
Проблема классификации была весьма эффективно решена при помощи архитектур типа “энкодер-декодер”, в которых энкодерам свойственно постепенное уменьшение масштаба. Однако эта архитектура не способна эффективно генерировать сильные мульти-масштабные признаки, необходимые для задач обнаружения объектов, а именно их единовременного распознавания и локализации.
Чем SpineNet отличается от предыдущих backbone-сетей?
В то время как для обнаружения присутствия признака может потребоваться высокое разрешение, для определения его локализации такая же точность не требуется. [1]
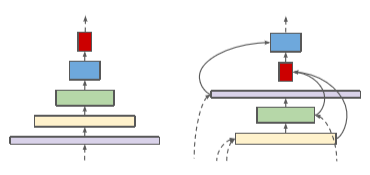
Недостатки backbone-сети с уменьшающимся масштабом
- Обычно backbone характеризует сеть с уменьшающимся масштабом в архитектуре “энкодер-декодер”, т.е. энкодер.
- Поскольку задача энкодера состоит в вычислении представлений признаков на основе вводных данных, backbone с уменьшающимся масштабом не сможет удерживать пространственную информацию.
- По мере углубления слоёв признаки будут становиться всё более абстрактными и менее локализованными, тем самым усложняя извлечение декодером точных необходимых признаков.
Предложенное нововведение
С целью преодоления сложности получения и извлечения многомасштабных признаков для локализации была представлена модель с пермутируемыми масштабами и межмасштабными связями, предлагающая следующие улучшения:
- Масштабы карт признаков в этой архитектуре получили возможность увеличения или уменьшения в любой момент времени посредством пермутации блоков, что противоположно прежнему шаблону, подразумевавшему только уменьшение. Это позволило сохранять пространственную информацию.
- Связям карт признаков разрешено пересекать масштабы признаков для выполнения слияния признаков из разных масштабов.
Методология и архитектура
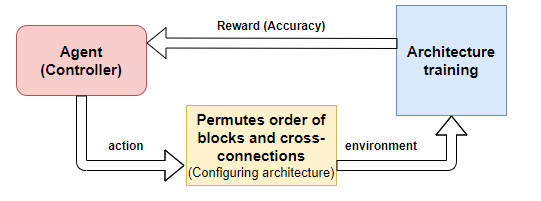
Поиск нейронной архитектуры (NAS)
- Методология выбора предлагаемой архитектуры SpineNet была внедрена при помощи NAS [1] (ссылка на английский источник в конце статьи).
- В NAS используется контроллер обучения с подкреплением. Он предлагает разные архитектуры, которые отправляются в среду, где полноценно обучаются.
- Точность вывода играет роль вознаграждения (reward), и решение о выборе архитектуры будет зависеть именно от неё.
Архитектура SpineNet содержит сеть с уменьшающимся масштабом, сопровождаемую обученной сетью с пермутируемым масштабом. Область поиска NAS для построения сети с пермутируемым масштабом включает в себя пермутацию масштабов, межмасштабные связи и подстройку блоков.
- Пермутация масштабов. Блок может подключаться только к своему родительскому блоку, имеющему более низкий порядок, поэтому упорядочивание блоков имеет значение. Здесь пермутация применяется для промежуточных и выходных блоков.
- Межмасштабные связи. Для каждого блока в области поиска определяются две входящие связи.
- Подстройка блоков. Каждый блок может подстраивать свой уровень масштабирования и тип. Уровни масштабирования промежуточных блоков могут варьироваться, например {-1,0,1,2}, а по типу блоки могут быть либо суженными (bottleneck), либо остаточными (residual).
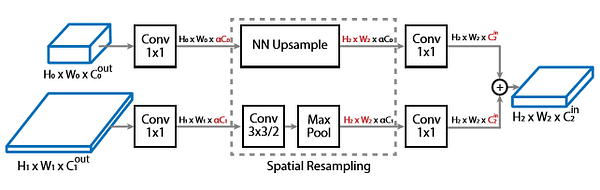
Повторная выборка в межмасштабных связях
- Сложность при осуществлении межмасштабных связей возникает, когда нужно выполнить слияние межмасштабных признаков, имеющих разное разрешение и размерность между родительским и целевым блоками.
- В данном случае для подгонки параметров под целевой блок повторно выполняется пространственная выборка и выборка признаков.
- При повторной выборке для повышения размерности изображения (upsampling) используется алгоритм ближайшего соседа, в то время как свёртка 3х3 с шагом 2 выполняет повышение размерности карты признаков для подгонки под целевое разрешение.
Построение архитектуры SpineNet на основе ResNet
- Модель с пермутируемыми масштабами формируется посредством пермутации блоков архитектуры ResNet.
- Для сравнения сети с уменьшающимся масштабом с сетью, работающей по принципу пермутации, генерируется ряд промежуточных моделей, которые пошагово смещают архитектуру сети в сторону её пермутируемой формы.
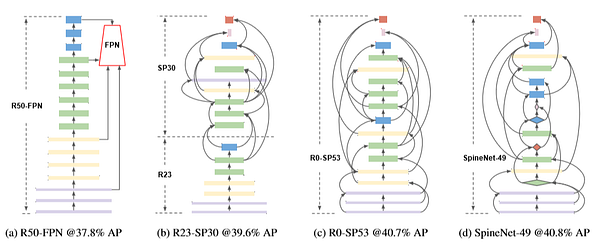
- На изображении выше часть (a) демонстрирует использование ResNet-50, сопровождаемой выходным слоем сети пирамид признаков (FPN).
- В части (b) 7 блоков принадлежат ResNet, а 10 блоков используются для сети пермутируемых масштабов.
- В части (c) все блоки являются частью сети пермутируемых масштабов, а в (d) SpineNet-49 представлена с наивысшим баллом AP в 40,8%, требуя при этом на 10% меньше FLOPs, а именно 85.4B против 95.2B.
Предлагаемые архитектуры SpineNet
На основе SpineNet-49, полученной в части (d) рис. 4, строятся ещё 4 архитектуры семейства SpineNet.
- SpineNet-49S имеет ту же архитектуру, что и SpineNet-49, но с размерностями признаков, уменьшенными в 0,65 раза.
- SpineNet-96 повторяет все блоки дважды, в связи с чем размер модели в два раза превышает SpineNet-49.
- SpineNet-143 повторяет каждый блок трижды, а коэффициент масштабирования при повторной выборке сохраняется равным 1.0.
- SpineNet-190 повторяет каждый блок четыре раза при коэффициенте масштабирования, равном 1,3, для дальнейшего увеличения масштаба признаков.
Результаты сравнения
Чтобы продемонстрировать универсальность предлагаемой архитектуры, эксперименты проводятся как в отношении обнаружения объектов, так и в отношении классификации изображений.
Обнаружение объектов
Backbone-сеть ResNet-FPN замещена детектором RetinaNet. Модель оценивалась на датасете COCO test-dev, а обучалась на train2017.
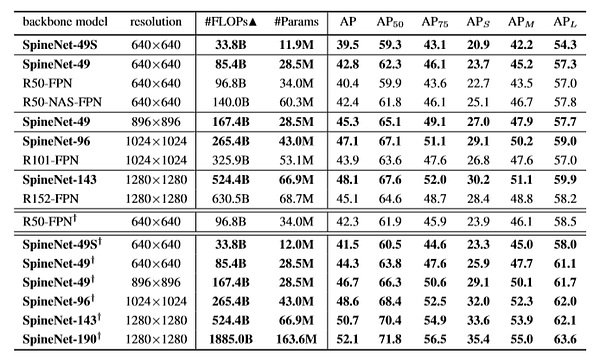
- Приведённые ниже результаты показывают, что модели SpineNet с большим отрывом превосходят другие популярные детекторы. Самая крупная из них — SpineNet-190 — достигает высшего балла AP в 52,1%. Вообще архитектуры SpineNet требуют меньше операций с плавающей точкой в секунду и меньше параметров, снижая тем самым количество необходимых вычислений.
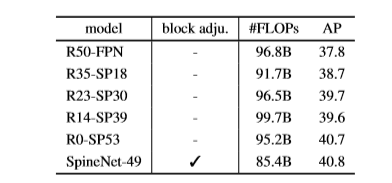
- Результаты в следующей таблице получены на COCO val2017 и показывают, что SpineNet-49 требует примерно на 10% меньше операций с плавающей точкой, а показатель AP улучшился до 40,8% в сравнении с 37,8% у R50-FPN.
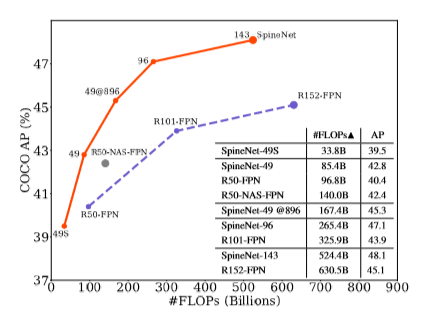
- Согласно следующему графику, модель RetinaNet, применяющая backbone-сети SpineNet, достигает более высокого показателя AP при существенно меньшем количестве операций с плавающей точкой по сравнению с ResNet-FPN и NAS_FPN.
Классификация изображений
SpineNet для классификации изображений обучена на двух датасетах: ImageNet ILSVRC-2012 и iNaturalist-2017.
- В ImageNet точность TOP-1% и TOP-5% находится на уровне ResNet, и в дополнении к этому число операций в секунду существенно уменьшено.
- В iNaturalist SpineNet превосходит ResNet с существенным отрывом в 5% и меньшим числом требуемых FLOPs.
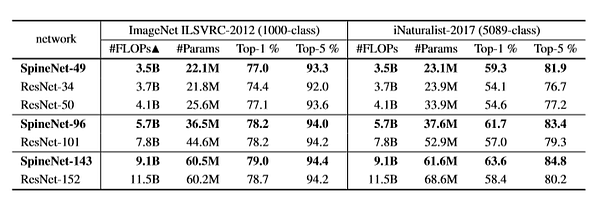
Вышеприведённые результаты показывают, что SpineNet не только лучше справляется с обнаружением объектов, но также показывает достаточную универсальную пригодность и для других задач визуального обучения вроде классификации изображений.
Значимость пермутации масштабов и межмасштабных связей
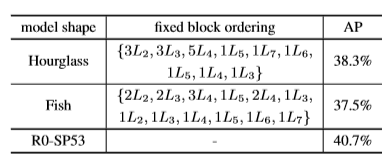
Согласно [1], для сравнения с предложенной моделью R0-SP53 в сетях типа “энкодер-декодер” выбираются две популярные архитектурные формы: Fish и Hourglass. Взаимные связи во всех моделях обучаются при помощи NAS.
Пермутация масштабов
- В итоге выяснилось, что совместное обучение пермутаций масштабов и межмасштабных связей, используемое в R0-SP53, показывает себя более выгодно, чем обучение одних только связей в фиксированной архитектуре/фиксированном порядке блоков в Hourglass и Fish.
- В случае предложенной модели R0-SP53 показатель AP выше и составляет 40,7%.
Межмасштабные связи
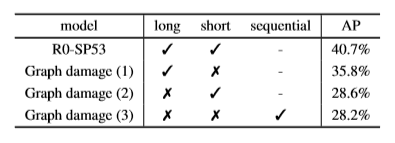
- Для исследования значимости межмасштабных связей используется метод повреждения графа.
- Межмасштабные связи повреждаются тремя способами: удалением коротких связей, удалением длинных и удалением обоих этих типов связей.
- Результаты показывают, что значение AP во втором случае существенно пострадало. Причина в том, что длинные связи могут эффективно обрабатывать частые изменения разрешения, в связи с чем их повреждение будет более ощутимо сказываться на общем показателе точности.
Заключительные выводы
- В [1] сообщается, что новая мета-архитектура с моделью пермутируемых масштабов способна распознавать объекты одновременно с их локализацией, чего не удавалось сделать эффективно ранее при помощи backbone-сети с уменьшающимся масштабом.
- Для создания архитектуры SpineNet-49 применяется поиск нейронной архитектуры (NAS). Более того, при увеличении глубины дополнительно создаётся четыре ещё более надёжных модели.
- SpineNet также успешно обеспечивает сопоставимую и улучшенную точности Top-1% в задачах по классификации изображений при работе с датасетами ImageNet и iNaturalist соответственно.
- В целом при использовании новой архитектуры более высокая точность достигается при меньших вычислениях и примерно том же числе параметров.
Ссылки (англ.):
[1] Статья “SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization” (X. Du, T. Lin, P. Jin, G. Ghiasi, M. Tan, Y. Cui, Q. V. Le, X. Song), представленная на IEEE-конференции по компьютерному зрению и распознаванию образов (CVPR)в 2020 году.
Читайте также:
- 25 наборов аудиоданных для исследований
- Крутые наборы данных для машинного обучения
- Поиск с возвратом в решении типичных задач на собеседовании
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Yesha R Shastri: SpineNet: An Unconventional Backbone Architecture from Google Brain





