
На высоком уровне мы рассмотрим вывод каждой стадии компиляции простой программы C++ при использовании Clang. При этом мы также проследим код в дизассемблированном виде и разберем составляющие ELF-файла.
При полном компилировании кода создается исполняемый двоичный файл. Например, эта простая программа…
#include <iostream>
#define MSG "What's Up?"
void addTen(int& num) {
num += num + 10;
}
int main(int argc, const char* argv[]) {
int a_something = 5;
std::cout << MSG << "\n";
addTen(a_something);
std::cout << a_something << "\n";
return 0;
}
… преобразуется в двоичный код, который при просмотре в hex-редакторе выглядит так:

При выполнении этой программы получим ожидаемый вывод:
What’s Up?
20
На этом этапе весь код и данные преобразованы в двоичный файл такого формата, который может быть выполнен системой. Это не очень понятно, поэтому для большей ясности попробуйте изменить статическую строковую часть программы для получения другого вывода.
Например, в этом двоичном файле я изменил код 5768 6174 2773 2055 703f 000a, представляющий строку What's up? на 576f 6e64 6572 6675 6c21 000a. Теперь при выполнении мы видим следующий вывод:
Wonderful!
20
Вот только не знаю, нужно ли мне волноваться из-за внесенной корректировки? В данном случае я просто поменял код ASCII. Изменить же поведение будет намного труднее, так что волноваться наверняка не стоит.
Тем не менее мы говорили именно о процессе компиляции исходного файла в двоичный. Хотя я все же буду придерживаться взгляда сверху.
В ходе преобразования в исполняемый формат исходный код проходит несколько стадий. В документации Clang эти шаги называются так:
1. Pre-Processing (Препроцессинг);
2. Parsing and Semantic Analysis (Парсинг и семантический анализ);
3. Code Generation and Optimization (Генерация и оптимизация кода);
4. Assembly (Ассемблирование);
5. Linking (Линковка).
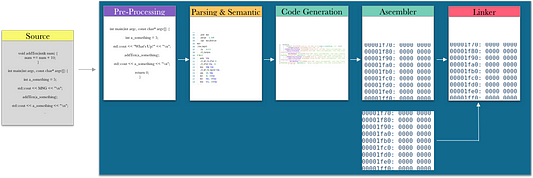
Рассмотрим, что получается на выходе каждой этой стадии.
Препроцессинг
В документации Clang данный этап охарактеризован так:
“На этой стадии происходит токенизация входного исходного файла, расширение макросов, расширение #include и обработка других директив препроцессора”.
Вывод программы в конце данной стадии показывает, что макросы были расширены. Обратите внимание, что здесь у нас строка std::cout << “What’s Up?” << “\n”;, хотя в исходном коде она выглядела как std::cout << MSG << “\n”;.
…..namespace std __attribute__ ((__visibility__ (“default”))){# 60 “/usr/bin/../lib/gcc/x86_64-linux-gnu/9/../../../../include/c++/9/iostream” 3extern istream cin;
extern ostream cout;
extern ostream cerr;
extern ostream clog;
extern wistream wcin;
extern wostream wcout;
extern wostream wcerr;
extern wostream wclog;
static ios_base::Init __ioinit;
}# 2 “pass_by_reference_example.cpp” 2void addTen(int& num) {num += num + 10;}int main(int argc, const char* argv[]) {int a_something = 5;std::cout << “What’s Up?” << “\n”;addTen(a_something);std::cout << a_something << “\n”;return 0;}
…Обратите внимание: мне пришлось обрезать много верхних строчек, которые были шаблонной частью C++.
Парсинг и семантический анализ
Обратимся к той же документации:
“На этой стадии происходит парсинг входного файла с преобразованием токенов препроцессора в дерево парсинга. Затем с помощью семантического анализа вычисляются типы для выражений, а также определяется, насколько качественно сформирован код. Эта стадия отвечает за генерацию большей части предупреждений компиляции и ошибок парсинга. На выводе здесь получается “Абстрактное синтаксическое дерево” (AST)”.
Ниже показано, как переменная a_something представлена в иерархии. То же касается и остального кода. Я снова обрезал много строк, чтобы сохранить вывод в понятном и простом виде.

Генерация и оптимизация кода
Из документации:
“На этой стадии AST переводится в низкоуровневый промежуточный код (называемый “LLVM IR”) и, наконец, в машинный код. Данный этап отвечает за оптимизацию сгенерированного кода и генерацию кода, соответствующего целевой форме. На выходе получается файл .s или, иначе говоря, файл ассемблера”.
После этой стадии мы получаем целевой ассемблерный код. Ниже приложен скриншот вывода, но несколько позже мы пройдемся по этому коду из objdump, так как в нем обычный код чередуется с ассемблерным. Вот область, где мы проследим часть написанного кода.

Ассемблирование
Из документации:
“На этой стадии ассемблер преобразует вывод компилятора в целевой объектный файл. На выходе получается объектный файл .o.
Мы работаем под Ubuntu. Следовательно, тип получаемого объектного файла будет ELF, в частности, следующий:
ELF 64-bit LSB relocatable, x86–64, version 1 (SYSV), with debug_info, not stripped
Это перемещаемый файл, а значит в нем разрешаются не все адреса памяти. На скриншоте ниже показана информация из его заголовка:
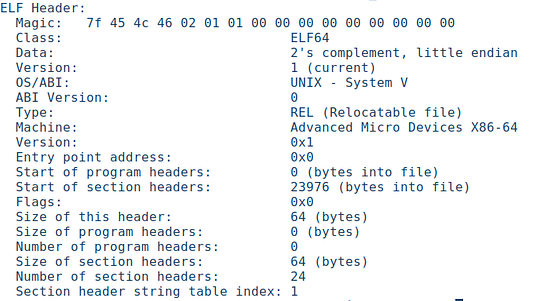
Как видите, Entry point address определен как 0x0, потому что это еще не исполняемый файл, и точка входа его виртуальной области памяти еще не известна.
Линковка
Снова смотрим в документацию:
“На этой стадии линковщик выполняет слияние нескольких объектных файлов в одну исполняемую или динамическую библиотеку. Выводом здесь будет файл a.out, .dylib или .so.
В завершении линковщик получает объектный файл(ы) и создает исполняемый, разрешая все разрешаемые адреса.
Двоичный ELF-файл состоит из заголовка, ни одного или нескольких программных заголовков, а также ни одного или нескольких заголовков разделов. Вкратце рассмотрим эти компоненты.
Заголовок
На скриншоте ниже показан вывод заголовка ELF исполняемого файла. В нем содержится информация о типе файла, местонахождении его содержимого и пр.
Поле Magic является 16-байтовым массивом, содержащим 4-байтовое магическое значение, которое указывает, что это файл ELF.
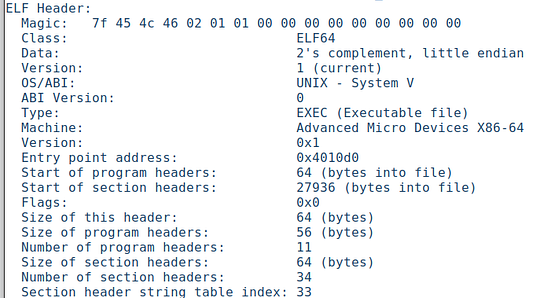
Как видите, теперь в заголовке есть точка входа: 0x4010d0 — это адрес виртуальной памяти, откуда должно начинаться выполнение. Тип файла — исполняемый.
Разделы
Разделы логически организуют данные и код, создавая структурированное представление для линковщика. Рассмотрим разделы нашего двоичного файла с помощью readelf.
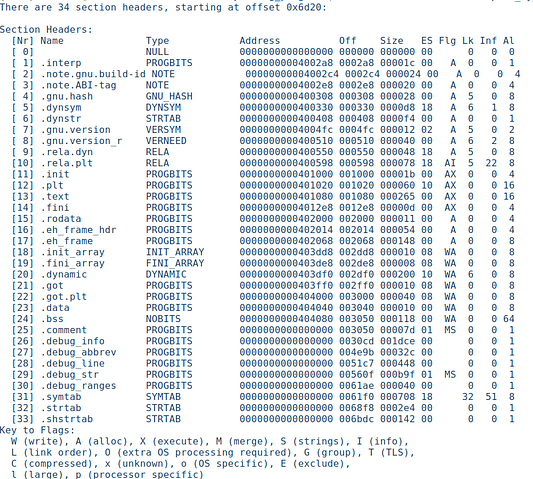
Возьмем некоторые из наиболее известных:
.text
.text содержит основной исполняемый код. Вывода здесь очень много, так что я просто приведу скриншоты основных компонентов, которые можно узнать. Начнем с адреса точки входа, который мы уже видели в заголовке ELF. Вот его дизассемблированный вид:
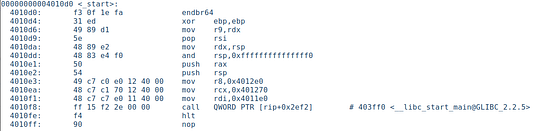
Так что на самом деле это не основная функция — это некий _start, вероятно, устанавливающий и/или инициализирующий программу.
Регистр rdi служит для передачи первого аргумента, и он же содержит адрес основной функции, как показано на скриншоте ниже.
4010f1: 48 c7 c7 e0 11 40 00 mov rdi,0x4011e0
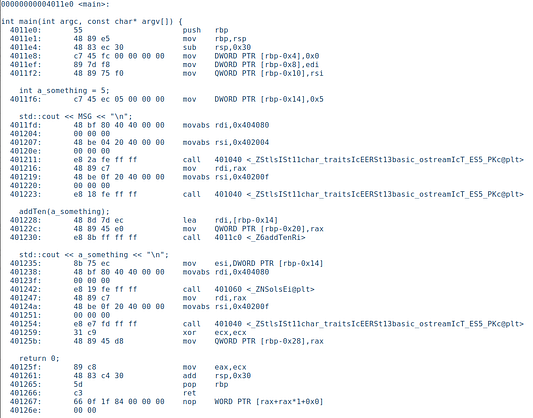
Здесь видно, что a_something создается в [rbp-0x14], и его значение устанавливается на 0x5.
int a_something = 5;4011f6: c7 45 ec 05 00 00 00 mov DWORD PTR [rbp-0x14],0x5
В коде происходит вызов addTen и передача в него ссылки на a_something. Вот дизассемблированный вид:
addTen(a_something);401228: 48 8d 7d ec lea rdi,[rbp-0x14]
40122c: 48 89 45 e0 mov QWORD PTR [rbp-0x20],rax
401230: e8 8b ff ff ff call 4011c0 <_Z6addTenRi>Не уверен, для чего строка 40122c перемещает временный rax в [rbp-0x20], но нам известно, что lea загружает действительный адрес в [rbp-0x14] — то есть адрес a_something в rdi, который используется для передачи первого аргумента и вызова метода addTen:
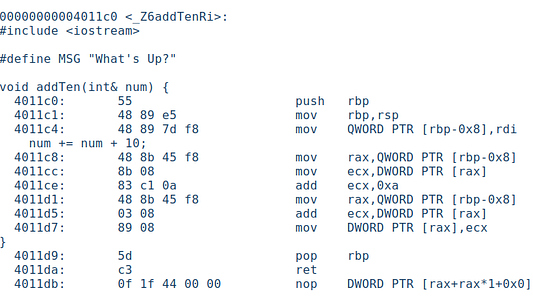
Здесь выполняется обработка указателей: rbp — это базовый указатель, а rsp — это указатель стека, всегда указывающий на его верхушку.
4011c0: 55 push rbp
4011c1: 48 89 e5 mov rbp,rsp
rdi содержит адрес a_something. Этот адрес копируется в [rbp-0x8], а затем в регистр rax.
4011c4: 48 89 7d f8 mov QWORD PTR [rbp-0x8],rdi
4011c8: 48 8b 45 f8 mov rax,QWORD PTR [rbp-0x8]
Теперь содержимое адреса a_something копируется в регистр ecx.
4011cc: 8b 08 mov ecx,DWORD PTR [rax]
Значение 0xa в десятичной форме — это 10, и оно добавляется к содержимому ecx, который содержит значение a_something.
4011ce: 83 c1 0a add ecx,0xa
Далее результат помещается в адрес регистра rax:
4011d7: 89 08 mov DWORD PTR [rax],ecx
Интересно, что ассемблерный код из вывода Clang содержал расширенный макрос msg, а в ассемблерном выводе objdump он остался без изменений.
.rodata
Этот раздел содержит данные только для чтения. Для нас это строка msg.

.bss
Содержит неинициализированные данные.
Сегменты
Сегменты предоставляют информацию, которую операционная система и динамический линковщик используют, чтобы настроить и загрузить процесс для выполнения. В нашем случае выглядит это так:
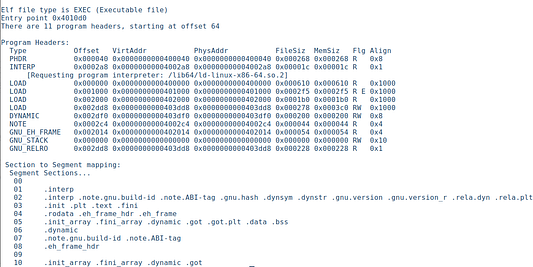
Типы LOAD являются сегментами, загружаемыми в память. Здесь видно, что основной код содержится в сегменте 03, который состоит из разделов .init, .plt, .text и .fini. Он настроен для считывания (R) и выполнения (E).
Раздел .rodata находится в сегменте 04 — .rodata, .eh_frame_hdr, .eh_frame — и установлен на считывание (R).
Заключение
На этом все. Очевидно, что здесь еще во многое можно углубиться, но даже такой общий обзор уже сам по себе интересен. Если у меня появится возможность, я напишу, как этот небольшой процесс выглядит в памяти.
Читайте также:
- Дизайн физического движка
- Распознаём 50 видов текста на C++ с Plywood
- Создаём конвейер автоматизированных сборок для проекта на Arduino. Часть 1/2
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Amber: What’s the Journey of a Single Line of Compiled Code Like?





