
Визуализация данных — это большая часть работы специалистов в области data science. На ранних стадиях развития проекта часто необходимо выполнять разведочный анализ данных (РАД, Exploratory data analysis (EDA)), чтобы выявить закономерности, которые обнаруживают данные. Визуализация данных помогает представить большие и сложные наборы данных в простом и наглядном виде. На этапе окончания проекта важно суметь отчитаться о его результатах так, чтобы даже непрофессионалам, не обладающим техническими знаниями, всё стало ясно и понятно.
Matplotlib — это популярная библиотека для визуализации данных, написанная на языке Python. Хоть пользоваться ей очень просто, настройка данных, параметров, графиков и отрисовки для каждого нового проекта — занятие нудное и утомительное. В этом посте мы разберем 6 способов визуализации данных и напишем быстрые и простые функции для их реализации с помощью питоновской библиотеки Matplotlib. А пока взгляните на прекрасный график, который поможет вам выбрать правильный тип визуализации данных!
Алгоритм выбора техники визуализации в зависимости от задачи
Диаграммы рассеяния (Scatter Plots)
Используйте их, если хотите показать связь между двумя переменными, так как они позволяют отображать грубое распределение данных. На нем также можно показать соотношение между различными группами данных за счет окрашивания их разными цветами. Нужно показать взаимосвязь между тремя переменным? Ноу проблем! Просто добавьте дополнительные параметры, такие как размер точек, чтобы закодировать эту третью переменную, как это сделано на втором графике снизу.
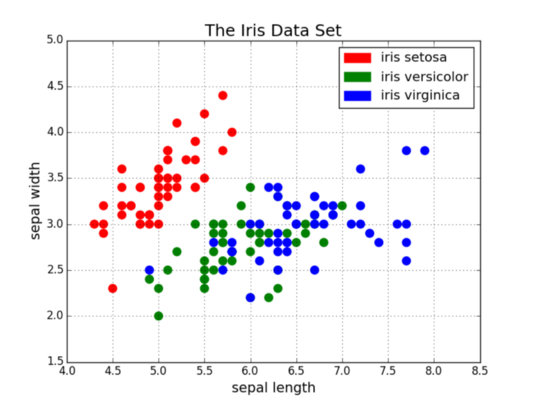
Теперь что касается кода. Сначала мы импортируем в Python библиотеку Matplotlib, а точнее её модуль pyplot, для краткости используя аббревиатуру «plt». Чтобы создать новый график, мы вызываем функцию plt.subplots(). Затем передаем данные оси x и оси y в функцию, а затем уже всё вместе передаем функции ax.scatter() для построения диаграммы рассеяния. Мы также можем установить размер точки, цвет точки и альфа-прозрачность. Можно даже использовать логарифмическую шкалу для оси y. Затем задаем заголовок и метки для осей. Это простая в использовании функция позволяет с нуля создать и отрисовать диаграмму рассеяния!
Графики
Графики лучше всего использовать тогда, когда одна переменная сильно варьируется в зависимости от другой, другими словами, когда у них высокая ковариация. Давайте посмотрим на рисунок ниже, чтобы проиллюстрировать это. График наглядно показывает большой разброс процентного соотношения за указанный промежуток времени. Если бы эти же данные мы представили в виде диаграммы рассеяния, она была бы чрезвычайно загроможденной и сложной, что затрудняло бы понимание и визуальное отображение рассматриваемой зависимости. Графики, выполненные в виде линий, идеально подходят для этой ситуации, потому что они показывают ковариации двух переменных (в данном случае процент и временной промежуток). Как и в предыдущем примере, мы можем использовать группировку с помощью цвета.
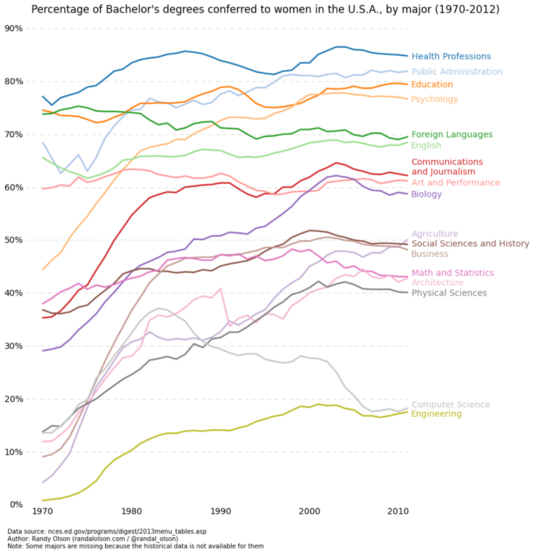
Ниже представлен код для создания линейного графика. Он похож на код для программирования диаграммы рассеяния, рассмотренной выше, с некоторыми незначительными вариациями в переменных.
Гистограммы (Histograms)
Гистограммы полезны для представления (или даже выявления) распределения данных. Посмотрите на пример ниже, где мы построили гистограмму частоты vs IQ. Мы легко можем заметить концентрацию ближе к центру, а также отчетливо прослеживается медиана значений. Мы также видим, что оно подчиняется гауссовскому распределению. Использование столбцов (а не точек рассеивания, например) действительно дает нам четкую визуализацию относительной разницы между частотой каждого интервала. Использование полос (интервалов = дискретизация) действительно помогает нам увидеть «целостную картину». Если эти же данные представить в виде отдельных точек, без выделения интервалов, то на диаграмме появится слишком много шума, что затруднит понимание тенденции, которая иллюстрируется с помощью этих данных.
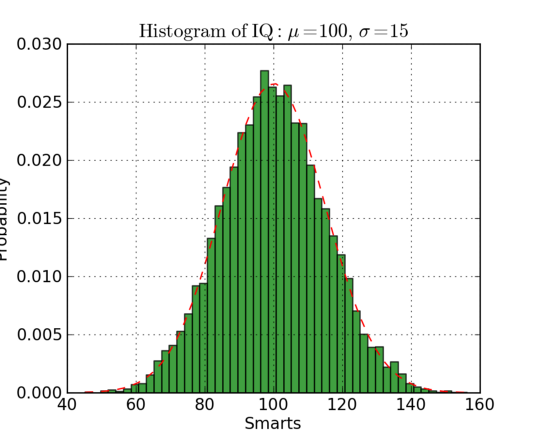
Ниже приведен код гистограммы в Matplotlib. Обратите внимание на два параметра. Во-первых, параметры n_bins определяют, сколько отдельных интервалов нам необходимо поместить на нашей гистограмме. Большее число интервалов даст нам более точную информацию, но может также ввести информационный шум и отвлечь нас от понимания целостной картины; с другой стороны, меньшее число интервалов обеспечивает нам вид с высоты птичьего полёта и целостную картину того, что происходит, при этом не перегружая её мельчайшими деталями. Во-вторых, параметр cumulative является булевым (то есть 1 или 0), что позволяет нам выбрать, является ли наша гистограмма кумулятивной или нет. Другими словами, мы задаем либо плотность вероятности ( Probability Density Function (PDF)) либо функцию интегрального распределения ( Cumulative Density Function (CDF)).
Теперь представьте себе, что мы хотим сравнить распределение двух переменных в наших данных. Первая мысль, которая приходит в голову — это сделать две отдельные гистограммы и расположить их рядом, для наглядности. Но на самом деле есть способ лучше: мы можем накладывать гистограммы с различной прозрачностью. Посмотрите на рисунок, представленный ниже. Равномерное распределение имеет прозрачность 0,5, чтобы мы могли видеть, что расположено за ним. Это позволяет одновременно отобразить два распределения на одном рисунке.
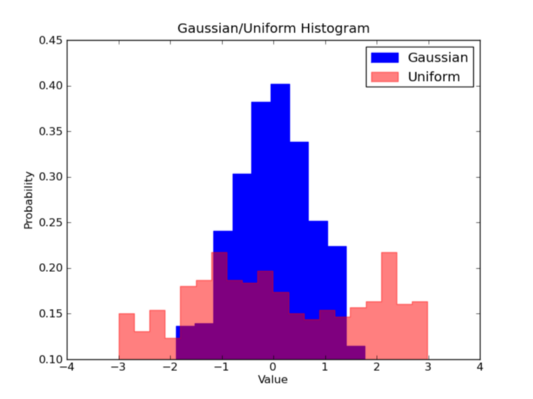
Есть несколько параметров, которые необходимо настроить в коде для создания наложенных друг на друга гистограмм. Во-первых, мы устанавливаем горизонтальный диапазон для размещения переменных обоих распределений. В соответствии с этим диапазоном и желаемым количеством интервалов мы можем фактически вычислить ширину каждого интервала, каждой полосы. Наконец, мы строим две гистограммы на одном и том же участке, причем один из них должен быть более прозрачен.
Столбчатые диаграммы (Bar Plots)
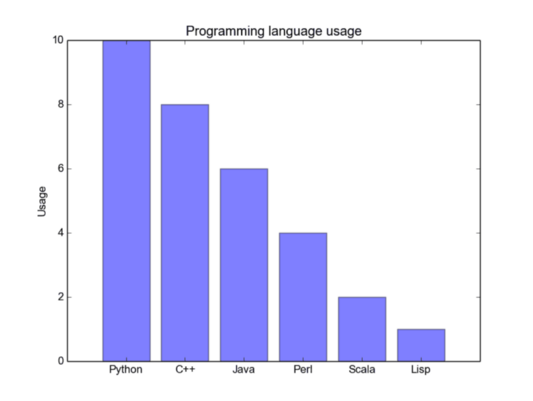
Столбчатые диаграммы наиболее эффективны тогда, когда вам необходимо визуализировать данные в виде категорий, если их число не превышает 10. Если у нас слишком много категорий, то столбцы будут сильно загромождать график, и его трудно будет понять. Они хороши для данных, разделенных по категориям, потому что вы можете легко увидеть разницу между категориями в зависимости от размера столбца (например, величины); категории также легко можно сформировать и выделить цветом. Есть три разных типа столбчатых диаграмм, которые мы будем рассматривать далее: обычные, сгруппированные и составные. Каждый из этих типов мы рассмотрим по порядку.
Обычная столбчатая диаграмма находится на первом рисунке снизу. В функции barplot() x_data задает метки на оси x, а y_data задает высоту столбца по оси y. Строка ошибки представляет собой дополнительную линию, расположенную в центре каждого столбца, которая может быть использована для отображения стандартного отклонения.
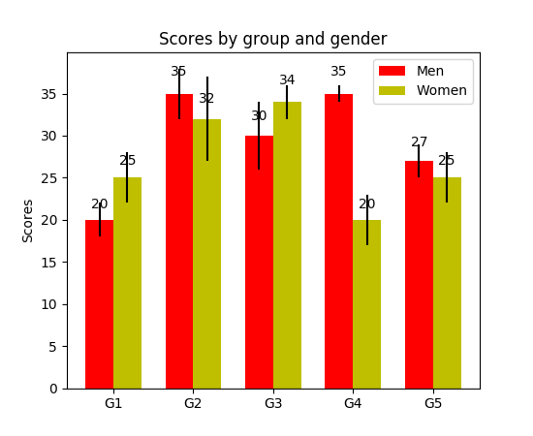
Сгруппированные столбчатые диаграммы позволяют сравнивать несколько переменных. Посмотрите на второй график снизу. Первой переменной, которую мы сравниваем, задается то, как оценки варьируются от группы к группе (группы G1, G2, … и так далее). Мы также сравниваем между собой распределение полов, что закодировано цветом. Теперь взгляните на код — вы заметите, что переменная y_data_list теперь фактически представляет собой список списков, где каждый вложенный список обозначает другую группу. Затем мы проходимся циклом по каждой группе, и для каждой группы рисуем столбец для каждого метки по оси x; все группы также дополнительно окрашиваются.
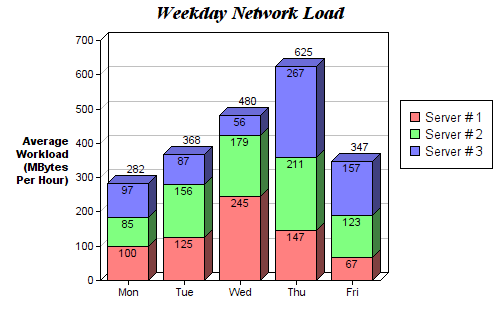
Составные столбчатые диаграммы отлично подходят для визуализации набора различных переменных. В приведенном ниже рисунке с разбивкой по строкам мы отслеживаем изменение нагрузки на сервер по дням недели. С помощью цветовых наборов мы можем легко видеть и понимать, какие серверы работают больше всего в каждый конкретный день и как в целом распределяется нагрузка по дням на все сервера. Код для этой диаграммы строится по тому же принципу, что и код для сгруппированных столбчатых диаграмм. Мы проходим циклом по каждой группе, с одним единственным исключением: на этот раз мы рисуем новые столбцы поверх старых, а не рядом с ними.
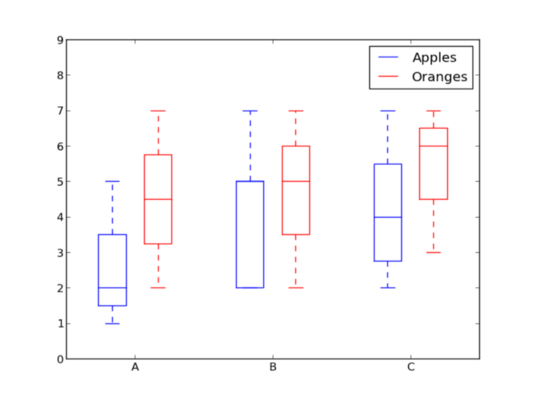
Прямоугольные диаграммы (Box Plots)
Ранее мы рассмотрели гистограммы, которые великолепно подходят для визуализации распределения переменных. Но что, если этого нам недостаточно и нужно отобразить больше информации? Может быть, нам необходимо более наглядное представление стандартного отклонения? Возможно, медиана сильно отличается от среднего значения, и, следовательно, у нас много отклонений? Что, если имеются скосы, и многие из значений сосредоточены на одной стороне?
Вот здесь и вступают в игру прямоугольные диаграммы. Именно они помогают нам дополнительно разместить выше указанную информацию. Нижняя и верхняя части ящика, составленного сплошной линией, всегда являются первым и третьим квартилями (т.е. 25% и 75% данных), а полоса внутри прямоугольника всегда вторая квартиль (медиана). Усы (то есть пунктирные линии с полосками на конце) начинаются от прямоугольника и показывают диапазон данных.
Поскольку прямоугольные диаграммы строятся для каждой группы / переменной, их достаточно легко настраивать. x_data — это список групп / переменных. Функция Matplotlib boxplot() создает график для каждого столбца y_data или каждого вектора в последовательности y_data; таким образом, каждое значение в x_data соответствует столбцу / вектору в y_data. Все, что нам остается добавить, — это внешний вид графика.
Заключение
Существует 5 быстрых и простых способов визуализации данных с использованием библиотеки Matplotlib. Оформление чего-либо в функцию всегда делает ваш код более легким для чтения и использования! Надеюсь, вам понравился этот пост и узнали что-нибудь новое и полезное.
Перевод статьи George Seif: 5 Quick and Easy Data Visualizations in Python with Code





