
Посмотрим на скромный текстовый файл:

Этот файл может содержать удивительное количество различных форматов. Текст может быть закодирован как ASCII, UTF-8, UTF-16 (с прямым или обратным порядком байтов), Windows-1252, Shift JIS или любой из десятков других кодировок. Файл может начинаться или не начинаться с метки порядка байтов (BOM). Строки текста могут заканчиваться символом конца строки \n, типичным для UNIX, последовательностью \r\n, типичной для Windows или, если файл создан в старой системе, какой-то другой последовательностью символов. Иногда невозможно определить кодировку в конкретном текстовом файле. Предположим, файл содержит такие байты:
A2 C2 A2 C2 A2 C2
Это может быть:
- UTF-8, содержащий
¢¢¢; - UTF-16 с прямым порядком (или UCS-2) с символами
ꋂꋂꋂ; - UTF-16 обратного порядка байтов с
슢슢슢; - Windows-1252 с
¢¢¢.
Пример искусственный. Суть в том, что текстовые файлы в своей основе неоднозначны. Неясности создают проблему для программного обеспечения, загружающего текст. Она существует уже некоторое время. К счастью, ландшафт текстовых файлов со временем стал проще. UTF-8 одержал победу над другими кодировками. Более 95% Интернета использует UTF-8. Впечатляет скорость, с которой изменилась цифра: она составляла менее 10% в 2006 году.
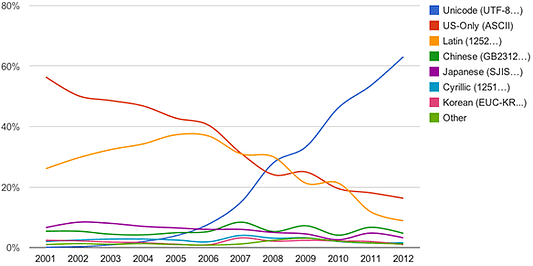
Но UTF-8 ещё не захватил мир. Редактор реестра Windows по-прежнему сохраняет текстовые файлы в кодировке UTF-16. Когда же текстовый файл пишется в Python, кодировка по умолчанию зависит от платформы. На моей машине с Windows это Windows-1252. Говоря коротко, проблема неопределённости текста всё ещё актуальна. И даже если файл закодирован в UTF-8, всё равно есть вариации: он может начинаться или не начинаться с BOM; или может иметь разные стили окончания строк.
Как Plywood загружает текст?
Plywood — это кросс-платформенный фреймворк с открытым исходным кодом, выпущенный мной два месяца назад. При открытии текстового файла с помощью Plywood у вас есть несколько вариантов:
- Если вы знаете формат, вызывайте
FileSystem::openTextForRead(), передавая ожидаемый формат в структуруTextFormat. - Если вы не знаете формат, вызывайте
FileSystem::openTextForReadAutodetect(). Функция попытается определить формат и вернуть его.
Возвращаемый этими функциями входной поток никогда не начинается с BOM, всегда кодируется в UTF-8 и завершает каждую строку ввода одним символом возврата каретки \n, независимо от исходного формата входного файла. Преобразование выполняется налету, когда необходимо, позволяя приложениям Plywood работать с единственной внутренней кодировкой.
Автоматическое определение формата
Вот так сейчас работает автоматическое определение формата текста в Plywood:
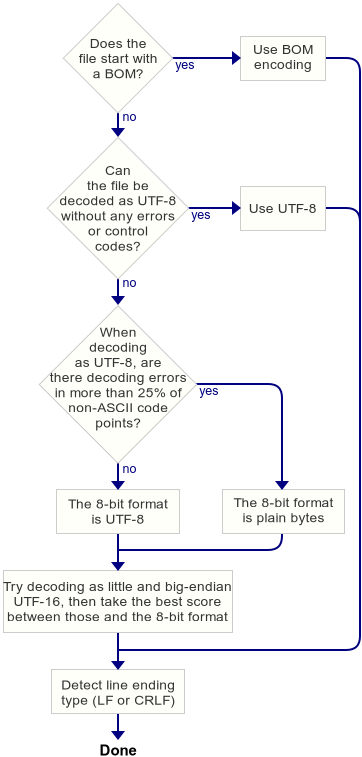
Plywood анализирует первые 4 КБ входного файла, чтобы предположить его формат. Двух начальных проверок достаточно подавляющему большинству текстовых файлов, с которыми я сталкивался. В UTF-8 есть много недопустимых последовательностей байтов, поэтому когда файл может быть декодирован как UTF-8 и не содержит никаких управляющих кодов, это почти наверняка UTF-8. Управляющий код — это код символа меньше 32, за исключением символов табуляции, перевода строки и возврата каретки.
Только при входе в нижнюю часть блок-схемы возникают некоторые догадки. Во-первых, Plywood решает, лучше ли интерпретировать файл как UTF-8 или как простые байты. Это делается, чтобы обработать, например, текст с ударениями в кодировке Windows-1252. В ней французское слово détail кодируется байтами 64 E9 74 61 69 6C, что вызывает ошибку декодирования UTF-8. UTF-8, в свою очередь, ожидает, что за байтом E9 следует байт в диапазоне от 80 до BF. После определённого количества ошибок Plywood делает выбор в пользу простого байта, а не UTF-8.
Система оценки корректности кодировки
Фреймворк пытается декодировать одни и те же данные, применяя 8-битный формат, little-endian UTF-16 и big-endian UTF-16. Он вычисляет балл для каждой кодировки таким образом:
- Каждый декодированный символ пробела добавляет 2,5 балла. Пробельные символы очень полезны для идентификации кодировок, поскольку пробелы UTF-8 не могут быть распознаны в UTF-16, а пробелы UTF-16 содержат управляющие коды при интерпретации в 8-битной кодировке.
- ASCII символы, за исключением управляющих, добавляют по 1 баллу.
- Ошибки декодирования влекут штраф в 100 баллов.
- Управляющие коды наказываются штрафами в 50 баллов.
- Коды символов, превышающие
U+FFFF, стоят 5 баллов, так как шансы столкнуться с такими символами в случайных данных невелики вне зависимости от кодировки. Яркий пример — эмоджи.
Баллы делятся на общее количество декодированных символов, затем выбирается лучший результат.
Откуда взялись 2,5, 1 и прочие значения? Я их выдумал. Они, вероятно, ещё не оптимальны. У алгоритма есть и другие слабые места. Plywood ещё не знает, как распознавать произвольные 8-битные кодировки. В настоящее время он интерпретирует каждый 8-битный текстовый файл UTF-8 как Windows-1252. Фреймворк также не поддерживает Shift JIS в настоящее время. Хорошая новость заключается в том, что Plywood — проект с открытым исходным кодом. Это означает, что улучшения могут публиковаться сразу после разработки.
Набор тестов
В репозитории вы найдете папку, содержащую 50 текстовых файлов различных форматов. Все эти файлы корректно определяются и загружаются функцией FileSystem::openTextForReadAutodetect().
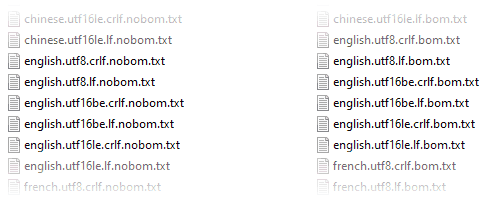
Многие современные текстовые редакторы, как и Plywood, определяют формат автоматически. Из любопытства я открывал этот набор в нескольких редакторах:
- Notepad++ корректно открывает 38 из 50 файлов. Он терпит неудачу на всех файлах UTF-16 без BOM, за исключением little-endian, состоящих в основном из символов ASCII.
- Sublime Text понимает 42 файла. Когда текст содержит ASCII, редактор делает верное предположение независимо от кодировки.
- Visual Studio Code видит 40 фалов. VSC близок к Sublime Text, но ошибается на Windows-1252 с ударениями.
- И самое впечатляющее: Блокнот Windows верно отображает 42 файла! Он правильно распознаёт все UTF-16 с прямым порядком без BOM, но не работает с UTF-16 обратного порядка байтов и без BOM.
По общему признанию это было нечестное соревнование: весь тестовый набор создан вручную специально для Plywood. Больше всего ошибок происходило на файле UTF-16 без BOM. Кажется, это редкий формат. Ни один из редакторов не позволяет сохранить такой файл.
Редакторы из списка выше в первую очередь вдохновляли стратегию автоматического обнаружения в Plywood. В C++ работа с Unicode всегда вызывала трудности. Ситуация весьма печальная: комитет по стандартизации C++ только недавно сформировал исследовательскую группу для решения проблемы. Между тем, я всегда задавался вопросом о том, почему загрузка текста в C++ не может быть такой же простой, как в современном текстовом редакторе? Если вам нравится направление движения Plywood и вы хотите, чтобы так и продолжалось, ваша поддержка на Patreon была бы признанием фреймворка.

Если вы хотите сделать Plywood лучше любым из упомянутых способов, участвуйте на GitHub или на сервере Discord. Если вам нужен только исходный код, обнаруживающий кодировки, не стесняйтесь копировать исходник и изменять его, как посчитаете нужным.
Читайте также:
- Шаблон проектирования прототипов в современном C++
- Тест рабочего цикла C++ через написание кода для декодера base85
- Языки C и C++. Где их используют и зачем?
Читайте нас в телеграмме, vk и Яндекс.Дзен
Перевод статьи Jeff Preshing: Automatically Detecting Text Encodings in C++





