
Сила Python в его гибкости. Это один из самых простых языков для объектно-ориентированного программирования. Иногда его даже критикуют за чрезмерную гибкость. Я покажу самый элегантный на мой взгляд способ объектно-ориентированного программирования в Python. Ключ к элегантности — библиотека marshmallow. Она устанавливается командой pip install marshmallow.

Определение класса
Для демонстрации давайте начнём с объявления простого класса User:
class User(object):
def __init__(self, name, age):
self.name = name
self.age = age
def __repr__(self):
return f'I am {self.name} and my age is {self.age}'OK. У User только два атрибута: name и age. Обратите внимание, что я также реализовал метод __repr__, чтобы мы легко могли вывести экземпляр для проверки. Затем импортируем некоторые модули и методы из библиотеки marshmallow:
from marshmallow import Schema, fields, post_load
from pprint import pprint
Я импортировал pprint, потому что собираюсь отобразить множество словарей и списков. Так они будут выглядеть лучше. Так как же использовать marshmallow? Предельно просто: определите Schema для класса User:
class UserSchema(Schema):
name = fields.String()
age = fields.Integer()
@post_load
def make(self, data, **kwargs):
return User(**data)
Для каждого атрибута необходимо объявить поля — fields, а затем тип. Аннотация @post_load опциональная. Она нужна для загрузки схемы в качестве экземпляра какого-либо класса. Следовательно, в нашем случае она нужна для генерации экземпляров User. Метод make реализует экземпляр с помощью атрибутов.
JSON в экземпляр
Если у нас есть словарь (объект JSON) и нам нужен экземпляр, пишем такой код:
data = {
'name': 'Chris',
'age': 32
}
schema = UserSchema()
user = schema.load(data)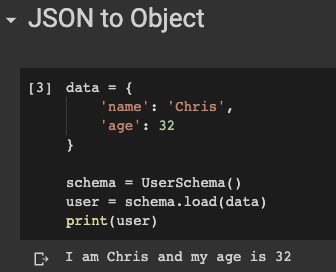
Всё просто! Вызываем метод схемы load() и десериализуем объект JSON в экземпляр класса.
Массив JSON в несколько экземпляров
Что, если мы работаем с массивом JSON, содержащим множество объектов для десериализации? Не нужно писать for, просто укажите many=True:
data = [{
'name': 'Alice',
'age': 20
}, {
'name': 'Bob',
'age': 25
}, {
'name': 'Chris',
'age': 32
}]schema = UserSchema()
users = schema.load(data, many=True)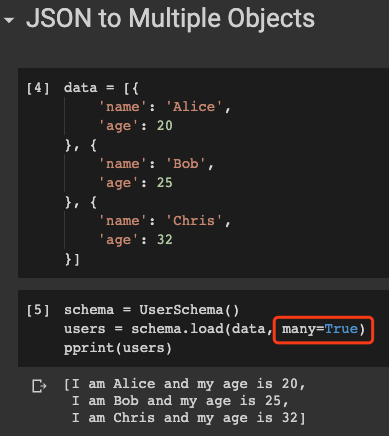
Сериализованный экземпляр в объект-словарь JSON
OK. Теперь мы знаем, что можем вызвать метод load() для преобразования словарей в экземпляры. Как насчёт обратного действия? Используем метод dump():
dict = schema.dump(users, many=True)
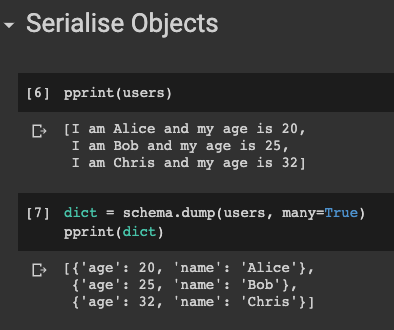
Здесь users — список экземпляров из предыдущего примера. Мы видим, как список пользователей преобразуется в массив JSON одной строкой кода!
Валидация поля
Думаете, marshmallow умеет только сериализовывать и десериализовывать экземпляры? Если бы это было так, я бы вряд ли взялся за эту статью. Самая мощная функция этой библиотеки — валидация. Начнём с простого примера. Сначала импортируем ValidationError, исключение из marshmallow:
from marshmallow import ValidationError
Помните, мы объявили UserSchema выше с полем age как Integer? Что, если мы передадим недопустимое значение?
data = [{
'name': 'Alice',
'age': 20
}, {
'name': 'Bob',
'age': 25
}, {
'name': 'Chris',
'age': 'thirty two'
}]Пожалуйста, обратите внимание, что третий объект — Chris — в массиве JSON имеет недопустимый формат, из-за которого его нельзя преобразовать в целое число. Теперь вызовем метод load(), чтобы десериализовать массив.
try:
schema = UserSchema()
users = schema.load(data, many=True)
except ValidationError as e:
print(f'Error Msg: {e.messages}')
print(f'Valid Data: {e.valid_data}')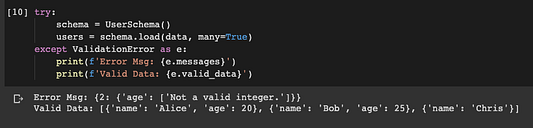
Исключение поймано, оно сообщает о недопустимом целом числе. Представьте, что разрабатываете веб-приложение. Теперь вам не нужно писать сообщения об ошибках!
Кроме того, в этом примере только у третьего объекта возникла проблема валидации. Сообщение говорит нам о том, что ошибка произошла в индексе 2, и допустимые объекты всё ещё могут быть выведены.
Продвинутая валидация
Конечно, проверки только по типам данных недостаточно. Библиотека поддерживает куда больше методов валидации. Добавим в класс User атрибут gender.
class User(object):
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def __repr__(self):
return f'I am {self.name}, my age is {self.age} and my gender is {self.gender}'Затем определим схему с валидациями. И, конечно, импортируем из библиотеки функцию validate.
from marshmallow import validate
class UserSchema(Schema):
name = fields.String(validate=validate.Length(min=1))
age = fields.Integer(validate=validate.Range(min=18, max=None))
gender = fields.String(validate=validate.OneOf(['F', 'M', 'Other']))
Мы добавили валидации ко всем трём полям.
- У
nameдлина должна быть хотя бы в 1 символ. Иными словами, поле не может быть пустым. - У
ageзначение должно быть больше или равно 18. - Поле
genderдолжно принимать одно из трёх значений.
Давайте определим объект JSON с недопустимыми значениями всех полей:
data = {
'name': '',
'age': 16,
'gender': 'X'
}И попробуем загрузить его:
try:
UserSchema().load(data)
except ValidationError as e:
pprint(e.messages)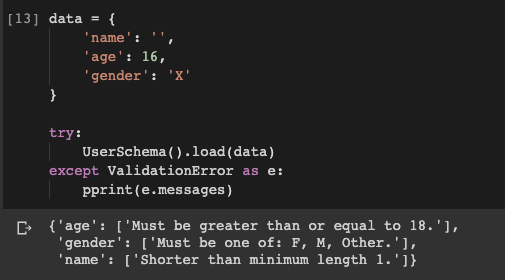
Неудивительно, что обнаружены исключения, но, когда я увидел этот вывод впервые, меня поразило, что сообщения об ошибках встроены по умолчанию. Я сэкономил кучу времени!
Пользовательские функции валидации
Вы можете спросить, ограничены ли мы встроенными методами валидации, такими как диапазон, длина или выбор одного из значений, как в примере выше. Что, если мы захотим написать собственный метод валидации? Конечно, это возможно:
def validate_age(age):
if age < 18:
raise ValidationError('You must be an adult to buy our products!')
class UserSchema(Schema):
name = fields.String(validate=validate.Length(min=1))
age = fields.Integer(validate=validate_age)
gender = fields.String(validate=validate.OneOf(['F', 'M', 'Other']))Здесь мы определили метод validate_age с пользовательскими логикой и сообщением. Теперь определим объект JSON, чтобы протестировать этот метод. В следующем примере age меньше 18.
data = {
'name': 'Chris',
'age': 17,
'gender': 'M'
}
try:
user = UserSchema().load(data)
except ValidationError as e:
pprint(e.messages)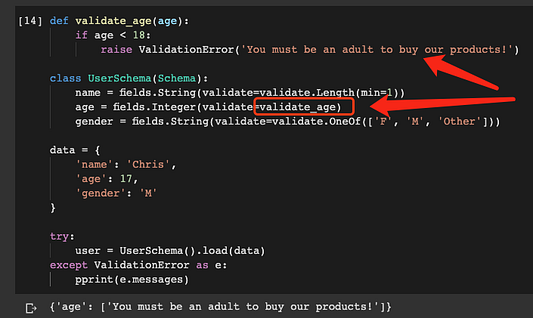
Теперь validate_age применяет пользовательские логику и сообщение об ошибке. Ниже элегантная реализация:
class UserSchema(Schema):
name = fields.String()
age = fields.Integer()
gender = fields.String()
@validates('age')
def validate_age(self, age):
if age < 18:
raise ValidationError('You must be an adult to buy our products!')Через аннотацию мы определяем валидацию внутри класса.
Поля, требующие заполнения
Конечно, можно определить поля, требующие заполнения:
class UserSchema(Schema):
name = fields.String(required=True, error_messages={'required': 'Please enter your name.'})
age = fields.Integer(required=True, error_messages={'required': 'Age is required.'})
email = fields.Email()В этом примере обязательны поля name и age. Теперь давайте проверим валидацию объектом без электронной почты:
data_no_email = {
'name': 'Chris',
'age': 32
}
try:
user = UserSchema().load(data_no_email)
except ValidationError as e:
pprint(e.messages)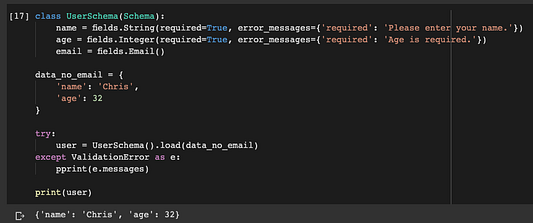
OK. Проблем не возникло. Что, если в объекте не указаны ни имя, ни возраст?
data_no_name_age = {
'email': 'abc@email.com'
}
try:
user = UserSchema().load(data_no_name_age)
except ValidationError as e:
print(f'Error Msg: {e.messages}')
print(f'Valid Data: {e.valid_data}')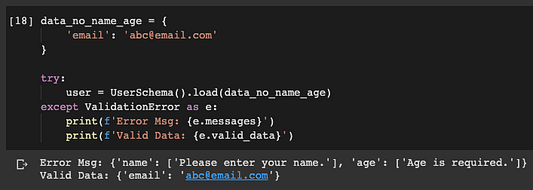
Появилось предупреждение и сообщения об ошибках, заданные для обязательных полей.
Значения по умолчанию
Иногда нужно задать значения по умолчанию для некоторых полей. Пользователям не обязательно вводить данные, вместо них будут использованы значения по умолчанию.
class UserSchema(Schema):
name = fields.String(missing='Unknown', default='Unknown')
print(UserSchema().load({})) # Принять значение "missing"
print(UserSchema().dump({})) # Принять значение "default"
В marshmallow существует два способа определить значения по умолчанию:
- Ключевое слово
missingопределяет значение по умолчанию, которое используется при десериализации экземпляра с помощьюload(). - Ключевое слово
defaultопределяет значение по умолчанию, которое используется при сериализации экземпляра с помощьюdump().
В примере выше мы применили оба ключевых слова и поэкспериментировали над пустым объектом и с методом load(), и с методом dump(). В обоих случаях было добавлено поле name со значением по умолчанию.
Псевдоним атрибута
Это ещё не конец, продолжаем 🙂
Иногда возникает расхождение в реализации классов и фактических данных в JSON, то есть расхождение имён ключей или атрибутов. Например, в User мы определили атрибут name, однако в объекте JSON используется другое имя для этого поля — username. В нашем случае не нужно ни повторно реализовывать классы, ни преобразовывать ключи в объекте JSON. Можно написать такой код:
class User(object):
def __init__(self, name, age):
self.name = name
self.age = age
def __repr__(self):
return f'I am {self.name} and my age is {self.age}'
class UserSchema(Schema):
username = fields.String(attribute='name')
age = fields.Integer()
@post_load
def make(self, data, **kwargs):
return User(**data)Обратите внимание, что в User есть поле name, тогда как в UserSchema есть поле username. Но для username определено, что его attribute должен называться name. Выведем экземпляр класса User:
user = User('Chris', 32)
UserSchema().dump(user)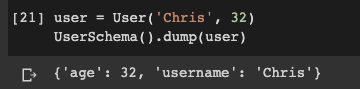
dump корректно сериализовал экземпляр с именем поля username. И наоборот:
data = {
'username': 'Chris',
'age': 32
}
UserSchema().load(data)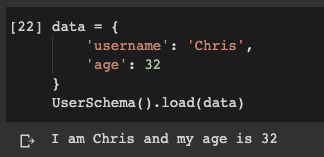
Даже если мы передадим JSON объект с ключом username, он без проблем десериализуется в экземпляр User.
Вложенные атрибуты
И последнее, но не менее важное, чем всё остальное: marshmallow поддерживает вложенные атрибуты.
class Address(object):
def __init__(self, street, suburb, postcode):
self.street = street
self.suburb = suburb
self.postcode = postcodedef __repr__(self):
return f'{self.street}, {self.suburb} {self.postcode}'class User(object):
def __init__(self, name, address):
self.name = name
self.address = address
def __repr__(self):
return f'My name is {self.name} and I live at {self.address}'Мы определили два класса: Address и User. У User есть атрибут address, имеющий тип Address. Давайте проверим классы, реализовав объект:
address = Address('1, This St', 'That Suburb', '1234')
user = User('Chris', address)
print(user)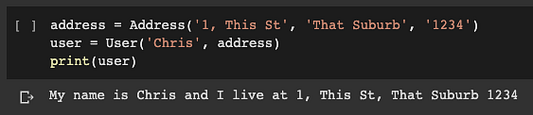
И определим схему:
class AddressSchema(Schema):
street = fields.String()
suburb = fields.String()
postcode = fields.String()
@post_load
def make(self, data, **kwargs):
return Address(**data)
class UserSchema(Schema):
name = fields.String()
address = fields.Nested(AddressSchema())
@post_load
def make(self, data, **kwargs):
return User(**data)Хитрость здесь в том, чтобы использовать fields.Nested() для определения поля по другой схеме. У нас уже есть экземпляр User. Давайте сделаем его дамп в JSON:
pprint(UserSchema().dump(user))
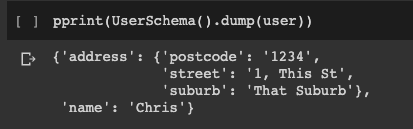
Как видите, экземпляр сериализован во вложенный объект JSON Конечно, обратный вариант тоже работает:
data = {
'name': 'Chris',
'address': {
'postcode': '1234',
'street': '1, This St',
'suburb': 'That Suburb'
}
}
pprint(UserSchema().load(data))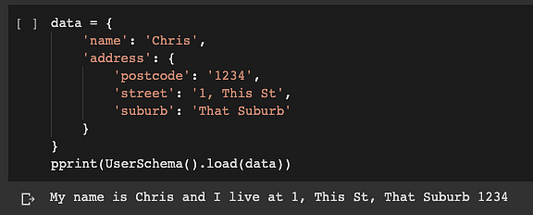
Заключение
На сегодня всё. Спасибо, что прочитали! Код из статьи вы найдёте на Google Colab.

Читайте также:
- Python: декоратор @retry
- Когда и зачем использовать оператор := в Python
- 5 ключевых понятий Python и их магические методы
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Christopher Tao: The Most Elegant Python Object-Oriented Programming





