вывод будет чувствительным, поскольку содержит персональные данные пользователя, информация об устройстве и самой транзакции, при кодировании в скрытом пространстве, может быть общедоступной без дополнительного риска.
На практике существует множество способов объединения нескольких наборов данных в скрытом пространстве с различным уровнем точности и масштабируемости. Возможно, самый простой подход, жизнеспособный для небольшого числа наборов данных, заключается в использовании стандартной архитектуры автокодировщика нейронной сети. Поскольку скрытое пространство представляет собой сжатое представление каждого вывода, устройство кодирования данных вынуждено использовать сходство между входными данными, чтобы составить оптимальное представление. Как мы уже отмечали выше, наборы данных с аналогичными распределениями должны иметь большую часть этого скрытого представления.
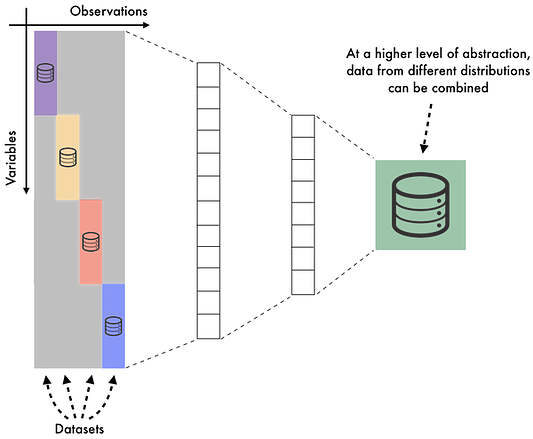
Решение проблемы конфиденциальности информации
Применим этот подход к решению реальной очень давней и чрезвычайно болезненной коммерческой проблемы — обнаружению мошенничества. Для теста у нас будет 4 набора данных, представляющих 4 различных распределения транзакций по кредитным картам от 3 различных компаний: FICO, Worldline и Vesta; в среднем 125 переменных и 250 000 транзакций на набор данных. Каждая транзакция помечается как мошенническая или законная. Чтобы определить, насколько хорошо наша модель выявляет мошеннические транзакции, мы будем использовать стандартную метрику ROC AUC.
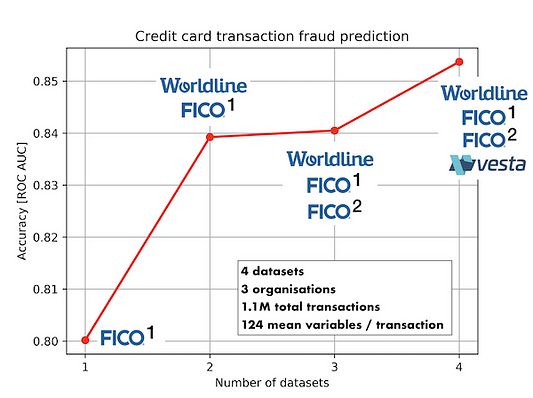
Взяв один из двух наборов данных от FICO в качестве базового, мы можем наблюдать устойчивое улучшение производительности модели с каждым дополнительным набором данных, на которых она обучается, с повышением более чем на 5 % точности по всем 3 дополнительным наборам данных. Поскольку каждый запрос эффективно получает доступ к информации из всех наборов данных одновременно, мы ожидаем, что эта точность будет продолжать увеличиваться с каждым новым набором данных, который мы добавляем в сеть.
Аналогичное улучшение показателей совсем недавно было продемонстрировано в медицинском исследовании, которое было представлено на ежегодной конференции SIIM 20. Одна из моделей МО была обучена предсказывать уплотнения в груди по наборам данных маммограмм, сделанных в четырех различных учреждениях. Хотя распределения были явно разными, модель, обученная на объединенных данных, была значительно эффективней любой модели, обученной только на своем наборе данных.
Итак, мы установили, что многие проблемы, связанные с межорганизационным обменом данных, заключаются в обеспечении удобочитаемости для человека каждой точки данных. Просто введя дополнительный уровень косвенности и переместив вычисления, хранение и передачу данных в скрытое пространство, можно создать значительно более эффективную сеть передачи данных, чем то, что мы имеем на сегодняшний день.
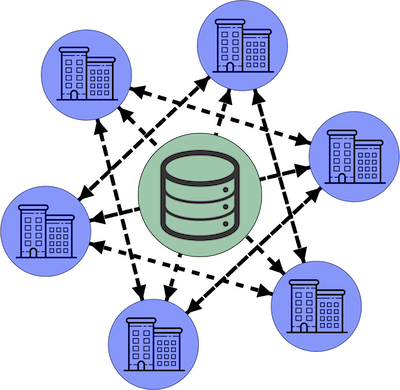
Все участники такой сети получают удобочитаемый доступ только к данным из своего собственного распределения и доступ к объединенным данным всех распределений в скрытом пространстве. Таким образом, поддерживается базовый уровень конфиденциальности. Наблюдения могут быть закодированы с использованием любого проприетарного набора характеристик, не требуя какого-либо участия человека для их перевода. Кроме того, поскольку каждый набор данных вносит информацию во всю сеть и каждый запрос подключается к этому объединенному информационному пулу, расходы, связанные с конкурентной чувствительностью — одной из фундаментальных проблем любой сети передачи данных, — намного превышают издержки, необходимые для присоединения к сети как в качестве потребителя данных, так и в качестве поставщика данных.
Заключительные выводы
За последние несколько десятилетий прогресс в области технологических инноваций опирался на демократизацию доступа к некоторым из его ключевых компонентов:
- знаниям (открытые платформы публикации);
- алгоритмам (репозитории кода);
- вычислениям (поставщики облачных услуг).
Доступ к еще одному компоненту — данным — становится все более приоритетным как для крупных, так и для малых предприятий. Подавляющее большинство ценных данных сегодня находится в закрытых хранилищах, разделенных барьерами регулирования, конфиденциальности, стандартов схем и конкурентных рисков.
Ntropy строит сеть, позволяющую компаниям получать доступ к соответствующим данным с минимальными инженерными затратами или рисками для конфиденциальности. Это стало возможным только в последние несколько лет благодаря достижениям в области обучения алгоритмов на основе многообразий и вычислений, сохраняющих конфиденциальность.
Читайте также:
- 4 важных навыка, которые специалисты по обработке данных часто недооценивают
- Внутренняя платформа МО Bigeye: цели и методы создания
- 7 советов для эффективной визуализации данных
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Ilia Zintchenko: Dissolving data silos





