
Я использую Python уже почти 5 лет. Автоматизация задач — одно из свойств этого языка, которое не перестает привлекать меня и стимулировать мои исследования. Углубленно изучив возможности автоматизации на Python в течение последнего года, я открыл для себя потрясающие пакеты, факты и скрипты. В этой статье поделюсь скриптами автоматизации, которые использую ежедневно и которые значительно повысили мою продуктивность и производительность.
1. Pomodoro (техника тайм-менеджмента)
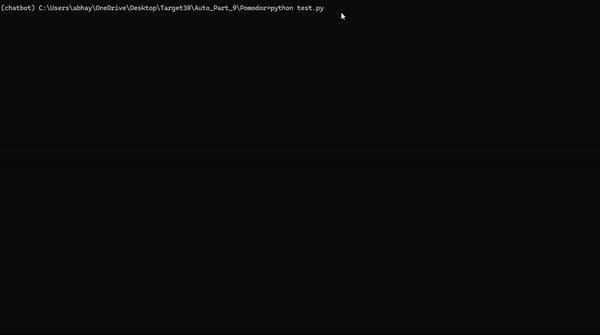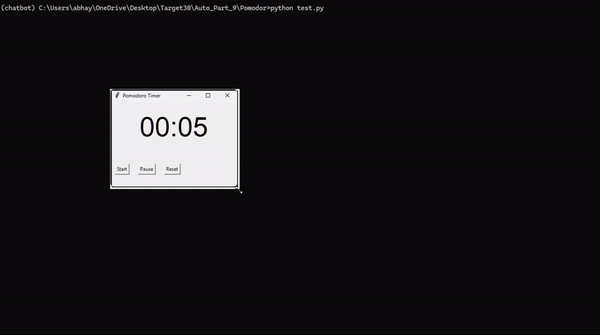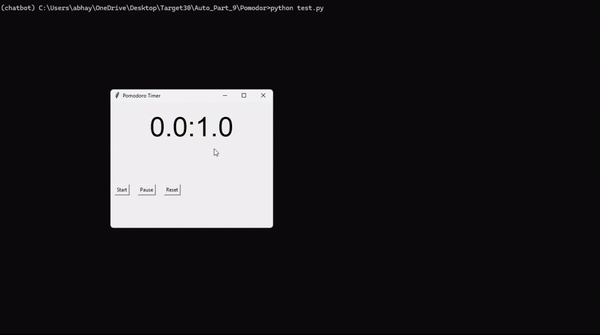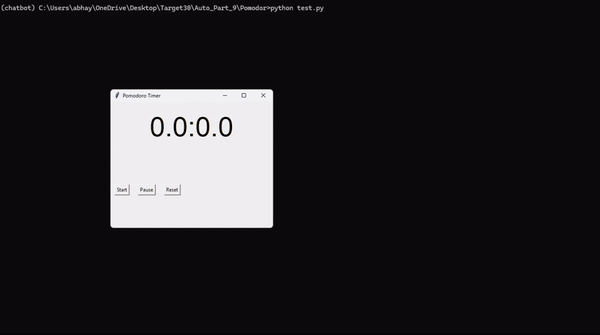
Pomodoro (метод помидора) — одна из простейших техник повышения продуктивности. Она основана на разбиении работы на интервалы (обычно продолжительностью 25 минут), разделенные короткими перерывами (5 минут). Эти отрезки времени (25 + 5 минут) называют «помидорами» — в честь кухонного таймера в виде помидора.
Приведенный здесь скрипт автоматизации расширяет возможности техники Pomodoro, добавляя принудительную блокировку устройства по истечении таймера, что гарантирует наступление столь необходимого перерыва.
import tkinter as tk
import time
import ctypes
import os
from threading import Timer
class PomodoroTimer:
def __init__(self, root):
self.root = root
self.root.title("Pomodoro Timer")
self.root.geometry("300x200")
self.time_var = tk.StringVar()
self.time_var.set("25:00")
self.running = False
self.paused = False
self.remaining_time = 25 * 60 # 25 минут
self.label = tk.Label(root, textvariable=self.time_var, font=("Helvetica", 48))
self.label.pack(pady=20)
self.start_button = tk.Button(root, text="Start", command=self.start_timer)
self.start_button.pack(side=tk.LEFT, padx=10)
self.pause_button = tk.Button(root, text="Pause", command=self.pause_timer)
self.pause_button.pack(side=tk.LEFT, padx=10)
self.reset_button = tk.Button(root, text="Reset", command=self.reset_timer)
self.reset_button.pack(side=tk.LEFT, padx=10)
def update_time(self):
if self.running:
minutes, seconds = divmod(self.remaining_time, 60)
self.time_var.set(f"{minutes:02}:{seconds:02}")
if self.remaining_time > 0:
self.remaining_time -= 1
self.root.after(1000, self.update_time)
else:
self.running = False
self.lock_screen()
def start_timer(self):
if not self.running:
self.running = True
self.paused = False
self.update_time()
def pause_timer(self):
if self.running:
self.running = False
self.paused = True
def reset_timer(self):
self.running = False
self.paused = False
self.remaining_time = 25 * 60
self.time_var.set("25:00")
def lock_screen(self):
if os.name == 'nt': # Windows
ctypes.windll.user32.LockWorkStation()
elif os.name == 'posix': # macOS and Linux
# Это условное обозначение, поскольку блокировка экрана в macOS/Linux обычно требует других действий.
# Для macOS используйте: os.system('/System/Library/CoreServices/Menu\ Extras/User.menu/Contents/Resources/CGSession -suspend')
# Для Linux используйте: os.system('gnome-screensaver-command --lock')
print("Locking screen on macOS/Linux is not implemented in this script.")
if __name__ == "__main__":
root = tk.Tk()
app = PomodoroTimer(root)
root.mainloop()
2. TodayScope (сбор фактов и новостей)
Мне всегда хотелось оставаться в курсе важных событий — в курсе жизни выдающихся современников, историй и событий в окружающем мире, — но без ежедневных усилий по поиску всего этого в Google. Именно поэтому я разработал этот скрипт автоматизации. Каждое утро, когда я включаю свой компьютер, он автоматически выдает мне топовые новости, интересные факты, произошедшие в мире в разные годы в этот день, и астрологический прогноз — и все это одним махом!
import tkinter as tk
from tkinter import ttk
import requests
from bs4 import BeautifulSoup
def get_trending_news():
"""Fetch and return trending news headlines."""
url = "http://newsapi.org/v2/top-headlines?country=us&apiKey=CREATE_YOUR_OWN"
page = requests.get(url).json()
articles = page["articles"]
results = [ar["title"] for ar in articles[:10]]
headlines = "\n".join(f"{i + 1}. {title}" for i, title in enumerate(results))
return headlines
def get_horoscope(sign_name):
"""Fetch and return horoscope for the specified sign."""
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
signs = {
'aries':1, 'taurus':2, 'gemini':3, 'cancer':4,
'leo':5, 'virgo':6, 'libra':7, 'scorpio':8,
'sagittarius':9, 'capricorn':10, 'aquarius':11, 'pisces':12
}
sign_id = signs.get(sign_name.lower())
if sign_id is None:
return "Sign not found."
url = f'https://www.horoscope.com/us/horoscopes/general/horoscope-general-daily-today.aspx?sign={sign_id}'
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, 'html.parser')
try:
horoscope_text = soup.select('.main-horoscope p')[0].getText().strip().capitalize()
sign = soup.select('h1')[0].getText().strip().capitalize()
return f"{sign} Horoscope: {horoscope_text}"
except:
return "Could not fetch the horoscope."
def get_history_today():
"""Fetch and return historical events that happened on this day."""
url = 'https://www.onthisday.com/'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
history_list = soup.select('.event')[:5] # Ограничение до 5 событий
events = [event.getText().strip() for event in history_list]
history_text = "\n".join(events)
return history_text
def show_popup():
# Получение информации из каждой функции
news = get_trending_news()
horoscope = get_horoscope('aries') # Замените "овен" ("aries") на нужный знак
history = get_history_today()
# Создание главного окна Tkinter
root = tk.Tk()
from datetime import datetime
# Получение текущей даты для отображения на графическом интерфейсе
current_date = datetime.now()
formatted_date = current_date.strftime("%d %b %Y")
root.title(f"Daily Update: {formatted_date}")
root.geometry("500x600")
root.configure(bg="#f0f0f5") # Установка цвета фона
# Настройка Canvas с полосой прокрутки
canvas = tk.Canvas(root, bg="#f0f0f5")
scrollbar = ttk.Scrollbar(root, orient="vertical", command=canvas.yview)
scrollable_frame = tk.Frame(canvas, bg="#f0f0f5")
scrollable_frame.bind(
"<Configure>",
lambda e: canvas.configure(scrollregion=canvas.bbox("all")))
canvas.create_window((0, 0), window=scrollable_frame, anchor="nw")
canvas.configure(yscrollcommand=scrollbar.set)
# Определение Canvas, полосы прокрутки и цветов
canvas.pack(side="left", fill="both", expand=True)
scrollbar.pack(side="right", fill="y")
header_font = ("Arial", 14, "bold")
text_font = ("Arial", 12)
colors_list = ["#E4E0E1","#FFDDC1", "#D4E157", "#81D4FA", "#FFAB91", "#A5D6A7", "#FFF59D", "#CE93D8", "#B39DDB", "#90CAF9", "#FFE082", "#FFCCBC", "#AED581", "#FFE0B2", "#80CBC4", "#F48FB1"]
section_bg = random.choice(colors_list)
# Функция создания раздела
def create_section(parent, title, content, color):
frame = tk.Frame(parent, bg=color, pady=10, padx=10)
frame.pack(fill="x", pady=5, padx=5)
title_label = tk.Label(frame, text=title, font=header_font, bg=color, fg="#333333")
title_label.pack(anchor="w", pady=(0, 5))
content_label = tk.Label(frame, text=content, justify="left", wraplength=450, bg=color, fg="#000000")
content_label.pack(anchor="w")
return frame
# Добавление раздела актуальных новостей
create_section(scrollable_frame, "Trending News", news, section_bg)
# Добавление раздела гороскопа
create_section(scrollable_frame, "Horoscope", horoscope, section_bg)
# Добавление раздела "Этот день в истории"
create_section(scrollable_frame, "On This Day", history, section_bg)
# Добавление кнопки закрытия внизу
close_button = ttk.Button(scrollable_frame, text="Close", command=root.destroy)
close_button.pack(pady=20)
root.mainloop()
# Запустите скрипт и добавьте функцию всплывающего окна при запуске
if __name__ == "__main__":
show_popup()

3. TrendyStocks (визуализация движения актива)
Есть такая поговорка: «Продается то, что у всех на виду».
На фондовом рынке чувственное восприятие может оказывать не менее сильное воздействие, чем цифры. Умные инвесторы знают, что дело не только в цифрах, но и в захватывающих историях, сенсационных новостях и ажиотаже, формирующих рынок.
Когда акции находятся в тренде — неважно, по хорошим или плохим причинам, — о них говорят больше людей и о них пишут больше статей. Растущая шумиха может дать ценные подсказки для принятия более разумных решений о покупке или продаже.
Этот скрипт автоматизации использует Google Trends для создания графика любого финансового актива, что дает представление о его популярности и помогает определить стратегию инвестирования.
#!pip install pytrends
from pytrends.request import TrendReq
import matplotlib.pyplot as plt
# Функция для получения данных Google Trends
def get_google_trends_data(keywords, timeframe='today 3-m', geo='US'):
pytrends = TrendReq(hl='en-US', tz=360)
# Создание полезной нагрузки
pytrends.build_payload(keywords, cat=0, timeframe=timeframe, geo=geo, gprop='')
# Получение процентов с течением времени
interest_over_time_df = pytrends.interest_over_time()
return interest_over_time_df
# Примеры ключевых слов, относящихся к вашей статье
STOCKS = ["AMZN", "MSFT", "NVDA", "AAPL", "GOOG"]
# Получение данных Google Trends
trends_data = get_google_trends_data(STOCKS)
# Построение графика с данными
plt.figure(figsize=(20, 12))
trends_data.plot(title='Google Trends for STOCKS')
plt.xlabel('Date')
plt.ylabel('Interest Over Time')
plt.show()
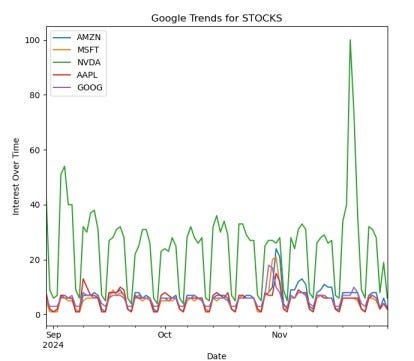
Применение скрипта:
- Принятие обдуманных финансовых решений, позволяющих сохранять репутацию продвинутого трейдера.
- Исследование ключевых слов, помогающих понять, что в тренде, а что нет.
4. Neatify (файловый органайзер)
В вашей папке загрузок царит полный хаос? Не можете найти важные файлы, когда они вам больше всего нужны? Пытались организовать папку бесчисленное количество раз, но так и не смогли?
Этот универсальный скрипт автоматизации изменит вашу организацию и управление файлами всего за несколько минут! Просто укажите путь к папке, которую нужно очистить, и скрипт начнет творить волшебство:
- Выполнит сортировку по расширению файлов: автоматически распределит все файлы по отдельным папкам на основе их расширений для более организованной структуры.
- Избавит от дубликатов файлов: обнаружит и удалит дубликаты файлов путем сравнения их хэшей, чтобы не допустить засорения хранилища лишними копиями.
- Организует документы по дате: упорядочит файлы в папках на основе дат их создания или последнего изменения, что упростит поиск файлов по периоду.
С помощью этого инструмента двойного назначения вы получите чистую, логичную структуру файлов, свободную от дубликатов и организованную по типам и времени. Эффективность еще никогда не достигалась так просто!
import os
import shutil
import hashlib
from datetime import datetime
def get_file_hash(file_path):
"""Calculate the SHA-256 hash of a file."""
with open(file_path, 'rb') as f:
return hashlib.sha256(f.read()).hexdigest()
def organize_by_date_and_extension(folder_path):
"""Organize files by date, then by extension, and handle duplicates."""
# Создание папки "Дубликаты" в корневом каталоге.
duplicates_folder = os.path.join(folder_path, '_Duplicates')
os.makedirs(duplicates_folder, exist_ok=True)
# Словарь для хранения хэшей файлов с целью обнаружения дубликатов
file_hashes = {}
# Итерация по всем файлам в каталоге
all_files = [os.path.join(folder_path, f) for f in os.listdir(folder_path) if os.path.isfile(os.path.join(folder_path, f))]
for file_path in all_files:
# Получение даты модификации файла
modification_time = os.path.getmtime(file_path)
modification_date = datetime.fromtimestamp(modification_time).strftime('%Y-%m-%d')
# Создание папки для даты модификации, если ее не существует
date_folder = os.path.join(folder_path, modification_date)
os.makedirs(date_folder, exist_ok=True)
# Вычисление хэша файла
file_hash = get_file_hash(file_path)
# Проверка на наличие дубликатов
if file_hash in file_hashes:
# Файл является дубликатом, перемещение его в папку "Дубликаты"
shutil.move(file_path, os.path.join(duplicates_folder, os.path.basename(file_path)))
print(f"Moved duplicate file {os.path.basename(file_path)} to Duplicates folder.")
else:
# Сохраните хэш файла, чтобы предотвратить появление дубликатов в будущем
file_hashes[file_hash] = file_path
# Перемещение файла в папку date
new_path = os.path.join(date_folder, os.path.basename(file_path))
shutil.move(file_path, new_path)
# Упорядочивание файлов в папке date по расширению
_, extension = os.path.splitext(new_path)
extension = extension.lower()
extension_folder = os.path.join(date_folder, extension[1:]) # Удаление точки из расширения
os.makedirs(extension_folder, exist_ok=True)
# Перемещение файла в папку, соответствующую расширению
shutil.move(new_path, os.path.join(extension_folder, os.path.basename(new_path)))
print(f"Moved {os.path.basename(new_path)} to {extension_folder}.")
print("Files organized by date, extension, and duplicates handled successfully!")
if __name__ == "__main__":
# Укажите каталог для организации
folder_path = input("Enter the path to the folder to organize: ")
organize_by_date_and_extension(folder_path)

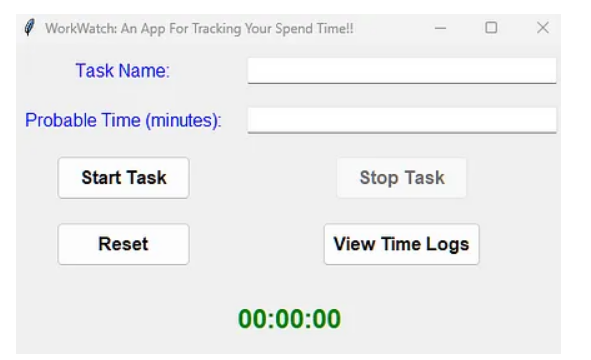
5. ClockWork (учет времени и задач)
Учет рабочего времени помогает выявлять закономерности, оптимизировать рабочие процессы и сохранять подотчетность. Это ключевой инструмент, позволяющий превратить ваши усилия в измеримый прогресс и сохранить ценность каждой минуты.
Ручной учет задач и времени может быстро стать непреодолимой проблемой. Запоминание стартового времени, расчет продолжительности процессов и ведение журналов нарушает рабочий процесс и допускает возможность ошибок. И что в итоге? Инструмент повышения производительности превращается в еще одну задачу в вашем списке.
Этот скрипт автоматизации устраняет перечисленные проблемы с помощью простого, интуитивно понятного решения. Он автоматизирует мониторинговый процесс, позволяя вам устанавливать пользовательские сроки выполнения задач, отслеживать прогресс в режиме реального времени и автоматически генерировать подробные журналы, чтобы сосредоточиться на том, что действительно важно.
import tkinter as tk
from tkinter import ttk, messagebox
import csv
import time
from datetime import datetime
class TaskTrackerApp:
def __init__(self, root):
self.root = root
self.root.title("ClockWork: Time Tracking Made Easy")
self.task_name_var = tk.StringVar()
self.probable_time_var = tk.IntVar()
self.start_time = None
# Настройка элементов пользовательского интерфейса
self.setup_ui()
# Создайте файл журнала времени, если он не существует
self.create_log_file()
def setup_ui(self):
style = ttk.Style()
style.configure("TLabel", font=("Helvetica", 12))
style.configure("TButton", font=("Helvetica", 12, 'bold'), padding=6)
# Элементы пользовательского интерфейса
ttk.Label(self.root, text="Task Name:", foreground="blue").grid(row=0, column=0, padx=10, pady=10)
ttk.Entry(self.root, textvariable=self.task_name_var, width=30).grid(row=0, column=1, padx=10, pady=10)
ttk.Label(self.root, text="Probable Time (minutes):", foreground="blue").grid(row=1, column=0, padx=10, pady=10)
ttk.Entry(self.root, textvariable=self.probable_time_var, width=30).grid(row=1, column=1, padx=10, pady=10)
ttk.Button(self.root, text="Start Task", command=self.start_task).grid(row=2, column=0, padx=10, pady=10)
self.stop_button = ttk.Button(self.root, text="Stop Task", command=self.stop_task, state=tk.DISABLED)
self.stop_button.grid(row=2, column=1, padx=10, pady=10)
ttk.Button(self.root, text="Reset", command=self.reset_task).grid(row=3, column=0, padx=10, pady=10)
ttk.Button(self.root, text="View Time Logs", command=self.view_time_logs).grid(row=3, column=1, padx=10, pady=10)
self.timer_label = ttk.Label(self.root, text="00:00:00", font=("Helvetica", 18, 'bold'), foreground="green")
self.timer_label.grid(row=4, column=0, columnspan=2, padx=10, pady=20)
def create_log_file(self):
with open("time_log.csv", "a", newline="") as file:
writer = csv.writer(file)
if file.tell() == 0:
writer.writerow(['Task Name', 'Probable Time (minutes)', 'Start Time', 'End Time', 'Time Spent (minutes)', 'Time Difference (minutes)'])
def start_task(self):
task_name = self.task_name_var.get()
if task_name:
self.start_time = time.time()
self.start_button.config(state=tk.DISABLED)
self.stop_button.config(state=tk.NORMAL)
self.update_timer()
def stop_task(self):
self.stop_button.config(state=tk.DISABLED)
self.start_button.config(state=tk.NORMAL)
time_spent = round((time.time() - self.start_time) / 60, 2)
self.log_time(time_spent)
def update_timer(self):
if self.start_time:
time_spent = time.time() - self.start_time
time_str = time.strftime('%H:%M:%S', time.gmtime(time_spent))
self.timer_label.config(text=time_str)
self.root.after(1000, self.update_timer)
def log_time(self, time_spent):
end_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
time_diff = round(time_spent - self.probable_time_var.get(), 2)
with open("time_log.csv", "a", newline="") as file:
writer = csv.writer(file)
writer.writerow([self.task_name_var.get(), self.probable_time_var.get(), self.start_time, end_time, time_spent, time_diff])
def reset_task(self):
self.task_name_var.set("")
self.probable_time_var.set("")
self.timer_label.config(text="00:00:00")
self.start_button.config(state=tk.NORMAL)
self.stop_button.config(state=tk.DISABLED)
def view_time_logs(self):
try:
with open("time_log.csv", "r") as file:
logs = list(csv.reader(file))
if len(logs) > 1:
log_window = tk.Toplevel(self.root)
log_window.title("Time Logs")
text_area = tk.Text(log_window, height=20, width=120)
text_area.pack(padx=10, pady=10)
for log in logs[1:]:
task_name, probable_time, start_time, end_time, time_spent, time_diff = log
color = "green" if float(time_diff) < 0 else "red"
text_area.insert(tk.END, f"Task: {task_name}, Probable: {probable_time} min, Time Spent: {time_spent} min, Diff: {time_diff} min\n", color)
text_area.config(state=tk.DISABLED)
text_area.tag_config("green", foreground="green")
text_area.tag_config("red", foreground="red")
else:
messagebox.showinfo("No Logs", "No task logs found.")
except Exception as e:
messagebox.showerror("Error", f"Could not read time logs: {e}")
if __name__ == "__main__":
root = tk.Tk()
app = TaskTrackerApp(root)
root.mainloop()
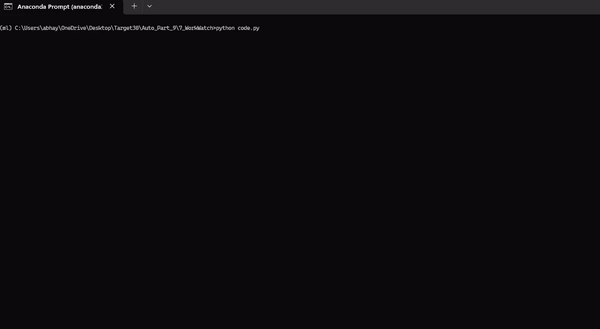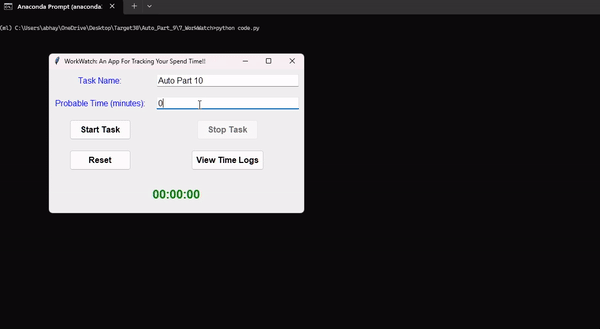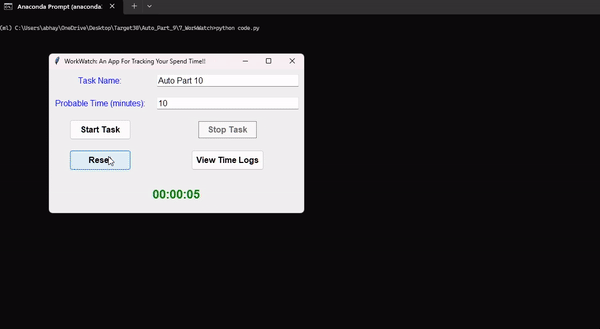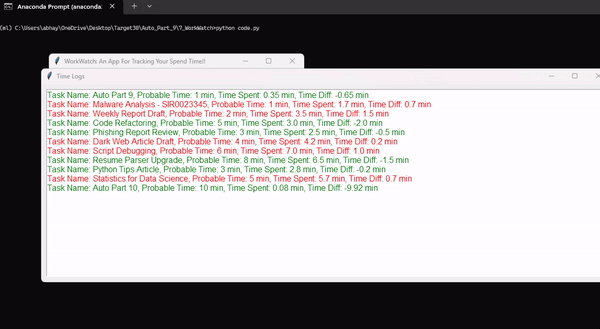
Применение скрипта:
- Мониторинг времени.
- Отслеживание прогресса в обучении моделей.
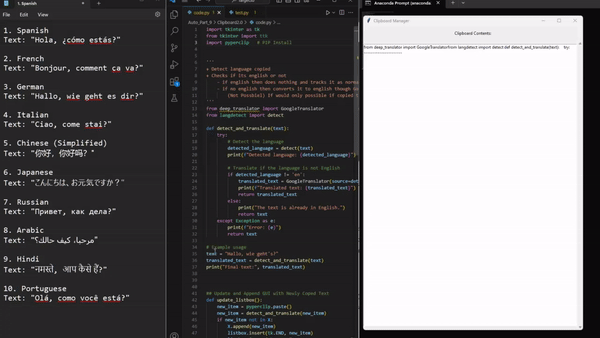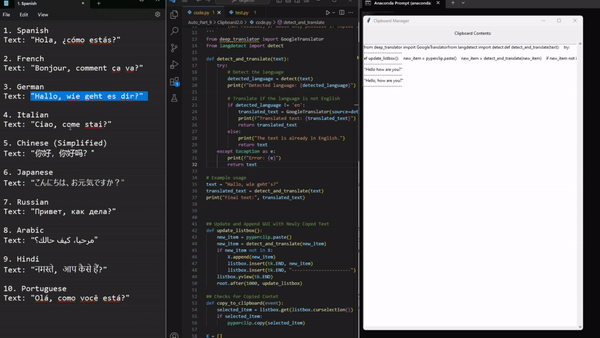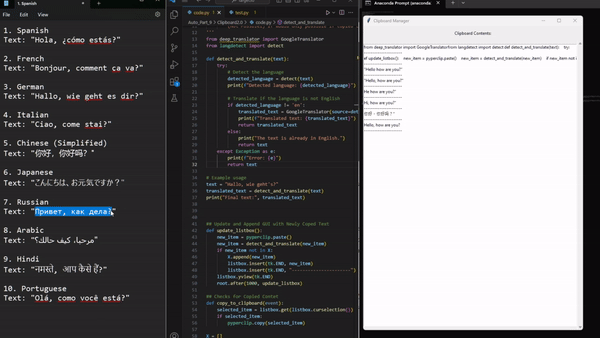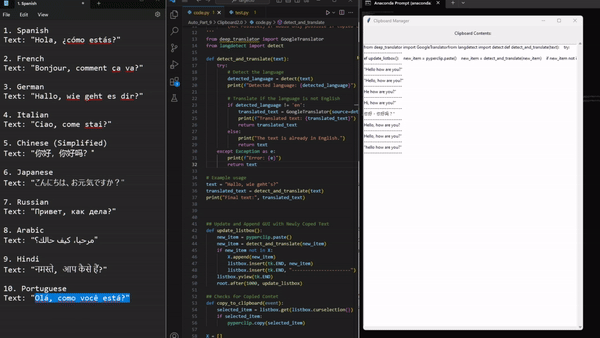
6. ClipTranslate (быстрое преобразование текстов)
Приходилось ли вам копировать текст, не будучи уверенным в том, что вы вставили его, не потеряв важные фрагменты? Сталкивались ли с текстом на иностранном языке, постоянно заходя в Google Translate для быстрого перевода? Хотели бы иметь инструмент, который фиксирует все, что вы копируете, и без труда переводит текст на указанный вами язык? Этот скрипт автоматизации — ваш помощник в буфере обмена. Он отслеживает весь копируемый текст и обеспечивает его беспрепятственный перевод.
import tkinter as tk
from tkinter import ttk
import pyperclip # установка с PIP
from deep_translator import GoogleTranslator
from langdetect import detect
def detect_and_translate(text):
try:
# Определение языка
detected_language = detect(text)
print(f"Detected language: {detected_language}")
if detected_language != 'en':
translated_text = GoogleTranslator(source=detected_language, target='en').translate(text)
print(f"Translated text: {translated_text}")
return translated_text
else:
print("The text is already in English.")
return text
except Exception as e:
print(f"Error: {e}")
return text
## Обновление и добавление в графический интерфейс нового скопированного текста
def update_listbox():
new_item = pyperclip.paste()
new_item = detect_and_translate(new_item)
if new_item not in X:
X.append(new_item)
listbox.insert(tk.END, new_item)
listbox.insert(tk.END, "----------------------")
listbox.yview(tk.END)
root.after(1000, update_listbox)
## Проверка скопированного контента
def copy_to_clipboard(event):
selected_item = listbox.get(listbox.curselection())
if selected_item:
pyperclip.copy(selected_item)
X = []
root = tk.Tk()
root.title("Clipboard Manager")
root.geometry("500x500")
root.configure(bg="#f0f0f0")
frame = tk.Frame(root, bg="#f0f0f0")
frame.pack(padx=10, pady=10)
label = tk.Label(frame, text="Clipboard Contents:", bg="#f0f0f0")
label.grid(row=0, column=0)
scrollbar = tk.Scrollbar(root)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
listbox = tk.Listbox(root, width=150, height=150, yscrollcommand=scrollbar.set)
listbox.pack(pady=10)
scrollbar.config(command=listbox.yview)
update_listbox()
listbox.bind("<Double-Button-1>", copy_to_clipboard)
root.mainloop()
7. Video2GIF (конвертирование видео в GIF-формат)
Блогеры и создатели контента знают, как важны GIF-файлы. Видео отлично подходит для демонстрации контента и обмена им, но когда дело доходит до вставки в посты блога, GIF-файлы становятся лучшим выбором. Этот скрипт автоматизации может конвертировать видео в GIF-формат без водяных знаков с помощью нескольких строк кода.
from moviepy.editor import VideoFileClip
def convert_video_to_gif(video_path, gif_path, start_time=0, duration=None):
# Загрузка видеоклипа
clip = VideoFileClip(video_path)
# Продолжительность GIF; если не указано, используйте все видео.
if duration:
clip = clip.subclip(start_time, start_time + duration)
else:
clip = clip.subclip(start_time, clip.duration)
# Запись видеоклипа в формате GIF
clip.write_gif(gif_path)
print(f"GIF saved to {gif_path}")
video_path = "Sample_Video.mp4" # Путь к вашему видеофайлу
gif_path = "output.gif" # Путь, по которому будет сохранен gif
convert_video_to_gif(video_path, gif_path, start_time=0, duration=15)
8. WordCounter (подсчет слов)
Один из афоризмов веб-сериала «BoJack Horseman» («Конь БоДжек») звучит так: «Каждый день становится немного легче. Только нужно прилагать усилия каждый день — и это самое сложное. Зато потом становится легче».
Один из самых ценных советов, полученных мной в первые дни ведения блога, — регулярно писать определенное количество слов. Однако тогда в моем распоряжении не было достаточно дешевого или простого способа отслеживать количество слов, которые я написал за день. Этот скрипт автоматизации стал моим спасителем: он отслеживает количество написанных за день слов и поощряет при достижении ежедневного объема.
import pynput
from pynput.keyboard import Key, Listener
from win10toast import ToastNotifier
# Инициализация объекта ToastNotifier
toaster = ToastNotifier()
keys = []
word_count_session = 0
word_count = 1000 # Общее количество слов в разных сессиях
target_word_count = 1000 # Замените на желаемое количество слов
def on_press(key):
global word_count_session, keys
if key == Key.space:
word_count_session += 1
elif key == Key.esc:
return False
keys.append(key)
write_file(keys)
if word_count_session >= 1000:
session_info()
def session_info():
global word_count, word_count_session
word_count += word_count_session
word_count_session = 0
if word_count > target_word_count:
# Notification Message
message = f"Congrats! You have achieved your {target_word_count} Words Daily Target"
toaster.show_toast("Counter ⏱️", message, duration=10)
def write_file(keys):
with open('log.txt', 'w') as f:
for key in keys:
if key == Key.space:
f.write(' ')
else:
k = str(key).replace("'", "")
if k[0:3] == 'Key':
pass
else:
f.write(k)
with Listener(on_press=on_press) as listener:
listener.join()
Более продвинутую версию с живым счетчиком, графиком частотности используемых слов и настройкой объема текста можете посмотреть здесь.
9. FakeFill (генерация фейковых наборов данных)
Если вы занимаетесь тестированием моделей или просто заполняете формы случайной информацией, этот скрипт автоматизации на Python поможет вам. Он генерирует реалистично выглядящие фейковые наборы данных, идеально подходящие для тестирования, разработки и моделирования. Этот инструмент быстро и эффективно создает любые образцы данных — от имен и электронных адресов до номеров телефонов.
import streamlit as st
import pandas as pd
from mimesis import Person, Address
from mimesis.enums import Gender
from io import StringIO
# Словарь доступных генераторов данных
generators = {
"Name": lambda: person.full_name(),
"Email": lambda: person.email(),
"Address": lambda: address.address(),
"Phone Number": lambda: person.telephone(),
"Job": lambda: person.occupation(),
}
# Функция генерации данных
def generate_data(columns, rows):
data = {col: [generators[col]() for _ in range(rows)] for col in columns}
return pd.DataFrame(data)
# Интерфейс Streamlit
st.title("Test Data Generator 📊")
# Боковая панель для настроек
st.sidebar.header("Data Generation Settings")
selected_columns = st.sidebar.multiselect("Select Columns:", list(generators.keys()))
num_rows = st.sidebar.number_input("Number of Rows:", min_value=1, max_value=1000, value=10)
if st.sidebar.button("Generate Data"):
if selected_columns:
person = Person() # Инициализация провайдера Mimesis Person
address = Address() # Инициализация провайдера Mimesis Address
df = generate_data(selected_columns, num_rows)
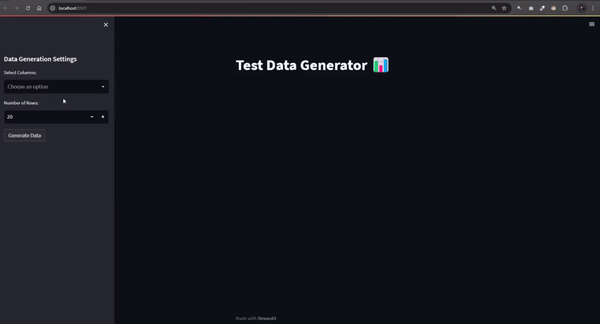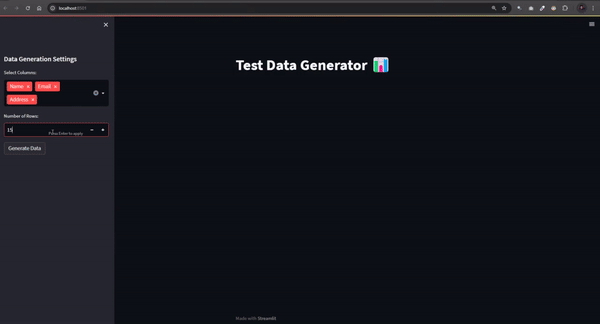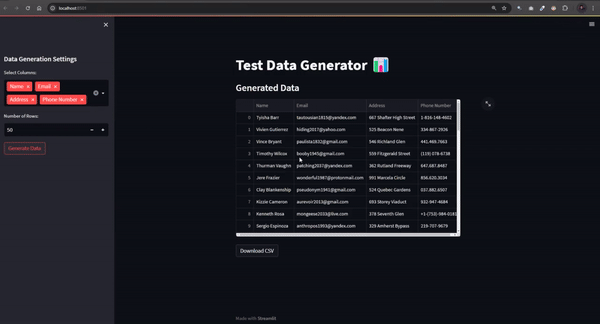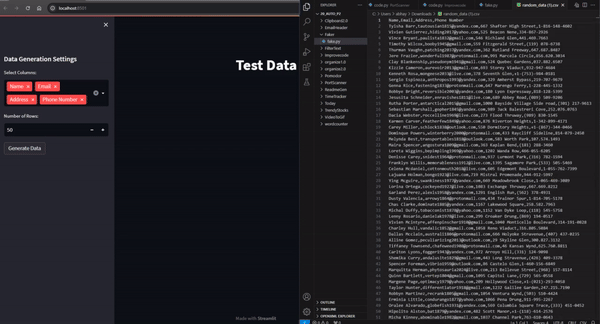
st.write("### Generated Data")
st.dataframe(df)
# Преобразование DataFrame в CSV и создание ссылки на скачивание
csv = df.to_csv(index=False)
st.download_button(label="Download CSV", data=csv, file_name="random_data.csv", mime="text/csv")
else:
st.warning("Please select at least one column.")
10. HeaderSpy (извлечение ключевой информации из заголовков)
Заголовки электронной корреспонденции — важнейшие компоненты метаданных писем, раскрывающие важные сведения об их происхождении, способе передачи и содержании. Хотя по умолчанию они не видны получателю, вы можете просмотреть их с помощью функций почтового клиента или специализированных инструментов. Эти заголовки содержат различные поля, каждое из которых выполняет определенную функцию.
Они играют важную роль в бесперебойной работе систем электронной почты, помогая проверять подлинность сообщений и обеспечивая прозрачность информации об отправителе. Заголовки электронной почты играют важную роль в предотвращении спама, проверке личности отправителя и устранении проблем с доставкой.
Если вы никогда не видели заголовки электронных писем, поверьте, они далеко не так просты на вид. Этот скрипт автоматизации извлекает ключевую информацию из заголовков электронных писем, помогая определить, является ли письмо поддельным, возвращенным или потенциально вредоносным.
import email
import quopri
from email import policy
from email.parser import BytesParser
def parse_email(file_path):
with open(file_path, 'rb') as file:
msg = BytesParser(policy=policy.default).parse(file)
print("From:", msg.get("From", "N/A"))
print("To:", msg.get("To", "N/A"))
print("Subject:", msg.get("Subject", "N/A"))
print("Date:", msg.get("Date", "N/A"))
print("Message ID:", msg.get("Message-ID", "N/A"))
print("X-Mailer:", msg.get("X-Mailer", "N/A"))
# Additional Information
print("\n--- Additional Information ---\n")
print("SPF:", msg.get("Received-SPF", "N/A"))
print("DKIM:", msg.get("DKIM-Signature", "N/A"))
print("DMARC:", msg.get("DMARC-Filter", "N/A"))
print("SENDERIP:", msg.get("X-Sender-IP", "N/A"))
print("RETURN PATH:", msg.get("Return-Path", "N/A"))
print("Reply-To:", msg.get("Reply-To", "N/A"))
print('Authentication Results:\n', msg.get('Authentication-Results','N/A'))
print('Message ID', msg.get('Message-Id','N/A'))
def main():
email_file_path = "/content/Sample.eml" ## Email-файл
parse_email(email_file_path)
if __name__ == "__main__":
main()
11. BetterEmails (моментальная рассылка писем)
Рассылки по электронной почте — основа онлайн-взаимодействия, при котором каждый подписчик является ценным членом цифрового сообщества. Электронные рассылки формируют основу успешного цифрового маркетинга, напрямую связывая вас с вашей аудиторией.
Специалисту по цифровому влиянию важно поддерживать постоянную связь со своими подписчиками. Но регулирование таких отношений вручную может быстро стать непосильной задачей, а стоимость сторонних инструментов способна истощить ваш бюджет.
Приведенный ниже скрипт автоматизации использует SMTP-сервер Gmail для массовой рассылки писем за считанные минуты. Имея в своем распоряжении полную настройку, вы получаете абсолютный контроль над своей аудиторией — и при этом избавляетесь от больших затрат.
import smtplib, ssl, email
from email import encoders
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.utils import formataddr
import pandas as pd
# Учетные данные электронной почты отправителя
sender_email = "YOUR_EMAIL"
password = "YOUR_EMAIL_PASSWORD"
# Загрузка HTML-шаблона
with open("template.html", "r") as file:
html_template = file.read()
# Загрузка данных получателя из файла CSV
recipients_df = pd.read_csv("recipients.csv") # CSV должен содержать колонки 'имя' и 'email'
# Функция для отправки email-сообщения одному получателю
def send_email(recipient_name, recipient_email):
# Создание email-сообщения MIMEMultipart
msg = MIMEMultipart("alternative")
msg["Subject"] = "Welcome Pythoneer!!!"
msg["From"] = formataddr(("The Pythoneers", "Publication"))
msg["To"] = recipient_email
# Настройка HTML-контента
personalized_html = html_template.replace("[User Name]", recipient_name)
# Прикрепление к электронному письму персонализированного HTML-контента
part = MIMEText(personalized_html, "html")
msg.attach(part)
# Отправка письма
context = ssl.create_default_context()
with smtplib.SMTP_SSL("smtp.gmail.com", 465, context=context) as server:
server.login(sender_email, password)
server.sendmail("The Pythoneers", recipient_email, msg.as_string())
print(f"Email sent to {recipient_name} at {recipient_email}")
# Прохождение по каждому получателю и отправка письма
for _, row in recipients_df.iterrows():
send_email(row["name"], row["email"])
print("All emails have been sent!")
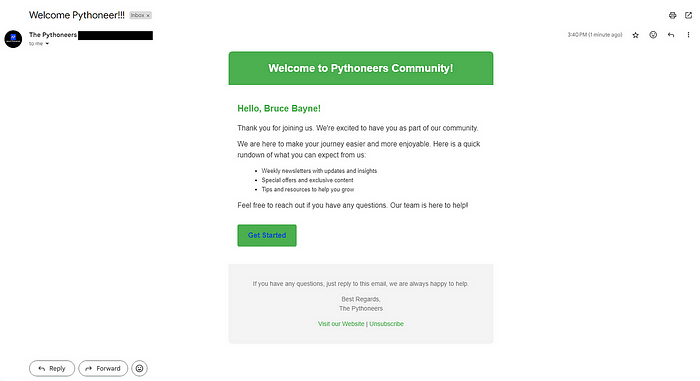
Убедитесь, что вы не рассылаете спам адресатам, иначе вас занесут в черный список Gmail. Постарайтесь ограничить количество писем до 100 в день.
12. FilterText (фильтрация текстовой информации)
Работа с контентом социальных сетей и получение значимых результатов может показаться непосильной задачей, особенно если приходится иметь дело с большим количеством текстовых данных. Именно здесь на помощь может прийти этот скрипт автоматизации, который сэкономит ваше время. Используя возможности обработки естественного языка (NLP), он фильтрует текст и автоматически извлекает ключевые элементы, такие как хэштеги, упоминания и ключевые слова, так что вам не придется просматривать все это вручную и писать тонны кода.
import re
import pandas as pd
import streamlit as st
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
# Определение regex-шаблонов для различных фильтров
patterns = {
'emails': r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b',
'mentions': r'@\w+',
'hashtags': r'#\w+',
'links': r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+',
'html_tags': r'<[^>]+>',
'phone_numbers': r'\+?\d{1,3}[-.\s]?\(?\d{1,4}?\)?[-.\s]?\d{1,4}[-.\s]?\d{1,9}',
'dates': r'\b\d{1,2}[/-]\d{1,2}[/-]\d{2,4}\b|\b\d{4}[/-]\d{1,2}[/-]\d{1,2}\b',
'currency': r'\$\d+(?:\.\d{2})?|€\d+(?:\.\d{2})?|£\d+(?:\.\d{2})?|USD\s\d+(?:\.\d+)?',
'emojis': r'[\U0001F600-\U0001F64F\U0001F300-\U0001F5FF\U0001F680-\U0001F6FF\U0001F700-\U0001F77F\U0001F900-\U0001F9FF]+',
}
def process_text(text, filters, mode):
if mode == 'extract':
return {filter_type: re.findall(patterns[filter_type], text) for filter_type in filters}
elif mode == 'clean':
cleaned_text = text
for filter_type in filters:
cleaned_text = re.sub(patterns[filter_type], '', cleaned_text)
return {'cleaned_text': cleaned_text}
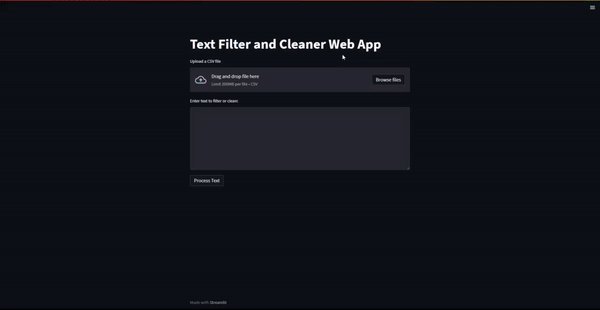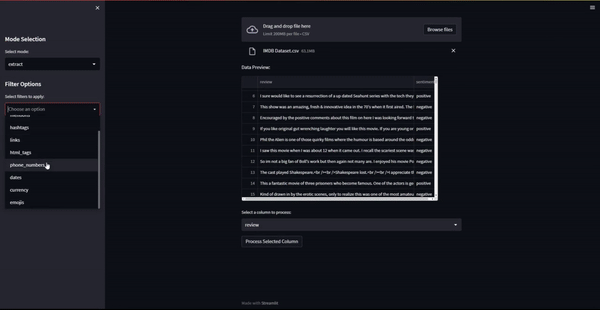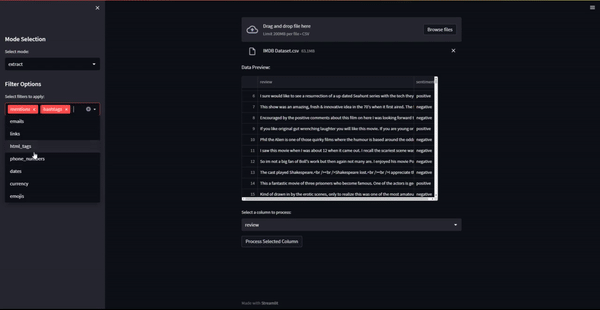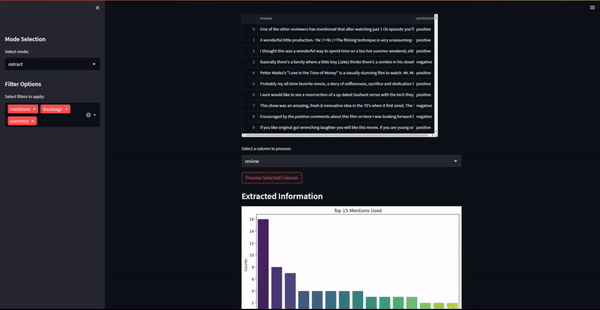
def plot_data(data, title):
# Подсчитайте количество вхождений каждого элемента и получите топ-15.
item_counts = Counter(data).most_common(15)
items, counts = zip(*item_counts)
# Создайте столбчатую диаграмму
plt.figure(figsize=(10, 5))
sns.barplot(x=list(items), y=list(counts), palette='viridis')
plt.title(title)
plt.xlabel('Items')
plt.ylabel('Counts')
plt.xticks(rotation=45)
st.pyplot(plt)
# Название приложения
st.title("Text Filter and Cleaner Web App")
# Загрузка файлов в формате CSV
uploaded_file = st.file_uploader("Upload a CSV file", type='csv')
if uploaded_file is not None:
df = pd.read_csv(uploaded_file)
st.write("Data Preview:")
st.dataframe(df)
# Выпадающий список выбора столбцов
selected_column = st.selectbox("Select a column to process:", df.columns.tolist())
# Выпадающий список выбора режима
st.sidebar.header("Mode Selection")
mode = st.sidebar.selectbox("Select mode:", ['extract', 'clean'])
# Параметры фильтрации
st.sidebar.header("Filter Options")
selected_filters = st.sidebar.multiselect("Select filters to apply:", list(patterns.keys()))
# Кнопка для применения фильтров или очистки
if st.button("Process Selected Column"):
if selected_column and not df[selected_column].isnull().all():
text_input = df[selected_column].astype(str).str.cat(sep=' ')
processed_info = process_text(text_input, selected_filters, mode)
# Отображение результатов
if mode == 'extract':
st.subheader("Extracted Information")
# График для каждого извлеченного фильтра
for filter_type in selected_filters:
data = processed_info.get(filter_type, [])
if data:
plot_data(data, f'Top 15 {filter_type.capitalize()} Used')
st.dataframe(pd.DataFrame.from_dict(processed_info, orient='index').transpose())
elif mode == 'clean':
st.subheader("Cleaned Text")
st.write(processed_info['cleaned_text'])
else:
st.error("Please select a valid column with data.")
else:
# Область ввода текста для ручного ввода (если файл не загружен)
text_input = st.text_area("Enter text to filter or clean:", height=200)
# Кнопка для применения фильтров или очистки для ручного ввода
if st.button("Process Text"):
if text_input:
processed_info = process_text(text_input, selected_filters, mode)
# Отображение отфильтрованной или очищенной информации
st.subheader("Processed Information")
if mode == 'extract':
for filter_type in selected_filters:
data = processed_info.get(filter_type, [])
if data:
plot_data(data, f'Top 15 {filter_type.capitalize()} Used')
st.dataframe(pd.DataFrame.from_dict(processed_info, orient='index').transpose())
elif mode == 'clean':
st.write(processed_info['cleaned_text'])
else:
st.error("Please enter text to process.")
13. ExifClean (извлечение и удаление метаданных)
Exif (exchangeable image file format) — стандарт, определяющий форматы изображений, звуковых данных и дополнительных тегов, используемых цифровыми камерами, смартфонами, сканерами и другими устройствами, работающими с изображениями и аудиофайлами, полученными с помощью цифровых камер.
Данные Exif, встроенные в файл изображения, содержат важные метаданные, такие как модель и настройки камеры, дата и время, геолокация, ориентация изображения, информация о программном обеспечении и многое другое.
Если вы любите делиться своими впечатлениями с помощью изображений в социальных сетях, этот скрипт автоматизации вам просто необходим.
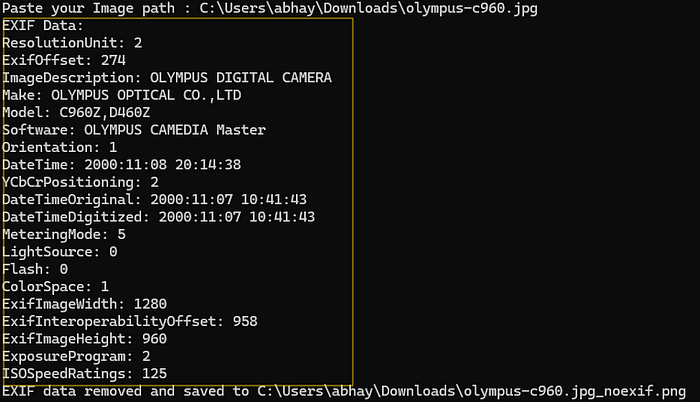
Он позволяет ввести путь к изображению, извлечь все метаданные Exif, а затем полностью удалить их. Это поможет обеспечить конфиденциальность ваших данных и при этом с легкостью делиться фотографиями.
from PIL import Image, JpegImagePlugin
from PIL.ExifTags import TAGS
def fetch_exif(image_path):
try:
image = Image.open(image_path)
exif_data = image._getexif()
if exif_data is not None:
# Преобразование данных EXIF в словарь для чтения
exif_dict = {TAGS[key]: exif_data[key] for key in exif_data.keys() if key in TAGS and isinstance(exif_data[key], (int, str))}
return exif_dict
else:
print("No EXIF data found in the image.")
return None
except Exception as e:
print(f"Error fetching EXIF data: {e}")
return None
def remove_exif(image_path, output_path):
try:
image = Image.open(image_path)
image.save(output_path, exif="")
print(f"EXIF data removed and saved to {output_path}")
except Exception as e:
print(f"Error removing EXIF data: {e}")
if __name__ == "__main__":
## Запрос использования пути к изображению
image_path = input('Paste your Image path : ')
# Получение и вывод данных EXIF
exif_data = fetch_exif(image_path)
if exif_data:
print("EXIF Data:")
for key, value in exif_data.items():
print(f"{key}: {value}")
# Удаление данных EXIF и сохранение их в том же месте
remove_exif(image_path, image_path+'_noexif.png')
14. BugBuster
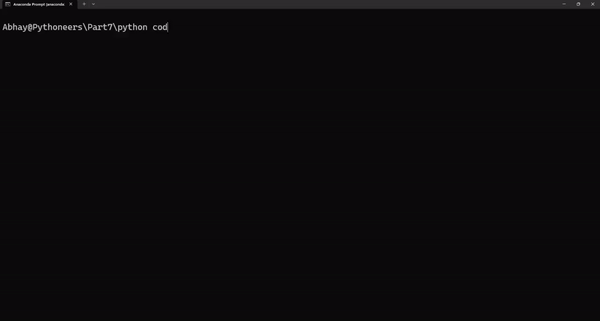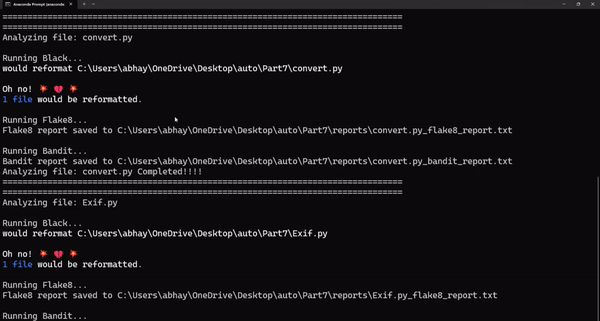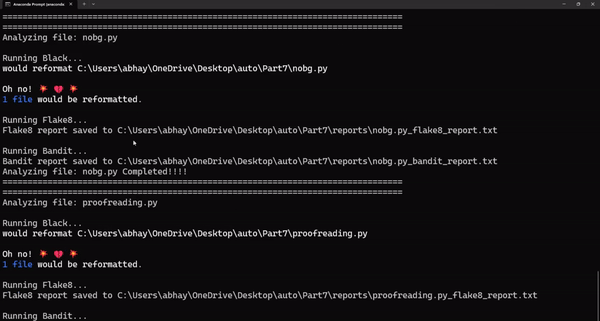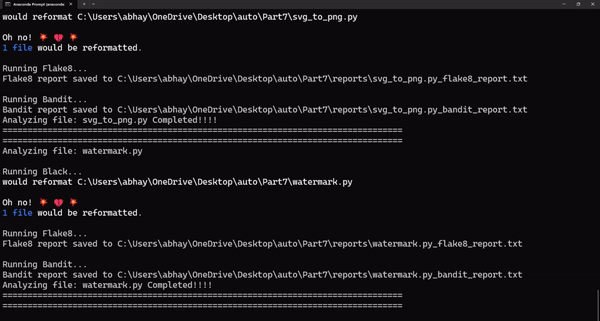
Написание чистого и эффективного кода — не просто хорошая практика. Качественный код необходим для создания масштабируемых и поддерживаемых проектов. Однако обеспечение качества кода может показаться нелегкой задачей, особенно при работе с большой кодовой базой или в условиях сжатых сроков. Процесс обнаружения уязвимостей, проблем с линтингом или логических несоответствий может быстро стать непреодолимой проблемой без соответствующих инструментов.
Этот скрипт автоматизации использует библиотеки Black, Flake8 и Bandit для сканирования каталогов кода на наличие логических ошибок и ошибок линтинга, сравнивая ваш код с четко определенными стандартами написания кода. Он не только сканирует код, но и генерирует журналы, к которым вы можете обратиться позже и усовершенствовать стандарты своей кодовой базы.
import os
import subprocess
def analyze_code(directory):
# Перечисление файлов Python в каталоге
python_files = [file for file in os.listdir(directory) if file.endswith('.py')]
if not python_files:
print("No Python files found in the specified directory.")
return
report_dir = os.path.join(directory, "reports")
os.makedirs(report_dir, exist_ok=True)
for file in python_files:
print(f"Analyzing file: {file}")
file_path = os.path.join(directory, file)
# Запуск Black (форматтер кода).
print("\nRunning Black...")
black_command = f"black {file_path} --check"
subprocess.run(black_command, shell=True)
# Запуск Flake8 (линтер)
print("\nRunning Flake8...")
flake8_output_file = os.path.join(report_dir, f"{file}_flake8_report.txt")
with open(flake8_output_file, "w") as flake8_output:
flake8_command = f"flake8 {file_path}"
subprocess.run(flake8_command, shell=True, stdout=flake8_output, stderr=subprocess.STDOUT)
print(f"Flake8 report saved to {flake8_output_file}")
# Запуск Bandit (анализ безопасности)
print("\nRunning Bandit...")
bandit_output_file = os.path.join(report_dir, f"{file}_bandit_report.txt")
with open(bandit_output_file, "w") as bandit_output:
bandit_command = f"bandit -r {file_path}"
subprocess.run(bandit_command, shell=True, stdout=bandit_output, stderr=subprocess.STDOUT)
print(f"Bandit report saved to {bandit_output_file}")
print(f"Analyzing file: {file} Completed!!!!")
print('================'*5)
print('================'*5
if __name__ == "__main__":
directory = r"C:\Users\abhay\OneDrive\Desktop\auto\Part7"
analyze_code(directory)
15. Port Scanner (сканирование портов)
Поговорим о кибербезопасности.
В компьютерных сетях порт — конечная точка связи, которая позволяет различным процессам или службам соединяться и обмениваться данными по сети. Порты обозначаются цифровыми значениями и связаны с определенными протоколами.
Открытые порты подобны окнам или дверям в здании — каждый из них является потенциальной точкой входа для связи между сайтом и внешними сетями. Однако если оставить порты открытыми без надлежащих мер безопасности, сайт может стать уязвимым для кибератак.
Этот скрипт автоматизации принимает на вход URL-адрес сайта и проверяет его на наличие открытых портов. Он станет полезным для вас инструментом независимо от того, работаете ли вы в «красной» команде (организующей кибератаки на ИТ-инфраструктуру компании, чтобы выявить ее слабые места) или держите оборону в «синей» (отвечающей за защиту информационных систем организации и реагирование на инциденты).
import socket
from prettytable import PrettyTable
# Словарь, сопоставляющий распространенные порты с уязвимостями (топ-15)
vulnerabilities = {
80: "HTTP (Hypertext Transfer Protocol) - Used for unencrypted web traffic",
443: "HTTPS (HTTP Secure) - Used for encrypted web traffic",
22: "SSH (Secure Shell) - Used for secure remote access",
21: "FTP (File Transfer Protocol) - Used for file transfers",
25: "SMTP (Simple Mail Transfer Protocol) - Used for email transmission",
23: "Telnet - Used for remote terminal access",
53: "DNS (Domain Name System) - Used for domain name resolution",
110: "POP3 (Post Office Protocol version 3) - Used for email retrieval",
143: "IMAP (Internet Message Access Protocol) - Used for email retrieval",
3306: "MySQL - Used for MySQL database access",
3389: "RDP (Remote Desktop Protocol) - Used for remote desktop connections (Windows)",
8080: "HTTP Alternate - Commonly used as a secondary HTTP port",
8000: "HTTP Alternate - Commonly used as a secondary HTTP port",
8443: "HTTPS Alternate - Commonly used as a secondary HTTPS port",
5900: "VNC (Virtual Network Computing) - Used for remote desktop access",
# По мере необходимости добавляйте новые порты и уязвимости
}
def display_table(open_ports):
table = PrettyTable(["Open Port", "Vulnerability"])
for port in open_ports:
vulnerability = vulnerabilities.get(port, "No known vulnerabilities associated with common services")
table.add_row([port, vulnerability])
print(table)
def scan_top_ports(target):
open_ports = []
top_ports = [21, 22, 23, 25, 53, 80, 110, 143, 443, 3306, 3389, 5900, 8000, 8080, 8443] # Топ-15 портов
for port in top_ports:
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(1) # Настройте тайм-аут в зависимости от потребностей
result = sock.connect_ex((target, port))
if result == 0:
open_ports.append(port)
sock.close()
except KeyboardInterrupt:
sys.exit()
except socket.error:
pass
return open_ports
def main():
target = input("Enter the website URL or IP address to scan for open ports: ")
open_ports = scan_top_ports(target)
if not open_ports:
print("No open ports found on the target.")
else:
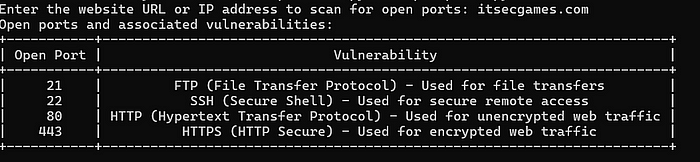
print("Open ports and associated vulnerabilities:")
display_table(open_ports)
if __name__ == "__main__":
main()
Проверим itsecgames.com — чрезвычайно глючное веб-приложение!
16. Readme Generator (генератор файлов Readme)
Файл README.md производит первое впечатление о вашем проекте: он содержит ключевые детали и побуждает других людей глубже вникнуть в то, что вы создали. Хотя это один из самых важных файлов в вашем репозитории, его создание часто может отнимать много времени.
Нижеприведенный скрипт автоматизации меняет ситуацию, быстро генерируя файлы README.md на основе простых входных данных, таких как имена репозиториев, ссылки и описания проектов. Сэкономьте драгоценное время и сосредоточьтесь на главном — создании проекта.
def generate_markdown_file():
# Подсказка пользователю о необходимости ввода данных
repository_name = input("\n Enter the name of your GitHub repository: ")
project_description = input("Enter a short description of your project: ")
installation_instructions = input("Enter installation instructions for your project: ")
usage_instructions = input("Enter usage instructions for your project: ")
contributors = input("Enter the contributors to your project (separated by commas): ")
license = select_license()
# Создание значков
stars_badge = "[](https://github.com/{}/stargazers)".format(repository_name, repository_name)
forks_badge = "[](https://github.com/{}/network/members)".format(repository_name, repository_name)
issues_badge = "[](https://github.com/{}/issues)".format(repository_name, repository_name)
license_badge = "[](https://github.com/{}/blob/master/LICENSE)".format(repository_name, repository_name)
# Создание содержимого в формате Markdown
markdown_content = f"""
# {repository_name}
{project_description}
## Содержание
- [Installation](#installation)
- [Usage](#usage)
- [Contributors](#contributors)
- [License](#license)
- [Badges](#badges)
- [GitHub Repository](#github-repository)
## Установка
```
{installation_instructions}
```
## Использование
```
{usage_instructions}
```
## Авторы
{contributors}
## Лицензия
This project is licensed under the {license} License - see the [LICENSE](LICENSE) file for details.
## Значки
{stars_badge} {forks_badge} {issues_badge} {license_badge}
## GitHub-репозиторий
[Link to GitHub repository](https://github.com/{repository_name})
"""
# Запись контента в файл Markdown
markdown_file_name = f"{repository_name}_README.md"
with open(markdown_file_name, "w") as markdown_file:
markdown_file.write(markdown_content)
print(f"Markdown file '{markdown_file_name}' generated successfully!")
def select_license():
licenses = {
"MIT": "MIT License",
"Apache": "Apache License 2.0",
"GPL": "GNU General Public License v3.0",
# Можно добавлять дополнительные лицензии по мере необходимости
}
print("Select a license for your project:")
for key, value in licenses.items():
print(f"{key}: {value}")
while True:
selected_license = input("Enter the number corresponding to your selected license: ")
if selected_license in licenses:
return licenses[selected_license]
else:
print("Invalid input. Please enter a valid license number.")
if __name__ == "__main__":
generate_markdown_file()

17. SmartTrading (уведомление о колебаниях цен на фондовом рынке)
Цена акции указывает на ее текущую стоимость для покупателей и продавцов. Трейдеры по всему миру проводят большую часть своего времени, глядя на различные графики линий, баров, точек, фигур и свечей, чтобы анализировать и принимать решения о покупке или продаже тех или иных акций. Однако у людей, занятых 9 утра до 5 вечера или с 12 дня до 12 ночи (на удаленной работе), обычно нет времени, чтобы постоянно смотреть на эти дэшборды.
Покупка премиального членства во многих торговых компаниях — способ получать уведомления, когда цены на акции опускаются ниже порогового уровня, но это будет стоить много денег. Есть гораздо более простой, легкий и дешевый способ (стоимостью 0$), который я покажу вам, используя Python. Этот скрипт автоматизации поможет отслеживать цены на акции и получать уведомления, как только цена упадет до определенного порогового процента.
import time
import yfinance as yf
from win10toast import ToastNotifier
# Определение символа акции и процентного порога
stock_symbol = "AAPL"
threshold_percentage = 0.010 # Установка желаемого процентного порога
toaster = ToastNotifier()
initial_data = yf.download(stock_symbol, period="1d")
initial_price = initial_data["Close"].iloc[0]
while True:
try:
# Получение текущей цены акции
current_data = yf.download(stock_symbol, period="1d")
current_price = current_data["Close"].iloc[-1]
# Рассчитайте разницу цен в процентах
price_diff_percentage = ((current_price - initial_price) / initial_price) * 100
# Сравнение разницы цен с процентным порогом
if price_diff_percentage <= -threshold_percentage:
message = f"Stock price for {stock_symbol} has decreased by {price_diff_percentage:.2f}%; Current Price is: {current_price}"
toaster.show_toast("Stock Alert", message, duration=10)
# Подождите 5 минут, прежде чем снова проверить цену
time.sleep(300)
except Exception as e:
print("An error occurred:", str(e))
break
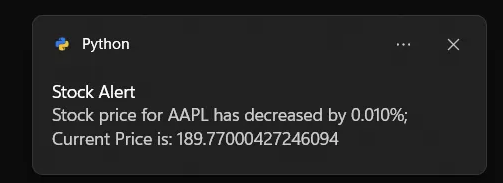
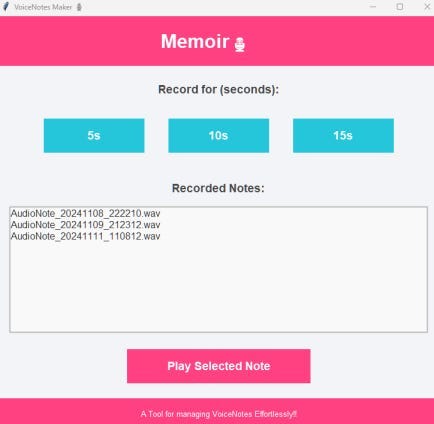
18. VoiceNotes (создание голосовых заметок)
В нашем быстро меняющемся мире очень важно записывать мысли или напоминания по ходу дела. Голосовые заметки — отличный способ быстро записать мысли, список дел или творческие идеи без использования рук. Однако управление ими может стать непростой задачей, связанной с беспорядочным хранением и пропуском файлов.
Этот скрипт автоматизации упрощает процесс, автоматически создавая, упорядочивая и сохраняя ваши заметки, так что вам больше никогда не придется беспокоиться об их потере или поиске.
import tkinter as tk
from tkinter import messagebox
import pyaudio
import wave
import os
from datetime import datetime
from playsound import playsound
# Убедитесь в существовании каталога для записей
os.makedirs("assets/recordings", exist_ok=True)
# Инициализация главного окна
root = tk.Tk()
root.title("VoiceNotes Maker 🎙️")
root.geometry("550x500")
root.config(bg="#F1F5F9") # Background color
# Инициализация списка заметок
notes = []
def record_audio(duration):
fs = 48000 # Частота выборки
channels = 2 # Стерео
chunk = 1024 # Размер каждого звукового фрагмента
# Имя файла для сохранения голосовых заметок
filename = f"assets/recordings/AudioNote_{datetime.now().strftime('%Y%m%d_%H%M%S')}.wav"
p = pyaudio.PyAudio()
# Откройте поток для записи звука
stream = p.open(format=pyaudio.paInt16, # Формат аудио (16 бит)
channels=channels,
rate=fs,
input=True,
frames_per_buffer=chunk)
frames = []
# Запись аудио фрагментами
for _ in range(0, int(fs / chunk * duration)):
data = stream.read(chunk)
frames.append(data)
# Остановка записи
stream.stop_stream()
stream.close()
p.terminate()
# Сохранение звука в файл .wav
with wave.open(filename, 'wb') as wf:
wf.setnchannels(channels)
wf.setsampwidth(p.get_sample_size(pyaudio.paInt16))
wf.setframerate(fs)
wf.writeframes(b''.join(frames))
# Добавление записи в список
notes.append(filename)
note_list.insert(tk.END, os.path.basename(filename))
def play_audio():
selected_index = note_list.curselection()
if selected_index:
filename = notes[selected_index[0]]
# Используйте функцию playsound для воспроизведения выбранного аудиофайла
playsound(filename)
else:
messagebox.showwarning("No Selection", "Please select a note to play.")
# Загрузите имеющиеся заметки
for file in os.listdir("assets/recordings"):
if file.endswith(".wav"):
notes.append(f"assets/recordings/{file}")
# Настройка основных элементов пользовательского интерфейса
header_frame = tk.Frame(root, bg="#4C6EF5", pady=20)
header_frame.pack(fill="x")
header_label = tk.Label(header_frame, text="Memoir🎙️", bg="#4C6EF5", fg="white", font=("Arial", 20, "bold"))
header_label.pack()
tk.Label(root, text="Record for (seconds):", bg="#F1F5F9", font=("Arial", 12)).pack(pady=(10, 5))
button_frame = tk.Frame(root, bg="#F1F5F9")
button_frame.pack()
# Кнопки продолжительности записи с оптимизированными цветами
record_buttons = [("5s", 5),("10s", 10),("15s", 15)]
for text, duration in record_buttons:
button = tk.Button(button_frame, text=text, command=lambda d=duration: record_audio(d), bg="#5CBBF6", fg="white", font=("Arial", 12, "bold"), width=8, relief="flat")
button.grid(row=0, column=record_buttons.index((text, duration)), padx=15, pady=10)
tk.Label(root, text="Recorded Notes:", bg="#F1F5F9", font=("Arial", 12)).pack(pady=(15, 5))
note_list = tk.Listbox(root, height=8, font=("Arial", 12), bg="#FFFFFF", fg="#333333", selectmode=tk.SINGLE, bd=2, relief="groove")
note_list.pack(padx=20, pady=10, fill=tk.BOTH)
# Заполните поле списка заметок
for note in notes:
note_list.insert(tk.END, os.path.basename(note))
# Кнопка воспроизведения с элегантным дизайном
play_button = tk.Button(root, text="Play Selected Note", command=play_audio, bg="#FF6F61", fg="white", font=("Arial", 12, "bold"), width=20, relief="flat")
play_button.pack(pady=(15, 5))
# Нижняя часть с описанием приложения
footer_frame = tk.Frame(root, bg="#4C6EF5", pady=10)
footer_frame.pack(fill="x", side="bottom")
footer_label = tk.Label(footer_frame, text="A Tool for managing VoiceNotes Effortlessly!!", bg="#4C6EF5", fg="white", font=("Arial", 10))
footer_label.pack()
root.mainloop()
Бонусный скрипт: MultiTask Reminder App (планировщик задач)
Это приложение для напоминания о дедлайне при многозадачном режиме — мой личный фаворит. Выполнение задач и соблюдение сроков может оказаться непосильной задачей, особенно когда какие-то дела ускользают от внимания. Представьте, что у вас есть личный помощник, который напомнит вам обо всем в нужное время. Этот скрипт автоматизации на Python отправляет своевременные напоминания обо всех запланированных задачах — от рабочих сроков до личных дел.
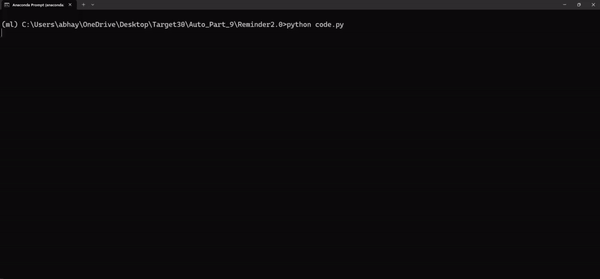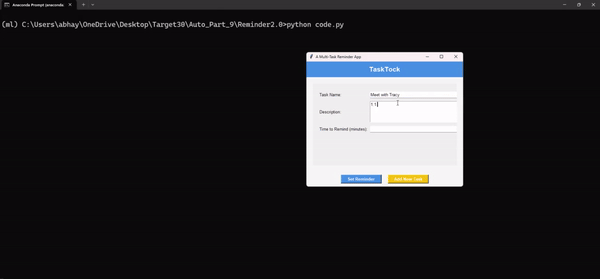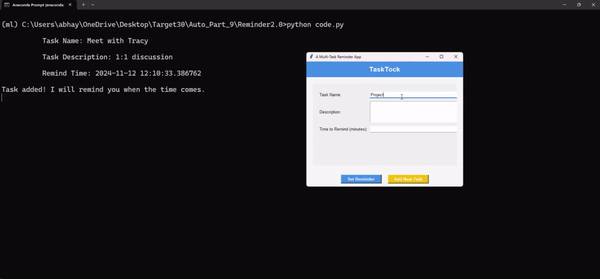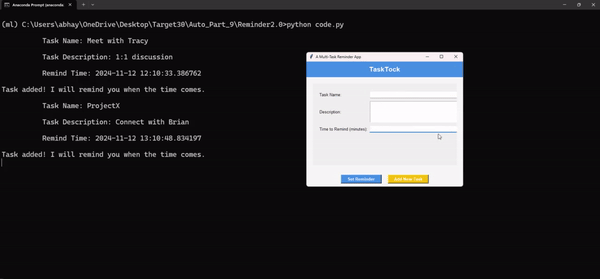
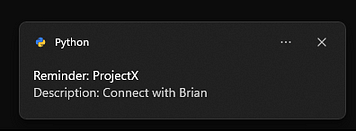
Полный код этого скрипта автоматизации можете посмотреть здесь.
Читайте также:
- Опыт работы с Python в течение 2 лет: уроки и рекомендации
- Я бросил изучать Python и стал лучшим разработчиком
- Правила PRISM на языке Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи Abhay Parashar: 18 Insanely Useful Python Automation Scripts I Use Everyday






{kind=link}