
Я использую Python уже почти 5 лет. Автоматизация задач — одно из свойств этого языка, которое не перестает привлекать меня и стимулировать мои исследования. Углубленно изучив возможности автоматизации на Python в течение последнего года, я открыл для себя потрясающие пакеты, факты и скрипты. В этой статье поделюсь скриптами автоматизации, которые использую ежедневно и которые значительно повысили мою продуктивность и производительность.
1. Speakify (перевод PDF-файлов в аудиоформат)
Я книголюб и предпочитаю слушать аудиокниги. Этот скрипт автоматизации стал для меня спасением: использую его обычно для прослушивания PDF-файлов и преобразования их в аудиокниги, чтобы прослушать позже.
import PyPDF2
import pyttsx3
# Откройте PDF-файл (введите путь к вашему PDF-файлу).
file = open('story.pdf', 'rb')
readpdf = PyPDF2.PdfReader(file)
# Инициализация механизма преобразования текста в речь
speaker = pyttsx3.init()
rate = speaker.getProperty('rate') # Получение текущей скорости речи диктора
speaker.setProperty('rate', 200)
volume = speaker.getProperty('volume')
speaker.setProperty('volume', 1) # Установка уровня громкости (от 0,0 до 1,0)
# Получение и настройка другого голоса
voices = speaker.getProperty('voices')
for voice in voices:
if "english" in voice.name.lower() and "us" in voice.name.lower():
speaker.setProperty('voice', voice.id)
break
# Итерация по каждой странице в PDF
for pagenumber in range(len(readpdf.pages)):
# Извлечение текста со страницы
page = readpdf.pages[pagenumber]
text = page.extract_text()
# Использование диктора для чтения текста
# speaker.say(text)
# speaker.runAndWait()
# Сохранение последнего извлеченного текста в аудиофайл (при необходимости).
speaker.save_to_file(text, 'story.mp3')
speaker.runAndWait()
# Остановка диктора
speaker.stop()
# Закрытие PDF-файла
file.close()
Применение скрипта в реальной жизни:
- Доступность чтения для слабовидящих: предоставление аудиоверсий письменных материалов помогает людям со слабым зрением легко получить доступ к информации.
- Обучение на ходу: позволяет пользователям прослушивать статьи или учебники во время поездок на работу или занятий спортом.
- Изучение языков: изучающим иностранные языки скрипт открывает возможность совершенствовать навыки восприятия речи на слух путем предоставления аудиоверсий текстов.
- Образование: обеспечивает более гибкие варианты обучения путем предоставления студентам аудиоверсий материалов для чтения.
2. TabTornado (открытие закладок одним кликом)
До написания этого скрипта я сохранял в закладки интересные тексты, чтобы прочитать их на следующий день. Однако через несколько недель я понял, что моя панель закладок разрастается все больше, и с каждым днем мне все труднее находить новые закладки. Поэтому я нашел питонический способ решения этой проблемы. С помощью скрипта автоматизации TabTornado можно просто скопировать и вставить все ссылки, а затем открыть их одним щелчком мыши.
import webbrowser
with open('links.txt') as file:
links = file.readlines()
for link in links:
webbrowser.open('link')Применение скрипта:
- Повышение эффективности работы: специалисты, которым приходится исследовать несколько сайтов, могут упростить свою работу, сосредоточившись на ее содержании, а не на процессе открытия ссылок.
- Обучение и развитие: студенты, обучающиеся онлайн, могут сразу открывать все материалы курса, статьи и ресурсы, что делает их занятия более эффективными.
3. PicFetcher (быстрый сбор изображений)
Сбор большого количества данных об изображениях — одна из ключевых задач в проектах по компьютерному зрению. Как отмечает исследователь искусственного интеллекта Эндрю Ын (Andrew Ng), наличие большого набора данных может быть важнее, чем использование конкретного алгоритма. Качественные данные необходимы для повышения производительности и точности моделей машинного обучения. Этот скрипт автоматизации упрощает процесс, позволяя загрузить из интернета заданное количество изображений за считанные минуты с минимальными усилиями по написанию кода.
# Импорт необходимого модуля и функции
from simple_image_download import simple_image_download as simp
# Создание объекта ответа
response = simp.simple_image_download
## Ключевое слово
keyword = "Dog"
# Загрузка изображений
try:
response().download(keyword, 20)
print("Images downloaded successfully.")
except Exception as e:
print("An error occurred:", e)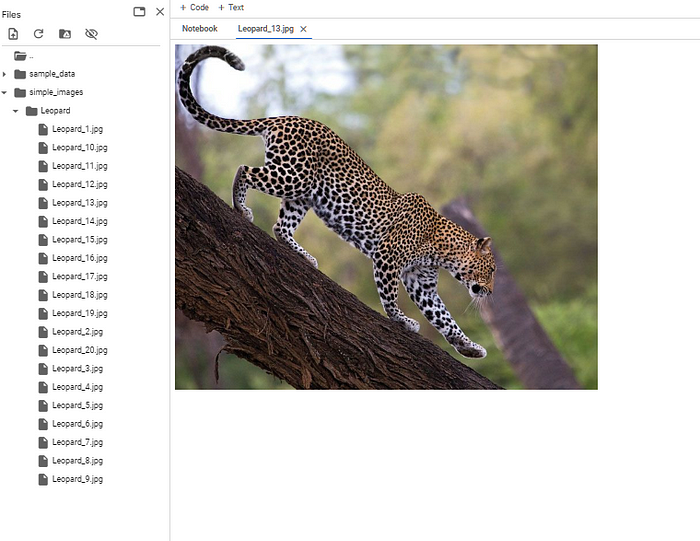
Области применения:
- Создание наборов данных для проектов по компьютерному зрению.
- Подготовка контента для баннерных изображений.
- Сбор материалов для маркетинговых кампаний.
- Академические исследования.
4. PyInspector (анализ качества кода)
Каждый разработчик знает, как неприятно, выискивая недочеты в Python-коде, застревать в паутине ошибок. Написание чистого и эффективного кода очень важно, но ручной анализ качества кода может оказаться сложной задачей. Этот скрипт автоматизации использует пакеты Pylint и Flake8 для тщательного анализа кода, сравнения его со стандартами написания кода и выявления логических ошибок. Он следит за тем, чтобы ваш код соответствовал лучшим отраслевым практикам и не содержал ошибок.
import os
import subprocess
def analyze_code(directory):
# Перечисление файлов Python в каталоге
python_files = [file for file in os.listdir(directory) if file.endswith('.py')]
if not python_files:
print("No Python files found in the specified directory.")
return
# Анализ каждого файла Python с помощью pylint и flake8
for file in python_files:
print(f"Analyzing file: {file}")
file_path = os.path.join(directory, file)
# Запуск pylint
print("\nRunning pylint...")
pylint_command = f"pylint {file_path}"
subprocess.run(pylint_command, shell=True)
# Запуск flake8
print("\nRunning flake8...")
flake8_command = f"flake8 {file_path}"
subprocess.run(flake8_command, shell=True)
if __name__ == "__main__":
directory = r"C:\Users\abhay\OneDrive\Desktop\Part7"
analyze_code(directory)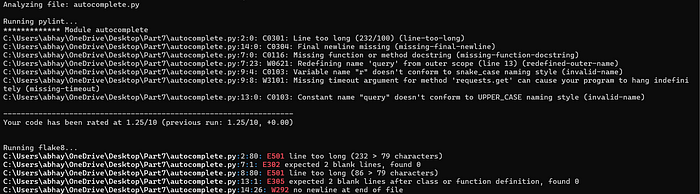
5. DataDummy (генерация искусственных данных)
Если вам нужен образец данных для тестирования моделей или необходимо просто заполнить ненужную форму случайной информацией, этот скрипт автоматизации на Python окажется невероятно полезным. Он генерирует реалистично выглядящие, но полностью искусственные наборы данных, идеально подходящие для тестирования, разработки и моделирования. Этот инструмент может быстро создавать имена, электронные письма, номера телефонов и многое другое, обеспечивая универсальное решение для различных потребностей в генерации данных.
import pandas as pd
from faker import Faker
import random
fake = Faker()
def generate_fake_data(num_entries=10):
data = []
for _ in range(num_entries):
entry = {
"Name": fake.name(),
"Address": fake.address(),
"Email": fake.email(),
"Phone Number": fake.phone_number(),
"Date of Birth": fake.date_of_birth(minimum_age=18, maximum_age=65).strftime("%Y-%m-%d"),
"Random Number": random.randint(1, 100),
"Job Title": fake.job(),
"Company": fake.company(),
"Lorem Ipsum Text": fake.text(),
}
data.append(entry)
return pd.DataFrame(data)
if __name__ == "__main__":
num_entries = 10 # You can adjust the number of entries you want to generate
fake_data_df = generate_fake_data(num_entries)
## Датафрейм с фиктивными данными
fake_data_df6. BgBuster (удаление фона с изображений с гарантией их конфиденциальности)
Этот скрипт автоматизации стал неотъемлемой частью моего ежедневного набора инструментов. Как автор статей, я часто работаю с изображениями, многие из которых нужны мне без фона. Хотя для обрезания фона существует множество онлайн-инструментов, я беспокоюсь о конфиденциальности и безопасности моих изображений в интернете. Этот Python-скрипт использует пакет rembg для локального удаления фона с изображений, гарантируя приватность и защищенность моих фотографий.
from rembg import remove
from PIL import Image
## Путь для входного и выходного изображения
input_img = 'monkey.jpg'
output_img = 'monkey_rmbg.png'
## Загрузка и удаление фона
inp = Image.open(input_img)
output = remove(inp)
## Сохранение удаленного фонового изображения в том же месте, что и входное изображение
output.save(output_img)

7. MemoryMate (напоминание о задачах и сроках)
В процессе погружения в работу мне часто приходится удерживать в памяти важные задачи. Чтобы решить эту проблему и повысить свою продуктивность, я разработал Python-скрипт MemoryMate, который служит мне цифровым помощником для запоминания. Через определенный промежуток времени он отправляет мне пользовательские сообщения с напоминаниями, чтобы я вовремя выполнял свои задачи. MemoryMate значительно повысил мою продуктивность и помог мне стабильно укладываться в сроки. Самое приятное, что этот скрипт прост, легко воспроизводим и невероятно полезен.
from win10toast import ToastNotifier
import time
toaster = ToastNotifier()
def set_reminder():
reminder_header = input("What would you like me to remember?\n")
related_message = input("Related Message:\n")
time_minutes = float(input("In how many minutes?\n"))
time_seconds = time_minutes * 60
print("Setting up reminder...")
time.sleep(2)
print("All set!")
time.sleep(time_seconds)
toaster.show_toast(
title=f"{reminder_header}",
msg=f"{related_message}",
duration=10,
threaded=True
)
while toaster.notification_active():
time.sleep(0.005)
if __name__ == "__main__":
set_reminder()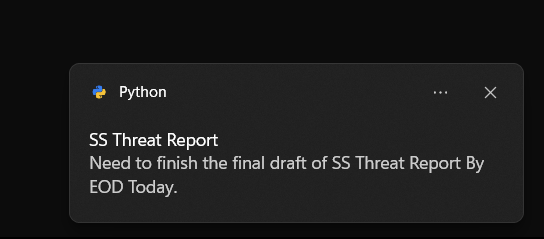
Знаете ли вы, что в Python можно выполнять вычисления с очень большими целыми числами, такими как `999**999`, без ошибок переполнения? Дело в том, что Python автоматически использует для больших чисел тип «big integer» («большое целое число»).
8. MonitorMax
Мониторинг системных ресурсов очень важен для отображения использования различных компонентов компьютерных систем в реальном времени. Это бесценный инструмент для пользователей, системных администраторов и разработчиков, которым необходимо следить за производительностью системы, выявлять узкие места и обеспечивать эффективное управление ресурсами. Этот скрипт автоматизации на Python помогает отслеживать использование CPU, GPU, батареи и памяти, генерируя предупреждения, если использование какого-либо ресурса превысит безопасные пороговые значения.

import psutil
import time
from win10toast import ToastNotifier
# Инициализация объекта ToastNotifier
toaster = ToastNotifier()
# Установка пороговых значений для использования процессора, памяти, GPU и уровня заряда батареи.
cpu_threshold = 40 # Процентный показатель
memory_threshold = 40 # Процентный показатель
gpu_threshold = 40 # Процентный показатель
battery_threshold = 100 # Процентный показатель
# Бесконечный цикл для непрерывного мониторинга системных ресурсов
while True:
try:
# Получение информации о системных ресурсах
cpu_usage = psutil.cpu_percent(interval=1)
memory_usage = psutil.virtual_memory().percent
gpu_usage = psutil.virtual_memory().percent
battery = psutil.sensors_battery()
# Проверка использования CPU
if cpu_usage >= cpu_threshold:
message = f"CPU usage is high: {cpu_usage}%"
toaster.show_toast("Resource Alert", message, duration=10)
# Проверка использования памяти
if memory_usage >= memory_threshold:
message = f"Memory usage is high: {memory_usage}%"
toaster.show_toast("Resource Alert", message, duration=10)
# Проверка использования GPU
if gpu_usage >= gpu_threshold:
message = f"GPU usage is high: {gpu_usage}%"
toaster.show_toast("Resource Alert", message, duration=10)
# Проверка уровня заряда батареи
if battery is not None and battery.percent <= battery_threshold and not battery.power_plugged:
message = f"Battery level is low: {battery.percent}%"
toaster.show_toast("Battery Alert", message, duration=10)
# Подождите 5 минут, прежде чем снова проверять ресурсы.
time.sleep(300)
except Exception as e:
print("An error occurred:", str(e))
break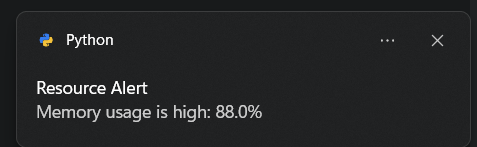
Применение скрипта
MonitorMax можно использовать в повседневных сценариях, таких как игры, запуск локального сервера, локальное глубокое обучение модели и т. д. Отслеживая все ресурсы, вы всегда будете знать, используют ли ваши сценарии или задачи оптимальное количество памяти, и если это не так, сможете оптимизировать их соответствующим образом. Панель мониторинга ресурсов можно создать с помощью Tkinter, чтобы получить график ресурсов в реальном времени, похожий на панель задач, с добавлением уведомлений и звуковых предупреждений о высоком уровне использования памяти.
9. EmailBlitz (мгновенная обработка email-рассылки)
Обработка массовой email-рассылки — будь то маркетинговая кампания, информационные письма или организационные обновления — может оказаться сложной задачей. Этот скрипт автоматизации на Python облегчит ее, позволяя без особых усилий отправлять массовые электронные письма. Он упрощает процесс коммуникации, позволяя охватить большую группу получателей одновременно и обеспечивая своевременную и эффективную доставку сообщений. Скрипт EmailBlitz идеально подходит для маркетологов, администраторов и всех, кому нужно отправлять множество писем. Он повышает производительность, экономит время и помогает сохранить индивидуальный подход в общении.
import smtplib
from email.message import EmailMessage
import pandas as pd
def send_email(remail, rsubject, rcontent):
email = EmailMessage() ## Создание объекта для EmailMessage
email['from'] = 'The Pythoneer Here' ## Отправитель
email['to'] = remail ## Получатель
email['subject'] = rsubject ## Тема письма
email.set_content(rcontent) ## Содержание письма
with smtplib.SMTP(host='smtp.gmail.com',port=587)as smtp:
smtp.ehlo() ## Объект сервера
smtp.starttls() ## используется для передачи данных между сервером и клиентом
smtp.login(SENDER_EMAIL,SENDER_PSWRD) ## Логин и пароль gmail
smtp.send_message(email) ## Отправка письма
print("email send to ",remail) ## Вывод сообщения об успешном выполнении
if __name__ == '__main__':
df = pd.read_excel('list.xlsx')
length = len(df)+1
for index, item in df.iterrows():
email = item[0]
subject = item[1]
content = item[2]
send_email(email,subject,content)10. ClipSaver (сохранение скопированных фрагментов)
Согласитесь, при манипулировании многими текстовыми фрагментами легко утратить представление о том, что вы скопировали. Хорошо бы иметь инструмент, который отслеживает все, что вы копируете в течение дня. ClipSaver — скрипт автоматизации на Python, который делает именно это. Он отслеживает все, что вы копируете, и сохраняет каждый фрагмент текста в удобном графическом интерфейсе. С ним вам не придется искать скопированный фрагмент по бесконечным вкладкам и рисковать потерей ценной информации — этот скрипт сохраняет все необходимое в упорядоченном и легкодоступном виде.
import tkinter as tk
from tkinter import ttk
import pyperclip
def update_listbox():
new_item = pyperclip.paste()
if new_item not in X:
X.append(new_item)
listbox.insert(tk.END, new_item)
listbox.insert(tk.END, "----------------------")
listbox.yview(tk.END)
root.after(1000, update_listbox)
def copy_to_clipboard(event):
selected_item = listbox.get(listbox.curselection())
if selected_item:
pyperclip.copy(selected_item)
X = []
root = tk.Tk()
root.title("Clipboard Manager")
root.geometry("500x500")
root.configure(bg="#f0f0f0")
frame = tk.Frame(root, bg="#f0f0f0")
frame.pack(padx=10, pady=10)
label = tk.Label(frame, text="Clipboard Contents:", bg="#f0f0f0")
label.grid(row=0, column=0)
scrollbar = tk.Scrollbar(root)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
listbox = tk.Listbox(root, width=150, height=150, yscrollcommand=scrollbar.set)
listbox.pack(pady=10)
scrollbar.config(command=listbox.yview)
update_listbox()
listbox.bind("<Double-Button-1>", copy_to_clipboard)
root.mainloop()
Знаете ли вы, что расширение .py не имеет большого значения при сохранении файлов кода?
Используйте любое расширение для сохранения Python-файлов, будь то .cow, .cat или .mango. Если ваш скрипт корректен, он будет запущен и выдаст ожидаемый результат.
11. BriefBot (резюмирование статей)
Я ежедневно читаю статьи, научные работы, новостные публикации и знаю, что у многих есть эта привычка. Однако найти время на чтение полных статей бывает непросто. BriefBot — скрипт автоматизации на Python, который решает эту проблему, используя нейронные сети для создания быстрых резюме. Он использует веб-скрейпинг для извлечения содержимого статьи и передает его в предварительно обученную модель, которая создает краткое резюме, экономя время на узнавание новой информации.
from transformers import BartForConditionalGeneration, BartTokenizer
import requests
from bs4 import BeautifulSoup
## Функция резюмирования статьи
def summarize_article(article_text, max_length=150):
model_name = "facebook/bart-large-cnn"
tokenizer = BartTokenizer.from_pretrained(model_name)
model = BartForConditionalGeneration.from_pretrained(model_name)
inputs = tokenizer.encode("summarize: " + article_text, return_tensors="pt", max_length=1024, truncation=True)
summary_ids = model.generate(inputs, max_length=max_length, min_length=50, length_penalty=2.0, num_beams=4, early_stopping=True)
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
return summary
## Функция для скрейпинга содержимого статьи
def scrape_webpage(url):
try:
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
all_text = soup.get_text(separator='\n', strip=True)
return all_text
except requests.exceptions.RequestException as e:
print(f"Error: {e}")
return None
if __name__ == "__main__":
webpage_url = "https://www.bleepingcomputer.com/news/security/meet-brain-cipher-the-new-ransomware-behind-indonesia-data-center-attack/" ## Образец URL для тестирования скрипта
webpage_text = scrape_webpage(webpage_url)
if webpage_text:
summary = summarize_article(webpage_text)
print("\nSummarized Article:")
print(summary)
else:
print("Webpage scraping failed.")12. SpellGuard (корректура текстов)
Как бы хорошо вы ни владели английским языком, нельзя избежать орфографических и грамматических ошибок при написании объемных отчетов, статей или научных работ. В эпоху искусственного интеллекта многие мощные пакеты Python помогают исправить эти ошибки, обеспечив тщательную корректуру письменных текстов. SpellGuard — Python-скрипт, который использует искусственный интеллект для обнаружения и исправления орфографических и грамматических ошибок. Он обеспечит вашим письменным высказываниям ясность, точность и профессионализм.
## Установка библиотеки
!pip install lmproof
## Импорт библиотеки
import lmproof as lm
## Функция корректуры
def Proofread(text):
proof = lm.load("en")
error_free_text = proof.proofread(text)
return error_free_text
## Образец текста
TEXT = '' ## Здесь размещается образец текста
## Вызов функции
Print(Proofread(TEXT))
13. LinkStatus (контролирование статуса ссылок)
Собственный блог — мечта многих авторов. Для поддержания профессионального и удобного блога важно, чтобы все ссылки в нем функционировали должным образом. Неработающие ссылки могут разочаровать читателей и подорвать доверие к сайту. LinkStatus — скрипт автоматизации на Python, который позволяет легко проверить веб-соединение нескольких URL-адресов. Регулярно контролируя URL-адреса, этот скрипт гарантирует актуальность и функциональность ваших ссылок, что повышает надежность сайта и удобство работы с ним.
import csv
import requests
import pprint
def get_status(website):
try:
status = requests.get(website).status_code
return "Working" if status == 200 else "Error 404"
except:
return "Connection Failed!!"
def main():
with open("sites.txt", "r") as fr:
websites = [line.strip() for line in fr]
web_status_dict = {website: get_status(website) for website in websites}
pprint.pprint(web_status_dict)
# Запись результатов в файл CSV
with open("web_status.csv", "w", newline='') as csvfile:
fieldnames = ["Website", "Status"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for website, status in web_status_dict.items():
writer.writerow({"Website": website, "Status": status})
print("Data Uploaded to CSV File!!")
if __name__ == "__main__":
main()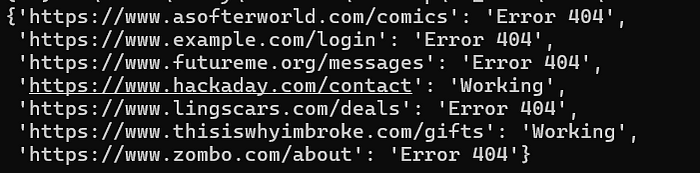
А вы знали, что можно использовать китайские строки в качестве имен переменных в Python?
Например: 金竹戈女日 = «Hello World!».
14. DailyDigest (сбор трендовых новостей)
Быть в курсе последних событий, происходящих в вашем городе, регионе, стране или мире, очень важно, но плотный график часто не позволяет выделить время на чтение новостей. DailyDigest — скрипт автоматизации, решающий данную проблему: он извлекает трендовые новости из Google News и зачитывает их вслух. DailyDigest гарантирует, что вы всегда и везде будете в курсе последних новостей без особых усилий.
import pyttsx3
import requests
engine = pyttsx3.init('sapi5')
voices = engine.getProperty('voices')
engine.setProperty('voice', voices[0].id)
def speak(audio):
engine.say(audio)
engine.runAndWait()
def trndnews():
url = " http://newsapi.org/v2/top-headlines?country=us&apiKey=GET_YOUR_OWN"
page = requests.get(url).json()
article = page["articles"]
results = []
for ar in article:
results.append(ar["title"])
for i in range(len(results)):
print(i + 1, results[i])
speak(results)
trndnews()
''' Run The Script To Get The Top Headlines From USA'''15. QRGenie (генерирование QR-кодов)
Популярность QR-кодов резко возросла с использованием их для отправки и получения платежей. Сегодня они часто применяются в социальных сетях для обмена ссылками, секретными сообщениями, кодами купонов и многим другим. Этот скрипт автоматизации на Python поможет создавать персонализированные QR-коды с выбранными вами данными, что позволит без труда делиться информацией и впечатлять свою аудиторию.
import qrcode
def generate_qr_code(link, filename):
"""Generates a QR code for the given link and saves it as filename."""
qr = qrcode.QRCode(
version=1,
error_correction=qrcode.constants.ERROR_CORRECT_L,
box_size=10,
border=4,
)
qr.add_data(link)
qr.make(fit=True)
img = qr.make_image(fill_color="black", back_color="white")
img.save("profile.png")
if __name__ == "__main__":
generate_qr_code("https://abhayparashar31.medium.com/", "Profile.png")
print(f"QR code saved successfully!!")
16. ShrinkLink (сокращение длинных URL-адресов)
Я ежедневно работаю с множеством ссылок: одни из них храню, другими делюсь со своими читателями. Больше всего в URL-адресах мне не нравится их длина, которая может раздражать и затруднять чтение. Скрипт автоматизации ShrinkLink эффективно решает эту проблему, используя внешний API для преобразования длинных URL в короткие, удобные для чтения ссылки.
import pyshorteners
def generate_short_url(long_url):
s = pyshorteners.Shortener()
return s.tinyurl.short(long_url)
long_url = input('Paste Long URl \n')
short_url = generate_short_url(long_url)
print(short_url)
17. CaptureIt (запись видео с экрана)
Кем бы вы ни были — геймером, инфлюенсером, художником или разработчиком, — программное обеспечение для записи видео с экрана компьютера необходимо для фиксации вашей деятельности. Однако многие существующие решения являются дорогостоящими или накладывают ограничения, такие как водяные знаки и временные рамки. Этот скрипт автоматизации на Python предлагает простое решение для записи экрана без водяных знаков и ограничений по времени, а также с настраиваемыми параметрами окна экрана.
import cv2
import numpy as np
import pyautogui
SCREEN_SIZE = tuple(pyautogui.size())
fourcc = cv2.VideoWriter_fourcc('M','J','P','G')
fps = 12.0
record_seconds = 20
out = cv2.VideoWriter("video.mp4", fourcc, fps, SCREEN_SIZE)
for _ in range(int(record_seconds * fps)):
img = pyautogui.screenshot(region=(0, 0, 500, 900))
frame = np.array(img)
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
out.write(frame)
cv2.imshow("video frame", frame)
if cv2.waitKey(1) == ord("q"):
break
cv2.destroyAllWindows()
out.release()Бонус: H2OReminder (напоминание о приеме воды)
Этот скрипт автоматизации представляет собой простую, но мощную программу, предназначенную для напоминания пользователям о необходимости регулярно пить воду. Это бесценный инструмент для тех, кто проводит много часов за компьютером или имеет плотный график, в результате чего может забыть выпить достаточное количество воды. Скрипт H2OReminder способствует формированию здоровых привычек, поощряя регулярное потребление воды, что необходимо для поддержания общего здоровья и хорошего самочувствия.
import time
from plyer import notification
if __name__ == "__main__":
while True:
notification.notify(
title="Please Drink Water",
message="The U.S. National Academies of Sciences, Engineering, and Medicine determined that an adequate daily fluid intake is: About 15.5 cups (3.7 liters) of fluids a day for men. About 11.5 cups (2.7 liters) of fluids a day for women. Keep Drinking Water !!!",
app_icon="./Desktop-drinkWater-Notification/icon.ico",
timeout=12
)
time.sleep(1800) ## Вносите изменения в зависимости от перерывов на выпивание воды!!!Читайте также:
- 10 примеров для изучения модуля JSON в Python
- Опыт работы с Python в течение 2 лет: уроки и рекомендации
- 7 лучших CLI-библиотек Python в 2023 году
Читайте нас в Telegram, VK и Дзен
Перевод статьи Abhay Parashar: 17 Mindblowing Python Automation Scripts I Use Everyday





