
Ввиду недавних успехов в области машинного обучения и исследований в области искусственного интеллекта, немного удивительно, что наука о данных стала сферой главного интереса.
Нет сомнений в том, что это очень хороший выбор для людей с аналитическим складом ума, требующий сочетание как хороших навыков программирования, так и глубокие технические знания.
Тем не менее, помимо показательных дуэлей нейронных сетей и распределённых вычислений, имеются некоторые фундаментальные статистические практики, с которыми любой специалист по работе с данными должен быть глубоко ознакомлен.
Вы можете знать самые новые фреймворки программирования или иметь успехи в научной литературе, которые требуются для некоторых проектов, но нет никаких быстрых путей для получения необходимых навыков ноу-хау при работе обработчиком данных.
Только практика, терпение и интерес к трудным путям решения задач по-настоящему отточат ваши “инстинкты данных”.
Принцип бережливости
Это повторялось так часто, что уже стало клише курсов начальной статистики, но сегодня слова британского статистика Джорджа Бокса актуальны как никогда:
Все модели неправильны, но некоторые из них полезны
Что это вообще значит?
Это значит, что при создании модели реального мира вам в любом случае придётся что-то упростить или обобщить для того, чтобы увеличить её объясняющую способность.
Настоящий мир слишком беспорядочный и переполненный, а значит изучить его до мельчайших деталей невероятно сложно. Поэтому статистическое моделирование стремится достичь не идеальной, а максимальной прогностической способности с минимальной необходимой моделью.
Для тех, кто новенький в мире данных, эта концепция может показаться противоречащей интуиции. Почему не поместить в модель столько условий, сколько возможно? Очевидно, что дополнительные условия только расширят объясняющую способность модели?
Что ж… и да и нет. Вас должны волновать только те условия, которые привносят с собой статистически значимое увеличение объясняющей способности.
Рассмотрим различные типы моделей, которые подходят под заданные наборы данных.
Самой базовой моделью является нулевая модель, которая имеет только один параметр — общее значение переменной ответов (плюс некоторые случайные распространённые ошибки).
В этой модели утверждается, что переменная ответов не зависит от объясняющих переменных. Вместо этого её значения полностью объясняются случайными колебаниями общего значения. Очевидно, это ограничивает объясняющую способность модели.
Абсолютно противоположной моделью является насыщенная модель, которая имеет один параметр для каждой отдельной точки данных. В итоге вы получаете идеально подходящую модель, но которая потеряет свою объясняющую способность, если вы будете забрасывать в неё новые данные.
Включение одного условия для каждой отдельной точки данных также отвергает принцип максимального упрощения. Это, опять же, не совсем полезно.
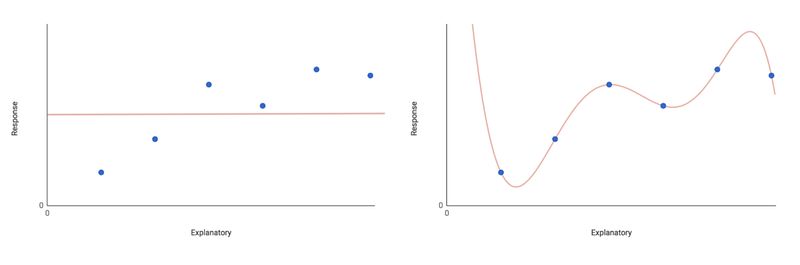
Понятно, что это крайние случаи. Вам нужно искать модель где-то между ними, которая хорошо подбирает данные и имеют неплохую объясняющую способность. Вы можете попробовать подобрать максимальную модель. Эта модель включает условия для всех рассматриваемых факторов и условий взаимодействия.
Допустим у вас есть переменная ответов y, которую вы хотите моделировать как функцию объясняющих переменных x₁ и x₂, умноженных на коэффициенты β. Максимальная модель будет выглядеть так:
y = intercept + β₁x₁ + β₂x₂ + β₃(x₁x₂) + error
Максимальная модель, как мы надеемся, хорошо подберет данные, а также обеспечит хорошую объясняющую способность. Это подразумевает под собой одно условие для каждой объясняющей переменной, а также условие взаимодействия x₁x₂.
Удаление условий из модели увеличит общие остаточные отклонения. В ином случае доля наблюдаемого изменения предсказания модели не учитывается.
Тем не менее, не все условия эквивалентны. Вы можете удалить одно (или более) условие без статистически значимого увеличения отклонения.
Такие условия могут считаться несущественными и быть удалены из модели. Вы можете убрать незначительные условия одно за другим (не забывая пересчитывать остаточное отклонение на каждом шаге). Повторяйте это до тех пор, пока все оставшиеся условия не будут иметь статистической значимости.
Теперь вы получили минимальную адекватную модель. Оценки для коэффициента β каждого условия существенно отличаются от нуля. Подход пошагового удаления, который здесь использовался, называется поэтапной регрессией.
Философский принцип, лежащий в основе этого стремления к упрощению модели, известен как принцип бережливости.
Он имеет некоторое сходство с известной эвристикой средневекового философа Уильяма Оккама, «Бритвой Оккама». Можно объяснить это следующими словами: “если имеется два или более равноценных объяснения, работайте с тем, в котором меньше предположений”.
Другими словами: можете ли вы с пользой объяснить что-то сложное самым простым способом? Можно сказать, что в этом определение стремления науки о данных — переводить сложное в понятное.
Всегда будьте скептичны
Тестирование гипотез (например A/B тестирование) представляет из себя важную концепцию в науке о данных.
Проще говоря, тестирование гипотез работает следующим образом: мы сводим проблему к двум взаимоисключающим гипотезам и спрашиваем, при какой гипотезе наблюдаемая величина нашего теста наиболее вероятна по статистике. Разумеется, статистика в тесте рассчитывается из некоторого подходящего набора экспериментальных или наблюдаемых данных.
Когда дело доходит до тестирования гипотез, вы обычно узнаёте, принимаете вы или отклоняете нулевую гипотезу.
Часто вы услышите, как люди описывают нулевую гипотезу как что-то несостоявшееся, как свидетельство экспериментальной неудачи.
Возможно, это связано с тем, как тестирование гипотез преподается новичкам, но похоже, что многие исследователи и обработчики данных имеют подсознательное предубеждение насчёт нулевой гипотезы. Они стремятся отвергнуть её в пользу предположительно более захватывающей и интересной альтернативной гипотезы.
И это не просто анекдотичная проблема. Были написаны целые статьи об исследовании проблемы предвзятости публикаций в научной литературе. Можно только догадываться, как эта тенденция проявляется в коммерческом контексте.
Однако дело в том, что для любого правильно спроектированного эксперимента или полного набора данных, принятие нулевой гипотезы должно быть столь же интересным, как и принятие альтернативной.
В самом деле, нулевая гипотеза является краеугольным камнем выведенной статистики. Она определяет то, что мы делаем как обработчики данных, то бишь превращение данных в идеи. Прогнозы ничего не стоят, если мы не супер избирательны в отношении того, какие находки должны допускаться к сбору. И именно по этой причине постоянный ультра-скептицизм окупается.
Это особенно важно, учитывая, насколько легко «случайно» отвергнуть нулевую гипотезу (по крайней мере, при наивном применении частотного подхода).
Драгинг данных (или “p-взлом”) могут вызывать всевозможные бессмысленные результаты, которые, тем не менее, могут казаться статистически значимыми. Тем, где несколько сравнений неизбежны, нет никаких оправданий для того, чтобы не предпринимать никаких шагов по минимизации ошибок типа I (ложные срабатывания или «видимые эффекты, которых на самом деле нету»).
- Для начала, когда доходит до статистических тестов, выберите тот, который осторожен по своей сути. Убедитесь, что предположения теста относительно ваших данных выполнены правильно.
- Также важно изучить методы коррекции, например, коррекцию Бонферрони. Однако эти методы иногда подвергаются критике за чрезмерную осторожность. Они могут уменьшить статистическую способность, производя слишком много ошибок типа II (ложные негативы или «игнорирующие эффекты которые на самом деле существуют»).
- Ищите «нулевые» объяснения ваших результатов. Насколько ваши подходили процедуры отбора/сбора данных? Можете ли вы исключить какие-либо систематические ошибки? Могут ли быть какие-либо эффекты уцелевших предубеждений, автокорреляции или регрессии до среднего?
- И, наконец, насколько правдоподобны любые потенциальные связи, которые вы нашли? Никогда не принимайте что-либо за номинальную ценность, независимо от того, насколько низким может быть p-значение!
Скептицизм полезен, и, как правило, всегда стоит помнить о нулевых объяснениях для ваших данных.
Но избегайте паранойи! Если вы хорошо спроектировали свой эксперимент и тщательно проанализировали свои данные, то продолжайте в том же духе и свои данные как есть!
Знайте свои методы
Недавние технологические и теоретические достижения предоставили обработчикам данных целый ряд новых мощных инструментов для решения сложных проблем, которые было бы даже невозможно решить десятилетие или два назад.
Существует большое волнение, связанное с этими достижениями в машинном обучении, и не без оснований. Тем не менее, слишком легко проглядеть любые ограничения, которые могут идти вместе с данной проблемой.
К примеру, нейронные сети могут быть совершенны в классификации изображений и распознавании почерка, но они ни в коем случае не являются идеальным решением для всех проблем. Для начала, они очень склонны к переобучению, то есть к слишком сильному ознакомлению с уже натренированными данными вместо обобщения новых случаев.
Также обратите внимание на их непрозрачность. Прогностическая способность нейронных сетей часто приходит за счет прозрачности. Благодаря интернализации выбора функции, даже если сеть делает точное предсказание, вы не всегда понимаете, как она пришла к этому ответу.
Во многих деловых и коммерческих приложениях понимание «как и почему» часто является самым важным результатом аналитического проекта. Уступить это понимание ради прогностической точности может как оказаться компромиссом, так и не оказаться.
Точно так же возникает соблазн полагаться на точность сложного алгоритма машинного обучения, хотя нет никакой гарантии в их непогрешимости.
Например, Google Cloud Vision API, который, как правило, очень впечатляет, может быть легко обманут даже небольшим количеством шума в изображении. И наоборот, еще один увлекательный исследовательский документ показал, как Deep Neural Networks может «видеть» образы там, где их попросту нет.

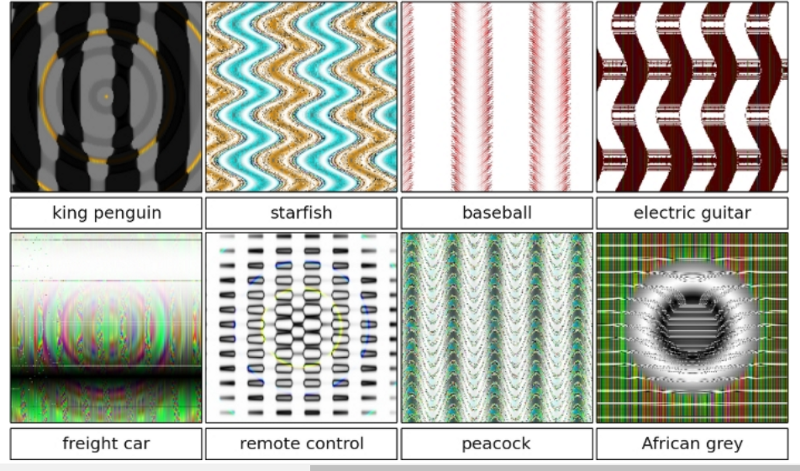
Это не просто передовые методы машинного обучения, которые нужно использовать с осмотрительностью.
Даже при использовании более традиционных подходов к моделированию необходимо принимать во внимание, что ключевые допущения были выполнены. Всегда следите за экстраполяцией вне пределов данных обучения, если не с подозрением, то хотя бы с осторожностью. С каждым сделанным вами выводом всегда спрашивайте, оправдывают ли ваши методы это.
Это не означает, что вы не должны доверять ни одному из методов. Это значит, что вы должны быть в курсе, почему вы используете один метод вместо другого и какие относительные плюсы и минусы это за собой несёт.
Как правило, если вы не можете найти даже один недостаток в методе, который вы рассматриваете, то в следующий раз исследуйте его еще до использования. Всегда используйте простейший инструмент, который будет выполнять эту работу.
Знание того, когда есть подходящая ситуация для использования какого-то подхода, а когда нет, является ключевым навыком в науке о данных. Это умение, которое улучшается с опытом и подлинным пониманием методов.
Коммуникация
Коммуникация — это сущность науки о данных. В отличие от академических дисциплин, где ваша целевая аудитория будет высококвалифицированными специалистами в вашей конкретной области обучения, аудитория коммерческого обработчика данных, скорее всего, будет экспертом в самых разных областях.
Даже самые лучшие идеи в мире ничего не стоят, если они плохо сообщаются. Много стремящихся обработчиков данных приходят из академических/исследовательских кругов и будут общаться с технически специализированными аудиториями.
Однако, в коммерческой среде невозможно объяснить, насколько важно передать ваши выводы таким образом, чтобы обычная аудитория смогла их понять и обработать.
Например, ваши результаты могут иметь отношение к целому ряду различных отделов внутри организации — от маркетинга, до операций и разработки продукта. Члены каждого из них будут экспертами в соответствующих им областях работы и получат ясный, чёткий и релевантный итог ваших выводов.
Известные ограничения ваших результатов настолько же важны, как и фактические результаты. Убедитесь, что ваша аудитория осведомлена о любых ключевых допущениях, недостающих данных или степени неопределенности в вашем рабочем процессе.
“Лучше один раз увидеть, чем сто раз услышать” особенно актуально в науке о данных. С этой целью инструменты визуализации данных неоценимы.
Такое программное обеспечение, как Tableau, или библиотеки вроде ggplot2 для R и D3.js, являются отличными способами для очень эффективной передачи сложных данных. Они стоят того, чтобы справляться с какой-либо технической концепцией.
Некоторая осведомленность о принципах графического дизайна заиграет большую роль в тот момент, когда вы решите сделать ваши диаграммы умными и профессиональными.
Также, сосредоточитесь на том, чтобы ясно писать. Эволюция сформировала из людей впечатляющих существ, полных подсознательных предрассудков, и мы по своей сути более склонны доверять лучше представленной, хорошо написанной информации.
Иногда лучший способ понять концепцию — это прикоснуться к ней самостоятельно, поэтому, возможно, стоит изучить несколько веб-навыков во фронт-энде для создания интерактивной визуализации, с которой ваша аудитория сможет взаимодействовать. Нет необходимости изобретать велосипед. Библиотеки и инструменты, такие как D3.js и R’s Shiny, сделают вашу задачу намного проще.
Перевод статьи Peter Gleeson: How to sharpen your data instincts





