
Spark — это фреймворк для обработки больших данных.
- Рассмотрим типичные ошибки и их устранение/оптимизации для совершенствования производительности и использования памяти приложений Spark.
- Сюда относятся оптимизация кластеров, настройки значений конфигурации, оптимизация на уровне машинных команд и т. д.
Ошибка № 1. Непонимание отложенных вычислений
В Spark код не выполняется построчно, в отличие от традиционных скриптов.
data = spark.read.csv("large_file.csv")
data.filter(data["age"] > 30)
print("Filtering done.")
- Здесь выполнится оператор
print, хотя фильтр в Spark еще не обработан.
В Spark используются отложенные вычисления, то есть преобразования выполняются, только когда активируется действие вроде .collect() или .saveAsTextFile(). Это чревато путаницей, если вы ожидаете немедленного выполнения.
- Разберитесь в разнице между преобразованиями и действиями. Преобразования — это отложенные операции, а действиями запускается выполнение.
data = spark.read.csv("large_file.csv")
filtered_data = data.filter(data["age"] > 30)
filtered_data.show() # Этим действием запускается выполнение
Ошибка № 2. Использование разделов по умолчанию без учета распределения данных
Некорректная разбивка данных на разделы чревата перекосами в распределении рабочей нагрузки, а в итоге — замедлением задач или даже сбоями.

- Игнорирование разбиения на разделы
Разбиение данных на разделы важно для производительности, особенно при объединении наборов данных. Без такой корректной разбивки данные в Spark многократно перемешиваются, что чревато снижением производительности.
При настройке заданий Spark очень важен параллелизм. Для обработки каждого раздела ~ задачи требуется одно ядро.
- Слишком много или слишком мало разделов
При большом количестве разделов добавляются лишние накладные расходы, а при малом недоиспользуются ресурсы кластера. Этот баланс определяется размером данных и ресурсами кластера. Общая рекомендация — количество разделов должно быть в 2–3 раза больше, чем ядер.
Отсутствие настройки разделов для большого набора данных чревата несбалансированной обработкой.
large_data = spark.read.csv("large_file.csv")
print(large_data.rdd.getNumPartitions()) # Здесь обнаруживается высокое или низкое количество разделов по умолчанию
2.2 Для настройки разделов используйте .repartition() или .coalesce().
partitioned_data = large_data.repartition(10)
print(partitioned_data.rdd.getNumPartitions()) # Теперь задано 10 разделов
.repartition(numPartitions):
- Используется для увеличения или уменьшения количества разделов. Данные перемешиваются в узлах кластера, так что это дорогостоящая операция.
- Она хороша для равномерного распределения данных, когда нужно больше разделов или после операции объединения.
- Используйте
.repartition(), когда требуется больше разделов или полное перемешивание.
.coalesce(numPartitions):
- В основном используется для уменьшения количества разделов. При этом избегается перемешивание, ведь разделы объединяются в одном узле, в итоге эта операция дешевле, чем
.repartition(). - Полезно для объединения разделов, особенно в конце обработки, для подготовки к выводу. Пример:
data.coalesce(5). - Используйте
.coalesce(), чтобы сократить разделы без перемешивания — для повышения эффективности.
Ошибка № 3. Некорректное использование кэширования / длительного сохранения
Отсутствие кэширования многократно используемых данных.
В Spark преобразования каждый раз пересчитываются. Если преобразования сложные, это недешево.
# Многократное использование данных без кэширования
filtered_data = data.filter(data["age"] > 30)
filtered_data.count()
filtered_data.show()
Каждым действием перезапускается этап фильтрации.
Используйте .cache() или .persist() для данных, многократно используемых в многочисленных действиях.
# Кэшируйте данные, если намерены использовать их повторно
filtered_data = data.filter(data["age"] > 30).cache()
filtered_data.count()
filtered_data.show() # Теперь это будет быстрее
3.1 Некорректное использование кэширования и длительного сохранения
Многие забывают о кэшировании и не используют, например, cache() или persist(), благодаря которым избегаются повторные вычисления в итерационных алгоритмах или повторный доступ.
- Но, если кэшировать все, проявятся проблемы использования памяти. Кэшируйте, только когда это необходимо, и применяйте
unpersist, когда данные больше не требуются.
3.2 Слишком много преобразований
Длинные цепочки преобразований без промежуточных действий или кэширования чреваты усложнением их отслеживания, увеличением времени выполнения. Иногда предпочтительнее разделить сложные цепочки, добавить действия или кэшировать данные.
Ошибка № 4. Неправильная настройка операций перемешивания
Непонимание принципов работы перемешивания чревато замедлениями или сбоями. Стандартная настройка перемешивания при больших объединениях чревата задержками или ошибками.
- Операции перемешивания, например join, groupBy, тяжелы для сети и памяти. Некорректные конфигурации чреваты невыполнением этих операций.
joined_data = large_data1.join(large_data2, "id")
joined_data.show()
- Связанные с перемешиванием конфигурации, такие как spark.sql.shuffle.partitions, корректируйте по размеру данных и при возможности сокращайте перемешивания.
spark.conf.set("spark.sql.shuffle.partitions", "100") # Корректируется по размеру данных
joined_data = large_data1.join(large_data2, "id")
joined_data.show()
Ошибка № 5. Сбор больших наборов данных в драйвер
Ошибка: использование .collect() или .take() с большими наборами данных.
all_data = data.collect() # Сбор всего набора данных в драйвер
Это чревато ошибками памяти, если data слишком большой.
- Использование больших действий
collect: этимcollectв драйвер приносится весь набор данных, что чревато сбоем драйвера, если набор данных слишком большой. Обычно предпочтительнее использовать такие действия, какtakeилиtakeSample, для небольших поднаборов данных и избегатьcollect, пока размер набора данных не станет управляемым. - В идеале ограничивайте размер собираемых данных или записывайте их прямо в хранилище, а не переносите их в драйвер.
sample_data = data.limit(1000).collect() # Собирается только управляемое количество
# Или же данные записываются прямо в хранилище
data.write.parquet("output_path")
Ошибка № 6. Игнорирование методов оптимизации
Неиспользование таких оптимизаций, как широковещательные соединения или оптимизатор Catalyst.
В Spark имеются оптимизации для повышения производительности, но нужно понимать, когда их использовать.
large_data.join(small_data, "id").show() # Медленное соединение большой и маленькой таблиц
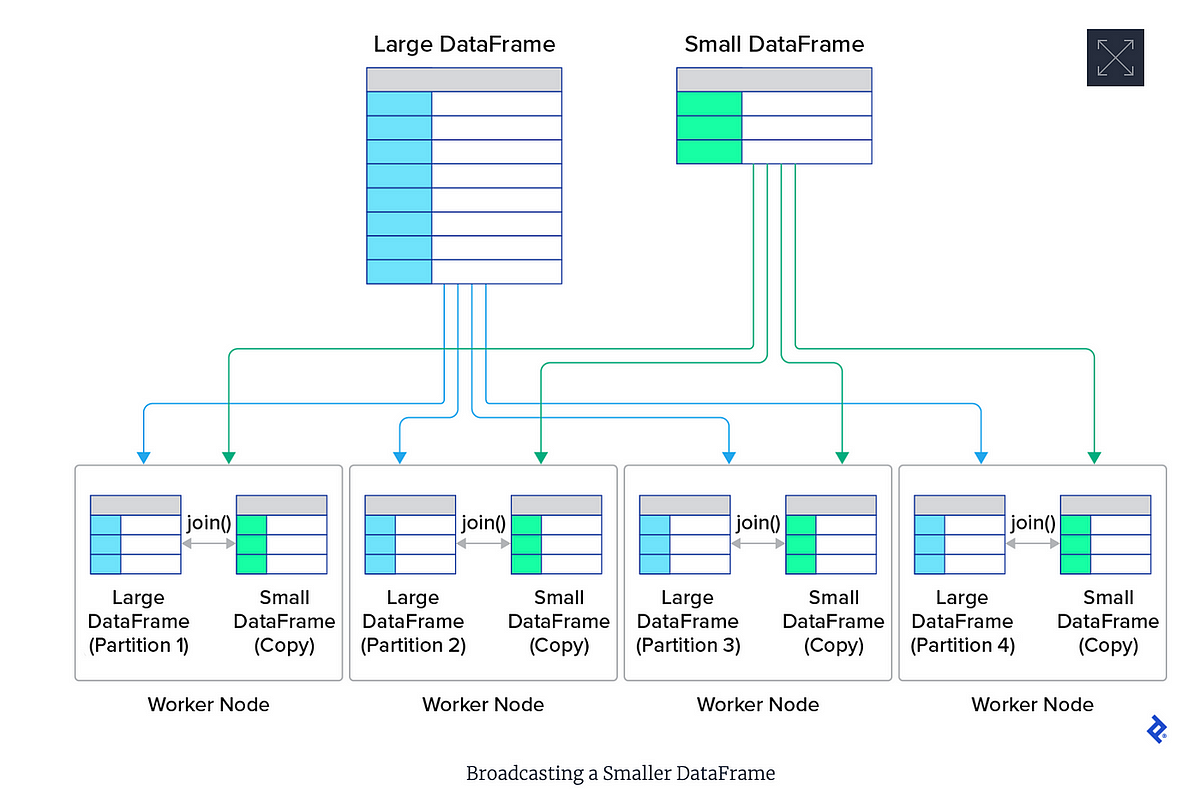
Используйте широковещательные соединения для маленьких таблиц и API-интерфейсы DataFrame, оптимизированные в Spark оптимизатором Catalyst.
# Используйте широковещательное соединение для небольших таблиц
from pyspark.sql.functions import broadcast
large_data.join(broadcast(small_data), "id").show() # Соединение оптимизируется при помощи «broadcast»
Ошибка № 7. Неэффективные агрегации
- Ошибка: запуск агрегаций без понимания их влияния на производительность.
Операции вроде .groupBy() или .reduceByKey() сопряжены с интенсивными перемешиваниями и на больших наборах данных замедляются. Где возможно, используйте предварительно агрегированные данные или выполняйте локальные агрегации перед перемешиваниями.
Пример:
# Вместо объединения больших данных напрямую
data.groupBy("category").sum("amount").show()
# Где возможно, используйте агрегацию на стороне карты
data = data.map(lambda x: (x['category'], x['amount'])) \
.reduceByKey(lambda a, b: a + b)
- Использование
groupByKeyвместоreduceByKey
Из groupByKey все значения с одним и тем же ключом отправляются одному исполнителю, что чревато проблемами использования памяти. В случае с reduceByKey перед отправкой данных по узлам в каждом разделе выполняется локальное сокращение, что в целом эффективнее.
Другие шаги…
Оптимизация конфигураций Spark: сюда относится изменение свойств Spark, настройка исполнителя Spark, настройка памяти Spark.
Оптимизация хранилища: использование корректной оптимизации формата файла, например ORC и Parquet экономичны по расходу памяти и оптимальнее в ускорении запросов.
Отслеживание этапов преобразования
При отладке/оптимизации важно логировать или отслеживать, какие преобразования применяются. В отсутствие логирования трудно выявлять проблемы и узкие места, когда случается сбой преобразования или действия.
Читайте также:
- Сколько Spark нужно памяти для обработки 100 Гб данных
- 8 экспертных советов по использованию Apache Spark
- Почему стоит избегать динамических ссылок
Читайте нас в Telegram, VK и Дзен
Перевод статьи Abhinav Vinci: Apache Spark — Common mistakes and fixes…




