
Предыдущие части: Часть 1, Часть 2, Часть 3, Часть 4, Часть 5
Многие считают, что наука о данных— это крутые алгоритмы машинного обучения и машины на автопилоте. Позвольте вас разуверить. Почти 80% времени вы ищете и обрабатываете данные, и в случае удачных результатов 20% посвящаете крутым штукам, описанным выше. “Найди данные и поиграйся с ними”, — самый распространенный совет, который слышат новички в анализе данных. Уверен, вы тоже с ним когда-то сталкивались, да? Но что, если вы очень хотите поработать над каким-то проектом, но необходимых вам данных нет в Интернете? Никто не учит вас, что делать в таком случае, не так ли?
Зачастую говорят, что мотивации хватает ненадолго. Ну так, то же самое происходит и с освежающим душем, поэтому и рекомендуют его принимать ежедневно.
— ЗИГ ЗИГЛАР
Не всегда нужные вам данные находятся на виду у всех. Но есть и хорошая новость, их всегда можно найти. Они спрятаны в веб-страницах. Вам просто нужно просканировать эти страницы и извлечь данные. Это и есть веб-скрапинг. И сегодня мы при помощи Python и BeautifulSoup (библиотека) создадим скрапер, чтобы собрать данные о чемпионате мира по футболу 2018 года. Данные будут включать информацию об игроках и их статистику на протяжении всего турнира. Интересно? Так чего же мы ждем? Поехали.
Шаг 0 — Разбираемся, какие данные собирать
Я искал подходящие для сбора данные и переходил с одной страницы на другую. Через 10 минут я попал на сайт fifa.com, и он идеально подошел. В поисках полезных данных я сразу же перешел в раздел “Игроки”. И там было то, что мне нужно. Мне оставалось только скачать эту страницу с помощью Python и собрать с неё данные. Говоря “скачать страницу”, я имею в виду HTML код этой страницы. Давайте разберемся, как можно скачать страницу.
Шаг 1 — Загрузка веб-страницы в Python
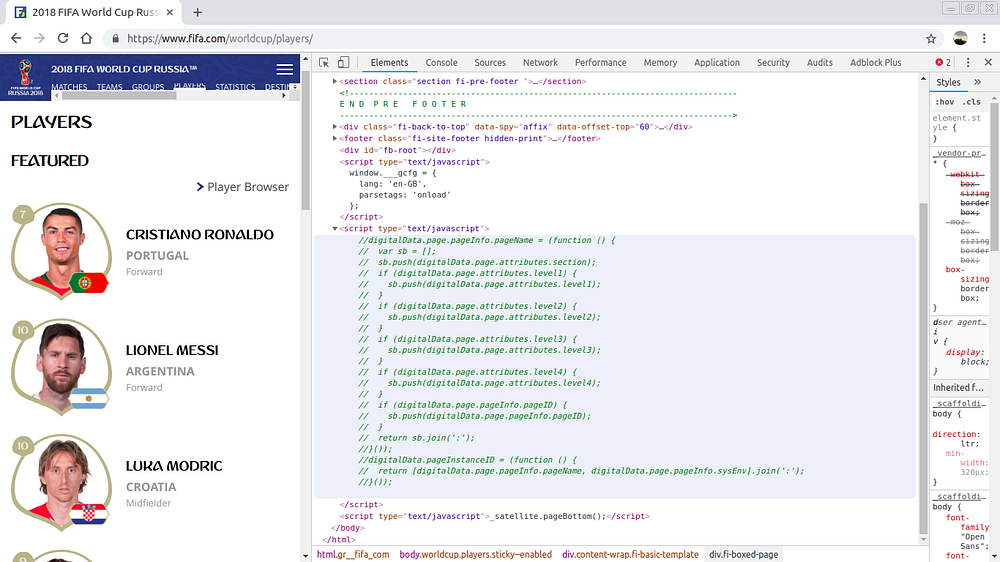
Уверен, вы уже когда-либо видели такой экран ранее. Если нет, вы можете увидеть нечто похожее, кликнув правой кнопкой мыши в любом месте данной страницы и выбрав “Просмотреть код элемента”. Я вставил изображение, чтобы, загрузив страницу в Python, вы могли понять, что всё сделали правильно.
#Импортируем библиотеки
import requests
from bs4 import BeautifulSoup
#Запрашиваем URL
page = requests.get("https://www.fifa.com/worldcup/players.html")
#Скачиваем страницу
soup = BeautifulSoup(page.content,"html.parser")
print(soup.prettify())
Первое, что нам нужно сделать для скрапинга страницы, — это скачать её. Для этого используем библиотеку Python requests.
А с помощью этой библиотеки мы спарсим страницу, которую только что скачали. Иными словами, мы извлечем нужные нам данные.
Используя requests.get, мы получим страницу, введя её URL. Теперь создаем экземпляр BeautifulSoup. Выведем его, чтобы проверить, правильно ли мы загрузили страницу. Добавление.prettify() делает код чище и понятнее для людей. Как вы видите, наша страница загрузилась правильно. Теперь нужно собрать с неё данные.
Шаг 2 — Первый игрок
Не пишите код, который вы не понимаете.
Легче всего собирать данные, когда веб-разработчик должным образом сделал свою работу, так как для сбора данных нам понадобятся HTML-атрибуты. Не знаете, какие данные нужно собирать? Через минуту всё объясню. Посмотрите на изображение ниже.
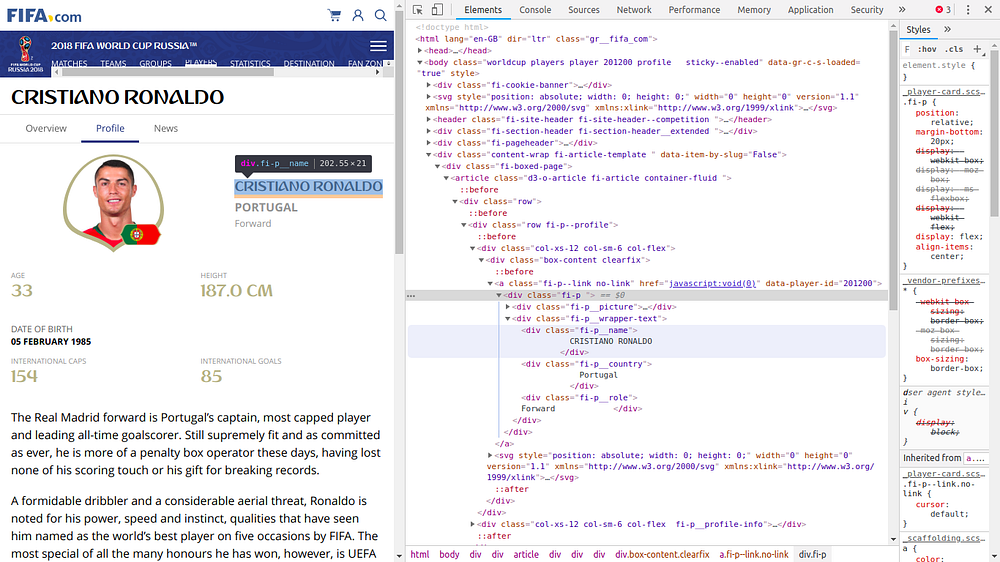
Что вы видите? Я на странице профиля Роналду. Я открыл код этой страницы. Что я выделил? Его имя. Потому что я хочу его проскрапить. Для этого я смотрю, как оно записано в коде. Оказывается, что для него есть отдельный раздел и имя класса. Их-то мы и будем использовать. Теперь посмотрите на код.
#Импортируем библиотеки
import requests
from bs4 import BeautifulSoup
#Запрашиваем URL
page = requests.get("https://www.fifa.com/worldcup/players/player/201200/profile.html")
#Скачиваем страницу
soup = BeautifulSoup(page.content,"html.parser")
#Скрапим данные
name = soup.find("div",{"class":"fi-p__name"})
print(name)
Мы запросили страницу, где хранится профиль Роналду. Создали экземпляр. Теперь с помощью метода BeautifulSoup find мы находим то, что нам нужно. Нам нуженdiv, но их очень много в коде, какой именно нужен нам? Нам нужен только div с именем классаfi-p__name. В этом разделе записано имя игрока. И вот, его мы и получаем.

Упрощаем вывод
#Импортируем библиотеки
import requests
from bs4 import BeautifulSoup
#Запрашиваем URL
page = requests.get("https://www.fifa.com/worldcup/players/player/201200/profile.html")
#Скачиваем страницу
soup = BeautifulSoup(page.content,"html.parser")
#Скрапим данные
name = soup.find("div",{"class":"fi-p__name"}).text.replace("\n","").strip()
print(name)
Мы не может хранить данные в таком формате, правда? Они нам нужны в виде текста. Для этого мы добавляем в конце.text. И теперь получаем это.

Всё ещё не идеально, осталось несколько “\n”. Их тоже надо удалить. Поэтому заменяем их на пустоту. Получим что-то такое.

Ну и ещё удалим пробелы перед и после имени. Для этого напишем.strip() и в итоге получаем:

Вот так мы смогли извлечь имя одного игрока. Так же мы можем извлечь и другие данные о нем, которые вы видели на странице. Например, рост, национальность, амплуа и количество забитых голов.
Шаг 3 — Все данные о первом игроке
#Импортируем библиотеки
import requests
from bs4 import BeautifulSoup
#Запрашиваем URL
page = requests.get("https://www.fifa.com/worldcup/players/player/201200/profile.html")
#Скачиваем страницу
soup = BeautifulSoup(page.content,"html.parser")
#Скрапим данные
#Name #Country #Role #Age #Height #International Caps #International Goals
player_name = soup.find("div",{"class":"fi-p__name"}).text.replace("\n","").strip()
player_country = soup.find("div",{"class":"fi-p__country"}).text.replace("\n","").strip()
player_role = soup.find("div",{"class":"fi-p__role"}).text.replace("\n","").strip()
player_age = soup.find("div",{"class":"fi-p__profile-number__number"}).text.replace("\n","").strip()
player_height = soup.find_all("div",{"class":"fi-p__profile-number__number"})[1].text.replace("\n","").strip()
player_int_caps = soup.find_all("div",{"class":"fi-p__profile-number__number"})[2].text.replace("\n","").strip()
player_int_goals = soup.find_all("div",{"class":"fi-p__profile-number__number"})[3].text.replace("\n","").strip()
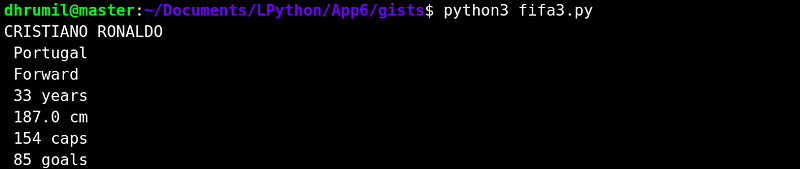
print(player_name,"\n",player_country,"\n",player_role,"\n",pl
У каждого параметра есть свой класс, что облегчает нам работу. Однако у роста, количества матчей и голов класса нет. Не волнуйтесь. Мы используем метод find_all и затем по порядку выведем каждый параметр со значением. Выведенные данные буду выглядеть как-то так.
Шаг 4 — Все данные по всем 736 игрокам
Это данные по одному игроку, что делать с остальными футболистами? Профили всех игроков находятся на разных страницах. Их все нужно объединить в один скрипт, а не делать отдельный скрипт для каждого футболиста. Что для этого нужно сделать? Найти способ одновременно скачать все URL.
Как вы видите, URL профиля Роналду: https://fifa.com/worldcup/players/player/201200/profile.html. Есть ли в этой ссылке часть, которая будет общей для всех игроков? Да, есть. Только ID игрока (у Роналду 201200) уникален для каждой страницы. То есть перед тем, как собирать все данные, нам нужно собрать ID футболистов. Делаем так же, как и с именем, но в этот раз используем цикл.
Просматривая исходный код, я нашел эту ссылку, в которой упоминаются все ID игроков. Поэтому для сбора ID я и взял эту ссылку.
#Импортируем библиотеки
import requests
from bs4 import BeautifulSoup
import pandas
#Пустой список для хранения данных
id_list = []
#Скачиваем URL
request = requests.get("https://www.fifa.com/worldcup/players/_libraries/byposition/[id]/_players-list")
soup = BeautifulSoup(request.content,"html.parser")
#Повторяем цикл, чтобы найти все ID
for ids in range(0,736):
all = soup.find_all("a","fi-p--link")[ids]
id_list.append(all['data-player-id'])
#Создаем блок данных, чтобы хранить данные
df = pandas.DataFrame({
"Ids":id_list
})
df.to_csv('player_ids.csv', index = False)
print(df,"\n Success")На сайте всего 736 игроков, следовательно, столько раз мы повторяем цикл. Вместо divу нас в этот разa, тег привязки. Но суть осталась та же: находим нужный класс. В начале создаем пустой список и добавляем ID в этот список. А в конце создаем блок данных, чтобы сохранить эти ID и экспортировать их в файл .CSV.

Сбор всех данных обо всех игроках
Теперь мы собрали все ID и знаем, как собрать данные по каждому параметру. Теперь нам нужно каждый ID использовать в цикле. Смотрите.
#Импортируем библиотеки
import requests
from bs4 import BeautifulSoup
import pandas
from collections import OrderedDict
#Собираем данные по ID игроков
player_ids = pandas.read_csv("player_ids.csv")
ids = player_ids["Ids"]
#Указываем базовый URl и список игроков
base_url = "https://www.fifa.com/worldcup/players/player/"
player_list = []
#Повторяем цикл, чтобы собрать все данные по игрокам
for pages in ids:
#Используем OrderedDict вместо Dict (смотри пояснение)
d=OrderedDict()
#Сбор URL одного за другим
print(base_url+str(pages)+"/profile.html")
request = requests.get(base_url+str(pages)+"/profile.html")
#Обработка данных
content = request.content
soup = BeautifulSoup(content,"html.parser")
#Скрапинг данных
#Name #Country #Role #Age #Height #International Caps #International Goals
d['Name'] = soup.find("div",{"class":"fi-p__name"}).text.replace("\n","").strip()
print(d['Name'])
d['Country'] = soup.find("div",{"class":"fi-p__country"}).text.replace("\n","").strip()
d['Role'] = soup.find("div",{"class":"fi-p__role"}).text.replace("\n","").strip()
d['Age'] = soup.find("div",{"class":"fi-p__profile-number__number"}).text.replace("\n","").strip()
d['Height(cm)'] = soup.find_all("div",{"class":"fi-p__profile-number__number"})[1].text.replace("\n","").strip()
d['International Caps'] = soup.find_all("div",{"class":"fi-p__profile-number__number"})[2].text.replace("\n","").strip()
d['International Goals'] = soup.find_all("div",{"class":"fi-p__profile-number__number"})[3].text.replace("\n","").strip()
#Добавление словаря к списку игроков
player_list.append(d)
#Создание блока данных pandas и сохранение файла в формате .csv
df = pandas.DataFrame(player_list)
df.to_csv('Players_info.csv', index = False)
print("Success \n")Мы создаем базовый URL, чтобы при каждом повторении цикла менялся только ID игрока, так мы получим данные по всем URL. Ещё кое-что, вместо списка я использую словарь, потому что мы работаем с несколькими параметрами. При этом я использую конкретно Ordered Dictionary, потому что нам нужен вывод не отсортированных данных в определенном порядке. Добавляем словарь в список и создаем блок данных. Сохраняем данные в CSV файл и всё готово. Запустив скрипт, я вывел только имена игроков, так я могу удостовериться, что данные собраны правильно.
Мы это сделали. Если вы дошли до этого шага, вы отличный ученик. Я добавил данные в мой профиль Kaggle, можете ознакомиться.
Шаг 5 — Статистика
Мы же не остановимся на этом, правда? На странице футболистов я нашел эту статистику по всему турниру, и мой мозг сказал: “Похоже, мы можем проскрапить ещё одну страницу”. Я потратил на сбор данных целый день, и эту статистику я тоже собрал. Но теперь вы уже знаете о скрапинге с помощью Python и BeautifulSoup всё, что нужно. Почему бы вам не попробовать самим?
Я знаю, что мой код можно по-разному улучшать. Но на данном этапе мы фокусируемся на обучении. Не важно, насколько ваша программа запутана, и сколько времени занимает её работа. Если вы нашли верное решение задачи, мы на верном пути. Вы учитесь новому, вот что сейчас важно. Другим второстепенным вещам вы можете научиться чуть позже.
Итоговые примечания
Сегодня вы изучили две новые библиотеки, а также научились использовать их для скачивания страниц и сбора с них необходимых данных. Разве это не здорово? Вы будете иметь преимущество перед конкурентами на собеседовании, если обладаете этими навыками. Приятного вам обучения.
P.S. Еслиэто читают сотрудники FIFA: данные были собраны исключительно в образовательных целях, а не для того, чтобы нарушить вашу политику защиты данных. Не подавайте на меня в суд.
Перевод статьи Dhrumil Patel: Master Python through building real-world applications (Part 6)





